研究方法
Table of Contents

1. 研究的起點:提問與假設
- 「大部份一看就很厲害的題目」,通常都做不出來
- 「一看就知道做得出來的題目」,通常都很無聊
1.1. 什麼是「研究問題」?
- 定義:一個具體、明確,且能透過觀察或實驗來回答的問題。
- 特徵:
- 明確:有清楚的主詞與行為
- 可測量:能被觀察、量化或分類
- 有意義:值得探索並可得出結論
- 明確:有清楚的主詞與行為
例子比較:
- 「生命的意義是什麼?」(哲學問題,不可驗證)
- 「不同睡眠時間對記憶力的影響是什麼?」(可操作的研究問題)
1.2. 可驗證的假設 vs. 不可驗證的想法
- 假設(Hypothesis):對某種現象的預測性說法,可經由實驗驗證。
| 類型 | 說明 | 例子 |
|---|---|---|
| 可驗證的假設 | 可以透過實驗或觀察檢驗 | 每天喝咖啡的人反應速度較快 |
| 不可驗證的想法 | 無法測量,主觀性太強 | 咖啡是一種比較高尚的飲品 |
1.3. 變數的基本概念
- 自變數(操弄變數):研究者主動控制的變因 → 例:是否喝咖啡
- 因變數(結果變數):觀察或測量的結果 → 例:反應時間
- 控制變數:為排除干擾而固定的條件 → 例:實驗環境、睡眠時間
1.4. 練習:將日常疑問轉換成假設
| 生活說法 | 研究問題 | 假設 |
|---|---|---|
| 喝牛奶會長高 | 牛奶攝取量是否影響青少年身高? | 每天喝 300ml 牛奶的青少年,其身高增加速度較高。 |
| 打遊戲讓人變笨 | 長時間玩遊戲是否影響專注力? | 每天玩超過 3 小時遊戲的學生,其注意力測驗得分較低。 |
1.5. 例子:你認為「每天喝咖啡的人反應速度較快」這個說法,如何設計一個實驗來驗證?
- 研究問題:喝咖啡是否提升清醒程度?
- 假設:喝咖啡的組別,其反應速度比沒喝咖啡者快。
- 自變數:是否喝咖啡(有 / 無)
- 因變數:反應時間、清醒度問卷得分
- 控制變數:咖啡劑量、測試時間、睡眠時數等
1.6. 去哪裡找想法
- 歷屆科展
- 大量閱讀論文
- 和教師討論(別找我)
- 和同學畫唬爛
- 現實生活觀察
- 作夢夢到
- re-search
1.7. 找到一個新題目太難(部份創新)
創新的能力來自蒐集進一步的證據,提出更可靠(改良)的答案或解決方案
- 新場域: 拿現有題目/方法應用於新場域
- 新理論: 原來的題目用新理論來解釋
- 新資料: 原來的題目應用新資料來看結果是否相同
- 新方法: 原來的題目應用新方法
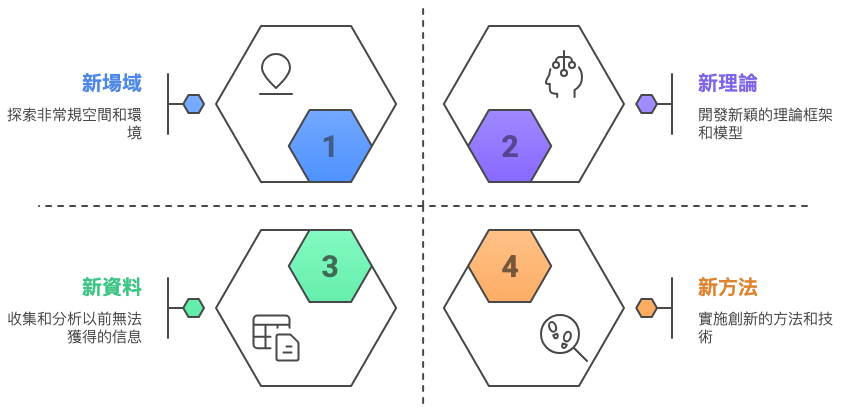
Figure 1: 部份創新的幾種方法
1.7.1. 例1: 新領域
1.7.1.1. 原來技術
聽到這段前奏

立即猜出歌名

其產品如:

Figure 2: Shazam

Figure 3: SoundHound
基本上就是利用一段連續聲波的前面幾秒內容預測出這是哪首音樂的完整聲波波形,這種技術可以應用到什麼新領域?
1.7.1.2. 新領域
下圖是某個地震波的波形1,你現在會做地震預測了嗎?
1.7.2. 例2: 新領域
1.7.2.1. 原來技術
- Google Trends
Figure 4: Google Trends
Google Trends 是由 Google 提供的線上工具,用於分析和顯示特定搜索關鍵字在不同時間和地區的相對搜索量。這個工具能夠幫助用戶了解和追踪全球各地的搜索趨勢。主要功能:
- 關鍵字趨勢分析:
- 輸入一個或多個關鍵字,可以查看這些關鍵字在指定時間範圍內的搜索熱度變化。
- 圖表展示搜索熱度的變化趨勢,使用戶直觀地看到關鍵字的流行程度隨時間的變化。
- 輸入一個或多個關鍵字,可以查看這些關鍵字在指定時間範圍內的搜索熱度變化。
- 地區分析:
- 查看特定關鍵字在不同國家、地區或城市的搜索熱度分佈。
- 通過地圖視圖,直觀了解關鍵字在全球各地的受歡迎程度。
- 查看特定關鍵字在不同國家、地區或城市的搜索熱度分佈。
- 比較多個關鍵字:
- 同時輸入多個關鍵字,比較它們的搜索熱度。
- 圖表顯示多個關鍵字的趨勢線,幫助用戶發現它們之間的相對流行度。
- 同時輸入多個關鍵字,比較它們的搜索熱度。
- 相關查詢和主題:
- 查看與輸入關鍵字相關的其他熱門搜索詞和主題。
- 了解用戶在搜索某個關鍵字時,還搜索了哪些相關內容。
- 查看與輸入關鍵字相關的其他熱門搜索詞和主題。
- 按類別過濾:
- 按特定類別(如健康、科技、娛樂等)過濾搜索資料,以獲取更具體的結果。
- 按特定類別(如健康、科技、娛樂等)過濾搜索資料,以獲取更具體的結果。
- 時間範圍調整:
- 用戶可以選擇特定的時間範圍(如過去一小時、過去一天、過去一年或2004年至今)來查看搜索趨勢。
- 靈活的時間設置幫助用戶了解短期和長期的搜索趨勢變化。
- 用戶可以選擇特定的時間範圍(如過去一小時、過去一天、過去一年或2004年至今)來查看搜索趨勢。
- 即時資料:
- 查看幾乎即時的搜索資料,以了解當前的熱門話題和突發事件的搜索趨勢。
- 查看幾乎即時的搜索資料,以了解當前的熱門話題和突發事件的搜索趨勢。
- 關鍵字趨勢分析:
- 使用場景
- 市場研究:企業和行銷人員可以使用 Google Trends 分析消費者興趣和行為,制定更有效的市場策略。
- 內容創作:內容創作者和部落客可以使用該工具尋找熱門話題,優化內容以吸引更多讀者和觀眾。
- SEO 優化:SEO 專家可以利用搜索趨勢資料,選擇合適的關鍵字進行優化,提高網站在搜索引擎中的排名。
- 學術研究:研究人員可以使用 Google Trends 分析社會行為和趨勢,為學術研究提供資料支持。
- 新聞報導:記者和媒體可以通過該工具了解當前熱門話題和事件,更好地報導新聞。
- 市場研究:企業和行銷人員可以使用 Google Trends 分析消費者興趣和行為,制定更有效的市場策略。
1.7.2.2. 新領域
2008年11月谷歌公司啟動的gft專案,目標是預測美國疾控中心(CDC)報告的流感發病率。甫一登場,gft就亮出十分驚艷的成績單。2009年,gft團隊在《自然》發文報告,只需分析數十億搜尋中45個與流感相關的關鍵詞,gft就能比cdc提前兩周預報2007-2008季流感的發病率2。如圖5,Google Trends使用搜尋資料來追蹤和預測美國和世界各地的流感結果3。
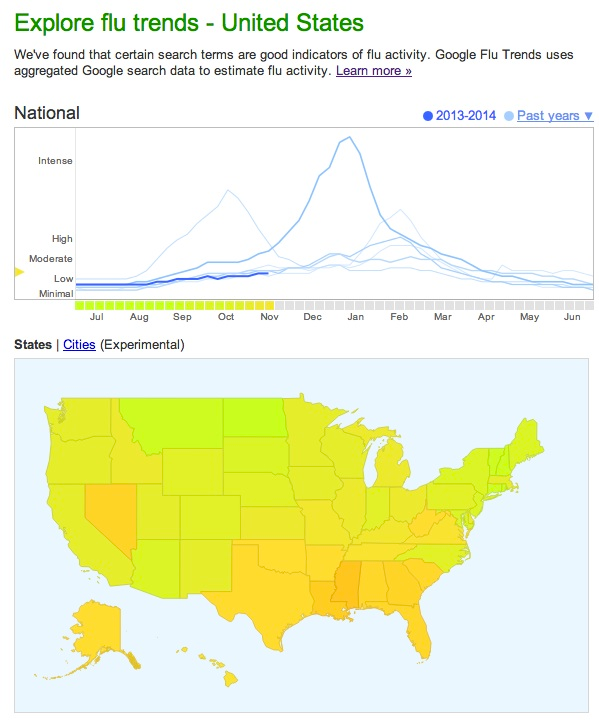
Figure 5: Google flu trends
2014年, lazer等學者在《科學》發文報告了gft近年的表現。2009年,gft沒有能預測到非季節性流感a-h1n1;從2011年8月到2013年8月的108周里,gft有100周高估了cdc報告的流感發病率。高估有多高呢?在2011-2012季,gft預測的發病率是cdc報告值的1.5倍多;而到了2012-2013季,gft流感發病率已經是cdc報告值的雙倍多了2,如下圖4。
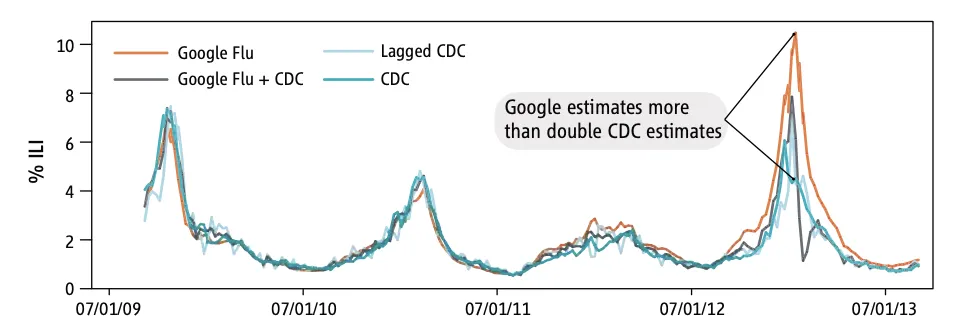
2013年,谷歌調整了gft的演算法,並回應稱出現偏差的罪魁禍首是媒體對gft的大幅報導導致人們的搜尋行為發生了變化。
1.7.3. 例3: 新資料
用手機 GPS 資料分析民眾移動模式
- 原本資料:問卷或人口普查資料。
- 新資料:手機定位資料或交通感測器蒐集到的匿名 GPS 資料。
- 應用:疫情期間政府可利用這類資料分析群聚區域、推估防疫政策的實施效果。
1.7.4. 例4:新資料
用社群媒體資料預測選舉結果
- 原資料:傳統民調。
- 新資料:Twitter、Facebook 或 PTT 上的討論趨勢、情緒分析結果。
- 挑戰與意義:雖然存在雜訊,但結合時間序列與詞頻分析,有時比民調更早發現民意波動。
1.7.5. 例5: 新理論/新方法
- 探討主題: 調漲基本工資是否會導致弱勢勞工失業
- 卡德與克魯格利用新澤西和賓夕法尼亞州在不同時間點上調漲最低工資的情況進行實驗研究5。
- 1982年,Brown, Charles, Curtis Gilroy, and Andrew Kohen以新古典模型(Neoclassical Model)預測,調漲最低工資會導致勞動力需求減少,從而導致失業增加,特別是對於技能較低的勞工6。
- 2006年,Neumark, David, and William Wascher以彈性分析(Elasticity Analysis)對同一主題進行研究,通過分析工資彈性和就業彈性,研究最低工資對不同勞動力群體(如青少年、低技能工人)的影響,結果發現最低工資增加對青少年和低技能工人的就業有負面影響,但程度較小7。
- 2010年,Dube, Arindrajit, T. William Lester, and Michael Reich以現代實證研究(Modern Empirical Studies)最低工資對就業的影響(比較鄰近但在不同最低工資政策下的縣市),結果發現最低工資的增加對低薪工人的就業影響微乎其微,或在某些情況下是正面的8。
- 2016年,Meer, Jonathan, and Jeremy West以動態調整模型(Dynamic Adjustment Models)研究最低工資對就業的長期動態影響,而不僅僅是靜態的短期影響,結果:發現最低工資提高會減緩就業增長,但不會立即導致大規模失業9。
1.7.6. 例6: 新方法
以機器學習重新預測學生學業表現
- 原方法:傳統用迴歸或 t 檢定分析學生成績與背景因素關係。
- 新方法:利用隨機森林、神經網路等 ML 模型,以更高維度、非線性方式預測學生表現與學習成效。
- 結果:有助於早期預測學習落後學生,提供個別化介入策略。
1.7.7. 例7:新方法
以自然語言處理(NLP)分析歷史文本
- 原方法:人工標註、分析史料或文獻。
- 新方法:利用 NLP 對大量文本進行情緒分析、主題建模(topic modeling),分析歷史語境下的輿論變化。
- 應用:像是追蹤報紙中某議題(如婦女參政)的情感傾向變化。
1.7.8. 例8: 新方法
傳統以機械減震系統避免攝影震動
結合生物與資訊科技的創新穏定器: 終極相雞
1.7.9. 例9: 新場域+新方法:
利用深度學習與影像處理技術改善黑白影片色彩化
1.7.10. 部份創新的前提
- 對技術有基本理解
- 對新領域有基本理解
- 換句話說:多讀書才有資格談創新
1.8. 如果你覺得你的題目沒價值
每個想法都有其意義,端看其應用場域(應該啦),就好像一瓶水在不同地點賣不同價格。如果你覺得你這個人沒什麼價值,可能你站錯地點;而如果你覺得你的idea沒什麼用
- 有可能是你找錯應用領域
- 有可能是你用錯方法
- 有可能是你找錯指導老師
- 更有可能是…這個idea真的沒價值…re-search
1.9. 什麼是合適的論文(如何修訂題目)
- worth of reading
- 多讀幾篇論文就知道什麼是合適的論文
1.9.1. 什麼是爛題目
1.9.1.1. 生命的意義是什麼
- 問題太大
- 這個問題從古希臘時代所有的哲學家都在回答,但是沒有人同意其他人的回答
- 只有最自大無知的人才會恬不知恥且有自信的回答你「生命的意義在創造宇宙繼起之生命」
1.9.2. 論文題目的修訂
1.9.2.1. 例1:
- 為什麼會發生工業革命?
- 為什麼臺灣會有高速工業化?
- 日治時期的銀行網路對臺灣戰後工業化有什麼影響?
1.9.2.2. 例2:
- 手機對高中生的影響
- 手機使用時間對高中生的影響
- 手機使用時間長度對高中生學業成就的影響
2. 文獻探討與研究基礎
2.1. 什麼是文獻探討?
- 文獻探討(Literature Review)是研究者在開始研究前,對**已有研究與理論的整理與分析**
- 目的是了解:這個問題別人已經做過哪些研究?研究結果一致嗎?還有沒有尚未探討的部分?
2.2. 為什麼要讀文獻
- 1958年美蘇打了三次太空競賽,前兩次蘇俄勝出,因為他們找了100個數學家,讓他們找出三個比他們聰明的數學家,重新定義問題,提出方法;美國第三次勝出的關鍵是斥鉅資(美國國會圖書館)把所有和太空技術有關的paper全部整理出摘要,然後發現許多所需要的solution已經發表在paper中
- 用別人的智慧解決自己的問題,站在巨人的肩膀上,往前跳一步都是創新,把你的聰明才智放在最後那一步
- 累積基礎知識、看文獻只是為了爬到巨人的肩膀
- 人的聰明程度差異不太大,但是用的方法效率差異很大
- 知識經濟時代最重要的不是發揮自己的能力,而是應用別人的能力;台灣首富是郭台銘,但他不是最聰明的人,他會用最聰明的人;台灣最聰明的人可能在台大,但是台大都是窮教授,因為他們只會用自己的智慧
2.3. 文獻探討的目的
- 了解現有成果:避免重複他人研究,建立理論基礎
- 支持假設建立:根據前人觀點推導出自己的研究假設
- 確認研究空白:找到前人沒處理或結果不一致的地方
- 設計研究方法:參考他人使用的測量工具或變數設計
2.4. 找paper的原則與工具
可使用 AI 工具(如 ChatGPT)整理研究摘要與爭點對比

2.4.1. 找論文的原則
- 第一次用的關鍵字找到可能相關的第一批paper,從第一批paper中找出更精確的關鍵字,再搜尋第二批paper
- 找到目標paper,由其中的reference paper往外延伸到其他相關paper
- 找到作者: 依由作者其他paper往外延伸
2.4.2. Google
- Google 關鍵字 filetype:pdf
- Google scholar
- Google Advanced Search
- Google Image Search
- Google Book Search
2.4.3. 博碩士論文知識加值系統
- 博碩士論文網: 基於學位授予法,國家圖書館為國內唯一博碩士論文法定寄存圖書館
- 登入會員的優點: SDI、記錄檢索歷史、線上問卷服務
- 系統裡的所有論文幾乎都能在Google找到,可以加限縮(主題 ndlpd)
- 找到一篇論文後,由引用論文延伸擴散繼續搜尋(可由被引用數、被點閱數、被下載數來觀察各論文的人氣指數),再由排序順序來找到可以優先查看的其他論文
- 輸出管理: 可以輸出書目APA格式或RIS格式
- 我的研究室: 可以看歷史查詢記錄
- 物聯網 運算
2.4.4. ResearchGate
ResearchGate 是一個專為科學家和研究人員設計的社交網絡平台。它的主要用途包括:
- 分享和發現研究成果:研究人員可以在平台上上傳自己的論文、文章、書籍和其他研究材料,並與全球的同行分享。
- 互動和合作:ResearchGate 提供了討論區和問答功能,研究人員可以在這裡討論研究問題、尋求建議,並尋找合作夥伴。
- 研究影響力:平台會追蹤研究材料的下載和引用次數,幫助研究人員了解他們的研究影響力和受歡迎程度。
- 資源和工具:ResearchGate 還提供了各種工具和資源,幫助研究人員進行資料分析、尋找工作機會和了解最新的研究趨勢。
- 個人資料和網絡:用戶可以創建個人學術檔案,展示他們的研究歷史和專業背景,並擴展他們的專業網絡。
- 期刊上找不到PDF的論文可以試著直接跟原作者要
Figure 6: ResearchGate
2.4.5. ProQuest
- 使用方式參考圖No description for this link
ProQuest 是一家提供全球學術研究和教育支持的公司,擁有多個數字資料庫和信息服務。以下是 ProQuest 的主要定位和功能:
- 多學科資料庫:ProQuest 提供廣泛的多學科資料庫,包括人文、社會科學、醫學、工程、科學技術等各個領域的學術期刊、論文、書籍、報紙、雜誌等資料。
- 學術論文和研究文獻:ProQuest 收錄了大量的博士論文、碩士論文和學術研究報告,為研究人員提供豐富的原始資料來源。
- 專題資料庫:ProQuest 提供專門針對某些領域的資料庫,如商業、法律、教育、藝術和人文學科等,滿足不同學科研究的需求。
- 全文檢索和獲取:用戶可以通過 ProQuest 的強大搜索引擎,檢索和獲取全文資料,並且可以按需下載或在線閱讀。
- 歷史文獻和報紙檔案:ProQuest 也包含大量歷史文獻和報紙檔案,提供了豐富的歷史研究資源,適合歷史學者和研究人員使用。
- 圖書和電子書:除了期刊和論文,ProQuest 還提供大量的電子書和圖書資源,方便用戶進行多樣化的學術研究。
- 教育和學術支持:ProQuest 為教育機構、圖書館和研究機構提供支持,幫助他們有效管理和利用數字資源,並提供培訓和技術支持。
ProQuest 在學術研究和教育領域中扮演著重要角色,通過其全面的資料庫和信息服務,為全球研究人員和學生提供豐富的資源和支持。
2.4.6. EBSCO
- 使用方式參考圖No description for this link
EBSCO 是一家提供信息資源和服務的公司,專注於支持學術研究、教育和企業的需求。以下是 EBSCO 的主要定位和功能:
- 多學科資料庫:EBSCO 提供多種資料庫,涵蓋各種學科領域,如人文、社會科學、醫學、科學技術、教育等,為研究人員和學生提供豐富的學術資源。
- 全文檢索和獲取:EBSCO 提供強大的搜索引擎,用戶可以方便地檢索到期刊文章、書籍、報紙、雜誌等資料,並獲取全文內容。
- 專題資料庫:EBSCO 有針對特定學科或主題的專門資料庫,如 Business Source Complete(商業資料庫)、CINAHL(護理和健康資料庫)、ERIC(教育資料庫)等,滿足特定領域的研究需求。
- 電子書和電子期刊:EBSCOhost 提供大量電子書和電子期刊,供用戶在線閱讀和下載,擴展了傳統圖書館的資源。
- 歷史文獻和檔案:EBSCO 也收錄大量的歷史文獻和檔案資料,支持歷史研究和學術探討。
- 教育支持和教學資源:EBSCO 為教育機構提供教學資源和課程支持,包括教師用的教學材料和學生用的學習資源,幫助提升教育質量。
- 圖書館管理服務:EBSCO 為圖書館提供管理服務,幫助圖書館有效管理其數字資源,並提供技術支持和培訓。
- 個性化服務和工具:EBSCO 提供個性化的研究工具,如文獻管理、書籤、標注等功能,幫助用戶更有效地進行研究和學習。
EBSCO 的目標是通過提供全面的學術資源和先進的技術支持,促進全球學術研究和教育的發展。
2.4.7. ProQuest v.s. EBSCO
ProQuest 和 EBSCO 是兩個主要的學術資源和信息服務提供商,雖然它們在許多方面有相似之處,但也有一些顯著的差異。以下是它們的比較:
2.4.7.1. 相似之處
- 多學科資料庫:兩者都提供涵蓋各種學科領域的多學科資料庫,如人文、社會科學、醫學、科學技術和教育等。
- 全文檢索和獲取:兩者都提供強大的全文檢索和獲取功能,用戶可以方便地檢索到期刊文章、書籍、報紙、雜誌等資料,並獲取全文內容。
- 專題資料庫:ProQuest 和 EBSCO 都有針對特定學科或主題的專門資料庫,滿足特定領域的研究需求。
2.4.7.2. 差異之處
- 資料庫範圍和專業化:ProQuest:其資料庫範圍廣泛,包括博士論文和碩士論文、歷史文獻和報紙檔案等,特別擅長於人文社會科學和商業領域的資料。
- EBSCO:除了學術期刊和書籍外,EBSCO 也提供大量的電子書、歷史文獻和檔案資料,並且在護理和健康資料庫(如 CINAHL)方面有顯著的優勢。
- 教育支持和教學資源:EBSCO:提供更多的教育支持和教學資源,如教師用的教學材料和學生用的學習資源,幫助提升教育質量。
- ProQuest:更多專注於學術研究支持,提供專業的研究工具和資源,但在教學資源方面不如 EBSCO 廣泛。
- 技術和服務:ProQuest:提供高級的資料管理和研究工具,如 RefWorks,用於文獻管理和引用。EBSCO:提供個性化的研究工具,如文獻管理、書籤、標注等功能,並且在圖書館管理服務方面提供更多技術支持和培訓。
- 電子書和電子期刊:EBSCO:擁有大量的電子書和電子期刊,特別是教育和醫學領域的電子資源。
- ProQuest:也提供電子書和電子期刊,但其強項在於傳統期刊和學位論文。
2.4.7.3. 結論
ProQuest 和 EBSCO 都是優秀的學術資源平台,各有優勢。ProQuest 更適合需要廣泛學術論文和歷史檔案的用戶,而 EBSCO 則在教育支持和健康科學資料庫方面有顯著優勢。選擇哪一個平台應根據具體的研究需求和學科領域來決定。
2.4.8. Papers With Code
Papers With Code 是一個專注於將學術論文與其對應的代碼資源相結合的平台。它的主要定位和功能如下:
- 學術論文與代碼的結合:該平台收集了大量的機器學習和人工智慧領域的學術論文,並提供這些論文對應的開源代碼,方便研究人員直接使用和驗證研究結果。
- 方便的搜索和瀏覽:用戶可以通過關鍵詞、研究領域、資料集等多種方式進行搜索,快速找到相關的論文和代碼資源。
- 基準測試和排行榜:平台上還提供了各種基準測試和排行榜,用於比較不同方法在標準資料集上的表現,幫助研究人員了解當前最先進的方法和技術。
- 社區貢獻:研究人員可以上傳自己的論文和代碼,與全球的同行分享他們的研究成果,促進學術交流與合作。
- 資源整合:Paper with Code 也會整合其他相關資源,例如資料集、預訓練模型和教程,為研究人員提供一站式的學習和研究平台。
這個網站在促進學術研究的透明度和可重複性方面發揮了重要作用,使得更多的研究人員能夠方便地訪問和使用最新的研究成果和技術。
2.4.9. PubMed Central
- National Library of Medicince: 美國健康研究院公共資料庫,每天83萬次點擊、160萬篇論文下載
PubMed Central (PMC) 是美國國家生物技術信息中心(NCBI)運營的免費數字存儲庫,專門用於存放生物醫學和生命科學領域的全文期刊文章。它的主要定位和功能如下:
- 免費訪問學術文章:PMC 提供了大量經過同行評審的學術期刊文章的免費全文訪問,支持開放獲取(Open Access)理念,旨在使科學研究更加透明和可用。
- 廣泛的學科覆蓋:該平台涵蓋了生物醫學和生命科學的多個學科,包括醫學、公共衛生、生物學、遺傳學、神經科學等領域,為研究人員、醫療從業者和學生提供豐富的資源。
- 高效的搜索和檢索功能:PMC 提供強大的搜索引擎和檢索工具,用戶可以通過關鍵詞、作者、期刊名稱、出版日期等多種方式快速找到所需的文章。
- 文獻鏈接和引用:平台上的文章通常與其他科學文獻和資料庫(如PubMed、GenBank)相互鏈接,方便用戶進一步查閱相關研究成果和資料。
- 持續更新和存儲:PMC 定期更新,持續增加新的期刊和文章,並確保數字化內容的長期存儲和保存,維持資料的持久可用性。
PubMed Central 在促進科學知識的共享和傳播方面發揮了重要作用,為全球的研究社群提供了一個可靠和便捷的資源平台。
2.5. 讀paper的方法
- 讀論文不是讀課本,不用太在乎細節
- 讀論文要回答的問題: 如何找出一個更好的方法?要思考為什麼某一種方法不能表現更好?
- 所有論文最難懂的是研究方法與實驗設計
- 每次讀一篇paper不用全懂,只針對重要的問題來看,看完要能回答問題,所以是參考,不是全部讀懂
2.5.1. 看不懂paper怎麼辦
如果你看不懂找到的paper: 由淺入深填補背景知識,一般來說,閱讀難度大概是: 期刊論文 > 博士論文 > 課本 > Wikipedia。
如果你看不懂某篇paper,可以依序查看:
- 作者的論文
- 教科書
- 網路教學文
- 知識型的Youtuber
如果還是看不懂,表示這不是你目前該研究的主題
2.5.2. 讀paper的不同境界
如果把讀paper的技能分級,大概有以下幾類
- 低: 讀遍所有相關paper只找到部份idea
- 中: 讀遍所有相關paper找到可用的idea
- 高: 讀挑中的幾篇paper找到可用的idea
2.6. 如何記錄你的想法
- you need a place to store your notes, store the things you find
- 軟體很多,從最簡單的做起: 資料夾
- 最基本的功能: backtrace
- 格式越簡單越原始越好
2.6.1. apps
- Bear Markdown Notes
- Goodnotes
- Notability
- Notion
- Emacs/org-mode
2.6.2. web
- hackmd.io
2.6.3. 雲端硬碟
- Dropbox
- Google Drive
- OneDrive
2.7. 閱讀重點(建議閱讀策略)
- 研究的目的與問題是什麼?
- 他們使用了什麼方法與變數?
- 結果支持什麼樣的結論?
- 是否與其他文獻矛盾或一致?
- 是否有尚未處理的問題?
2.8. 寫作建議
- 依主題分類文獻,例如:
- 支持咖啡提神的研究有哪些?
- 與反應速度無關的研究又有哪些?
- 支持咖啡提神的研究有哪些?
- 可用「有人說 A,也有人說 B,本文將探討…」的語氣呈現矛盾點
- 建議分段敘述不同觀點,不要混在一起
2.9. 範例開頭句式
- 「根據 Smith (2019) 的研究,咖啡因能有效提高注意力與反應速度。」
- 「然而,也有研究指出,咖啡對反應速度的影響因人而異(Lee, 2020)。」
- 「由於現有研究結果並不一致,因此本研究將進一步探討……」
2.10. 虛擬文獻範例
2.10.1. 文獻探討
咖啡因對認知功能的影響已被廣泛研究。根據 Johnson 與 Lee(2018)的實驗研究,受試者在攝取 200 毫克咖啡因後,於反應時間測驗中的表現顯著優於對照組,顯示咖啡因具有促進警覺與加快反應的效果。此外,該研究指出,咖啡因的效果在攝取後 30 分鐘最為顯著,持續約兩小時。
然而,也有研究指出咖啡因的效果可能因個體差異而有所不同。Chang(2020)針對 100 名大學生進行問卷與測試,發現習慣性攝取咖啡者與非咖啡飲用者在反應速度上差異不顯著。作者推測,長期攝取可能導致耐受性上升,使得咖啡的提神效果減弱。此結果與 Johnson 與 Lee(2018)的發現不一致,顯示在進行咖啡與認知效能研究時,需考慮個體飲用習慣的變項。
綜上所述,儘管多數文獻支持咖啡有助於提升反應能力,但也有研究指出效果可能因人而異,仍需進一步研究其影響機制與個體差異因素。
2.10.2. 參考文獻(APA 格式)
- Chang, H. T. (2020). The influence of habitual caffeine consumption on cognitive performance in college students. Journal of Behavioral Neuroscience, 28(3), 145–152. https://doi.org/10.1234/jbn.2020.0032
- Johnson, R. L., & Lee, M. Y. (2018). Acute effects of caffeine on reaction time and alertness. Cognitive Science Quarterly, 14(2), 87–99. https://doi.org/10.5678/csq.2018.0014
2.11. 學生練習建議
- 指定主題搜尋 3~5 篇文獻摘要
- 嘗試整理出共同觀點與差異觀點
- 合作建立一份文獻比較表(可用 Google Sheets)
3. 研究設計
有了研究成果,如何證明其有效
3.1. 什麼是「實驗設計」?
- 實驗設計(Experimental Design)是指:
研究者為了回答一個具體的研究問題,所進行的**有系統的觀察與操弄安排**。 - 目的是在控制條件下,檢驗某個自變數(原因)是否會影響某個依變數(結果)。
- 簡單來說,就是「怎麼安排一個公平的測試,來驗證一個想法」。
科學並不是單純「觀察」,而是設計一個合理的情境,排除干擾後進行有根據的比較。
3.2. 奶茶的故事:從一杯下午茶開始的統計革命10

Figure 7: Tea time
- 時間: 1920 年代的劍橋大學,某個風和日麗的夏天下午,一群人優閒地享受下午茶時光。
起因: 有位女士(生物學家 Muriel Bristol11)說:「沖泡的順序對於奶茶的風味影響很大,把茶加進牛奶裡和把牛奶加進茶裡,這兩種沖泡方式所泡出的奶茶口味截然不同。」,而且她有能嚐出二者差異的超能力。

Figure 8: Muriel Bristol
Fisher 說:
「林北聽妳在唬爛(That’s impossible.)」
「那我們就來設計一個實驗,證明你是否真的具備這種能力吧。」
這便是統計學史上著名的實驗之一,這個實驗成為後來「假設檢定」、「隨機化設計」、「實驗對照」等統計概念的經典範例。

Figure 9: Sir Ronald Aylmer Fisher
- 推手: 化學家 William Roach 為了拍 Muriel Bristol 馬屁,建議做個實驗
- 結果: 現代統計學誕生
- 問題: 如果你是 Fisher,你要怎麼證明 Bristol 是對的或錯的? 實際泡茶? 怎麼泡? 要泡幾杯、讓 Bristol 猜幾杯才能確定 Bristol 的超能力。
- 八卦: 費雪在 1935 年的文章中並沒有告訴我們當時這位女同事到底猜對了幾杯,但根據費雪女兒後來的說法是,這位女同事當時全答對了(Agresti 2002, p.92)。
3.2.1. Fisher的做法:實驗設計
- 這個實驗之所以有名,是因為這是歷史上第一次「隨機對照實驗」。
- 準備 8 杯奶茶:
- 其中 4 杯是先加牛奶後加紅茶
- 4 杯是先加紅茶後加牛奶
- 其中 4 杯是先加牛奶後加紅茶
- 這 8 杯的順序是隨機排列的,女士無從得知哪一杯是什麼順序。
- Fisher 請這位女士從 8 杯茶中,挑出 4 杯她認為是先加牛奶的(「隨機對照實驗」)。
3.2.1.1. 問題
- 這樣的實驗該怎麼設計,才算「公平」?
- 如果她只是「猜對」,我們要怎麼知道不是運氣?
- 如果她連續猜對 8 次,我們應該相信她的能力嗎?
3.2.2. Fisher 的關鍵問題是:
如果這位女士 完全是亂猜的,她有多大的機率會剛好猜對全部 4 杯?
這其實是一個 組合數學與機率問題,我們可以計算出在隨機猜的情況下,她「剛好挑中 4 杯正確的」機率:
- 從 8 杯中挑 4 杯的方法有 \(\binom{8}{4}=70\) 種可能的選法
- 而其中只有 1 種選法是全部猜對的(4 杯都挑對)
- 所以完全亂猜時,全對的機率為:\(\frac{1}{70} \approx 0.0143\)(約 1.43%)
- 到底該怎麼判斷她是不是用猜的呢?費雪的重要貢獻之一,是提出了判斷一個實驗是否有效,必須設定一個機率的上下限,他稱之為「顯著水準(level of significance, \(\alpha\))」,他常常把這個水準訂為 5%。小於 5%的,他就認為可能性可以排除、不考慮。
- 費雪又計算了這位女博士猜對 6 杯的可能性,這種情況是,女士在把奶倒進茶裡的 4 杯當中選了 3 杯,又在把茶倒進奶裡的 4 杯當中選了 1 杯,這種組合的可能性有:4×4=16 種。猜對 6 杯的機率是 16/70 ≈ 22.85%。因為 22.85%大於 5%,所以他認為 6 杯不行,要增加到 8 杯
3.2.3. 統計意涵:
- 虛無假設(Null Hypothesis) \(H_0\) : 女士無法分辨沖泡順序(她只是亂猜)
- 對立假設(Alternative Hypothesis) \(H_1\) : 女士能分辨沖泡順序(有辨識能力)
- 如果女士猜對了全部 4 杯,這種結果在虛無假設下只會出現約 1.43% 的機率,也就是 p-value = 0.0143 → 非常不尋常,Fisher 就有理由拒絕虛無假設,相信她真的有能力。
- Fisher 不會說「這位女士 98.57% 有能力」,他會說:如果她其實沒這種能力,那她猜中 4 杯的機率只有 1.43%,這樣的結果太難以用「亂猜」來解釋了。
- 這就是現代統計學中 假設檢定 (Hypothesis Testing) 的核心概念。
3.2.4. 史上第一個實驗:
公元前6世紀,巴比倫王尼布甲尼撒(Nebuchadnezzar)讓一組人只吃蔬菜、水,另一組吃王膳,來測試健康差異(《但以理書》)12
3.3. 實驗設計的目的:控制變數、排除干擾
- 控制變數(Control Variables):
- 研究者必須控制所有可能影響結果的因素,讓不同組之間唯一的差別就是自變數。
- 例:在「咖啡是否提高反應速度」的實驗中,需控制受試者的睡眠時間、使用設備、測驗時間等。
- 研究者必須控制所有可能影響結果的因素,讓不同組之間唯一的差別就是自變數。
- 排除干擾:
- 干擾(confounding variables)若未控制,會使實驗結果無法解釋是否真由自變數引起。
- 干擾(confounding variables)若未控制,會使實驗結果無法解釋是否真由自變數引起。
3.4. 實驗設計的基本要素
| 要素 | 定義 | 範例(咖啡與反應時間) |
|---|---|---|
| 自變數 | 研究者操弄的變數 | 是否每天喝咖啡 |
| 依變數 | 研究者測量的結果變數 | 反應時間(ms) |
| 控制變數 | 研究者固定不變、避免干擾的潛在變數 | 睡眠時間、測驗環境、使用設備 |
| 控制組 | 不接受操弄(不處理)的參照組 | 不喝咖啡的一組 |
| 實驗組 | 接受操弄(處理)的組別 | 喝咖啡的一組 |
3.5. 實驗設計的類型
- 隨機對照試驗(Randomized Controlled Trial, RCT)
- 將受試者 隨機分派 至實驗組與控制組
- 是最嚴謹、最能推論因果關係的實驗設計方式
- 例:將 30 位學生亂數分為兩組,一組每天喝咖啡,一組不喝,觀察其反應時間差異。
- 將受試者 隨機分派 至實驗組與控制組
- 準實驗設計(Quasi-experimental Design)
- 沒有完全隨機分組,可能因實務限制而採用現有班級或群體
- 可用於教育現場、社會現象等難以完全控制的情境
- 例:使用兩個班級進行不同教學法的比較。
- 沒有完全隨機分組,可能因實務限制而採用現有班級或群體
- 觀察性研究(Observational Study)
- 不操弄變數,只是記錄現有情況或行為
- 雖然較容易進行,但 無法直接推論因果
- 例:調查全校學生每天是否喝咖啡,並記錄他們的反應時間,再進行相關性分析。
- 不操弄變數,只是記錄現有情況或行為
💡 小提醒:
若研究目的為探討「因果關係」,最佳方式是使用隨機對照試驗;若無法操弄變數,可考慮準實驗或觀察性研究。
3.6. 實驗設計示範:每天喝咖啡的人反應速度較快?
3.6.1. 研究問題與假設
- 研究問題:喝咖啡是否會影響人的反應速度?
- 假設(Hypothesis):每天喝咖啡的人,其反應速度顯著快於不喝咖啡的人。
3.6.2. 實驗設計目的
- 控制其他可能影響反應速度的變因(如睡眠、年齡、用藥等)
- 排除干擾,聚焦在「是否喝咖啡」這個變因的效果
3.6.3. 實驗設計基本要素
- 自變數(操弄變數):是否每天喝咖啡(有 / 無)
- 因變數(依變數):反應速度(單位:毫秒)
- 控制變數:測驗時間、測驗環境、參與者年齡與作息
- 實驗對象:20 位高中生,隨機分為兩組,每組各 10 人
- 測量工具:線上反應速度測驗(如按鍵測時反應 App)
3.6.4. 實驗設計類型
- 類型:隨機對照試驗(Randomized Controlled Trial, RCT)
- 實驗組:每天喝 1 杯咖啡,持續 7 天
- 控制組:不喝咖啡,持續 7 天
- 兩組皆在第 8 天早上進行反應速度測試
- 實驗組:每天喝 1 杯咖啡,持續 7 天
3.6.5. 操作化定義與測量方式
- 自變數操作化:
- 「每天喝咖啡」定義為早上 9 點前攝取 200ml 美式咖啡
- 「每天喝咖啡」定義為早上 9 點前攝取 200ml 美式咖啡
- 因變數操作化:
- 使用線上反應測試工具,測試反應 10 次,取平均反應時間(ms)
- 使用線上反應測試工具,測試反應 10 次,取平均反應時間(ms)
- 信效度說明:
- 使用相同設備與工具進行測試,減少測量誤差
- 同時進行測試以避免時間性干擾(控制晨昏變化)
- 使用相同設備與工具進行測試,減少測量誤差
3.6.6. 實驗設計架構
- 架構類型:雙組後測設計(Two-group Post-test Only Design)
實驗組(咖啡) → 測驗反應速度 控制組(不喝咖啡) → 測驗反應速度
3.6.7. 隨機分派與偏誤控制
- 以亂數方式將 20 人分為兩組,避免分組偏差
- 測試人員不告知受試者屬於哪一組(單盲設計)
- 受試者在測驗時不得使用其他刺激品(如糖果、能量飲)
3.6.8. 資料分析方法
- 比較兩組的平均反應時間(使用 t 檢定)
- 設定顯著水準 α = 0.05
- 若 p-value < 0.05,則認為差異達統計顯著
3.6.9. 結論推論範例
- 若結果為實驗組平均反應時間顯著短於控制組:
- 可推論:「每天喝咖啡」可能有助於提升反應速度
- 可推論:「每天喝咖啡」可能有助於提升反應速度
- 若無顯著差異:
- 無法支持假設,但不能說明「咖啡無效」,可能需控制其他變因
- 無法支持假設,但不能說明「咖啡無效」,可能需控制其他變因
3.7. 模擬實驗結果:
3.7.1. 實驗組與控制組反應時間比較
1: import pandas as pd 2: import numpy as np 3: import matplotlib.pyplot as plt 4: import seaborn as sns 5: from scipy.stats import norm 6: 7: plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # 步驟一(替換系統中的字型,這裡用的是Mac OSX系統) 8: plt.rcParams['axes.unicode_minus'] = False # 9: 10: # 設定隨機種子以確保可重現 11: np.random.seed(42) 12: 13: # 建立受試者基本資料 14: n = 20 15: groups = ['實驗組'] * 10 + ['控制組'] * 10 16: 17: # 模擬反應時間(ms):實驗組平均反應較快 18: # 假設:實驗組平均 240ms,控制組平均 270ms,標準差 15ms 19: reaction_times = np.concatenate([ 20: np.random.normal(loc=240, scale=15, size=10), 21: np.random.normal(loc=270, scale=15, size=10) 22: ]) 23: 24: # 建立資料表 25: df = pd.DataFrame({ 26: '受試者編號': [f'S{i+1:02d}' for i in range(n)], 27: '組別': groups, 28: '反應時間(ms)': reaction_times.round(1) 29: }) 30: 31: 32: # 繪圖顯示反應時間分布 33: plt.figure(figsize=(8, 5)) 34: sns.boxplot(data=df, x='組別', y='反應時間(ms)', palette='Set2') 35: plt.title('實驗組與控制組反應時間比較') 36: plt.ylabel('反應時間(毫秒)') 37: plt.xlabel('組別') 38: plt.grid(True, linestyle='--', alpha=0.5) 39: plt.tight_layout() 40: plt.show() 41:
3.7.2. t檢定結果
1: from scipy.stats import ttest_ind 2: 3: # 分組資料 4: exp_group = df[df['組別'] == '實驗組']['反應時間(ms)'] 5: ctrl_group = df[df['組別'] == '控制組']['反應時間(ms)'] 6: 7: # 獨立樣本 t 檢定(假設等變異) 8: t_stat, p_value = ttest_ind(exp_group, ctrl_group, equal_var=True) 9: 10: # 計算平均與標準差 11: exp_mean, exp_std = exp_group.mean(), exp_group.std(ddof=1) 12: ctrl_mean, ctrl_std = ctrl_group.mean(), ctrl_group.std(ddof=1) 13: 14: # 建立APA格式表格 15: apa_table = pd.DataFrame({ 16: '組別': ['實驗組', '控制組'], 17: 'M': [round(exp_mean, 2), round(ctrl_mean, 2)], 18: 'SD': [round(exp_std, 2), round(ctrl_std, 2)] 19: }) 20: 21: # 加入t檢定結果 22: t_result = pd.DataFrame({ 23: 't(df)': [f"{t_stat:.2f} ({2 * len(exp_group) - 2})"], 24: 'p': [f"{p_value:.3f}" if p_value >= 0.001 else "< .001"] 25: }) 26: 27: # 合併為單一表格 28: apa_output = pd.concat([apa_table, t_result], axis=1) 29: 30: import ace_tools as tools; tools.display_dataframe_to_user(name="APA格式 t 檢定結果", dataframe=apa_output) 31:
| 組別 | M | SD | t(df) | p |
|---|---|---|---|---|
| 實驗組 | 246.72 | 10.83 | -2.30 (18) | 0.033 |
| 控制組 | 258.13 | 11.33 |
為了探討飲用咖啡是否會影響反應速度,本研究比較了實驗組(每日飲用咖啡)與控制組(不飲用咖啡)在反應時間上的差異。結果顯示,實驗組的平均反應時間(M = 246.72, SD = 10.83)顯著快於控制組(M = 258.13, SD = 11.33),兩組之間的差異達統計顯著水準,t(18) = -2.30, p = .033。
3.8. 實驗設計任務:如何設計研究
也就是所謂的實驗設計(Design of Experiment),目前的模擬情境如下,請各組針對該情境提出你們的實驗設計方案
3.8.1. 研究問題1
台南某高中電腦教師自創了一套程式設計教學法(電療教學法),方法是在學生座椅下安裝電擊裝置,當學生送出的程式碼出錯後就予以電擊回饋,他想在被告上法院前評估這套教學法的成效,應如何進行?
3.8.1.1. 任務
請各組提出實驗設計,詳細說明以下資訊
- 實驗詳細流程: 越詳細越好,包括你們打算找多少學生參加實驗?如何找?想教哪個單元?實驗為期多久?如何分派教師?實驗結束後如何評估效果….
- 實驗組(experimental group)
- 控制組(control group)
- 實驗中的自變項(independent variable)
- 實驗中的依變項(dependent variable)
- 實驗中的控制變項(control variable)
- 依據上面的設計,各組打算如何評估實驗結果,提出你們的結論(該教學法有效或無效)
- 你們的實驗是否具備可複製性(replication): 也就是說當後來的其他資訊科老師採用相同的實驗設計,應可獲得相似的研究結果。
3.8.2. 研究問題2
如果你要研究維他命C攝取量與感冒的關係,你要如何進行實驗設計?
3.8.2.1. 任務
請各組提出實驗設計,詳細說明以下資訊
- 實驗詳細流程: 越詳細越好,包括你們打算找多少人參加實驗?如何找?實驗如何進行?為期多久?
- 實驗組(experimental group)
- 控制組(control group)
- 實驗中的自變項(independent variable)
- 實驗中的依變項(dependent variable)
- 實驗中的控制變項(control variable)
- 你的實驗中是否有中介變項(Mediator)
- 依據上面的設計,各組打算如何評估實驗結果,提出你們的結論
- 你們的實驗是否具備可複製性(replication)
- 你們的實驗是否違反研究倫理
3.8.2.2. 研究倫理
舉凡以人作為研究的觀察、參與、實驗對象,所可能牽涉的公共道德爭議與規範,均在研究倫理討論的範疇內。瞭解並重視研究倫理之目的在於,透過對於這些公共道德爭議的釐清與相關規範的建立,讓研究本身不僅是在充分尊重被觀察對象、參與者、實驗對象的權益之情況下進行,且是在可被公眾信賴的基礎上持續進展,以善盡研究者對於研究參與者個人、社群與社會的責任。
4. 資料蒐集與記錄
- 科學研究的品質,常常取決於資料是否蒐集得當、記錄是否清楚。
- 好的實驗設計需要搭配 一致、可重複的資料蒐集流程 與 有系統的記錄方法 。
4.1. 資料蒐集方式
- 觀察法(Observation)
- 研究者直接觀察並記錄行為或現象
- 適合自然環境、行為研究
- 例:觀察學生上課專注程度
- 研究者直接觀察並記錄行為或現象
- 問卷調查(Survey)
- 使用結構化的問題收集受試者回饋
- 可量化主觀感受或態度
- 例:詢問參與者「覺得自己今天清醒嗎?」
- 使用結構化的問題收集受試者回饋
- 量測(Measurement)
- 使用儀器、工具或測驗來得到客觀數值
- 例:記錄反應時間、脈搏、跑步時間等
- 使用儀器、工具或測驗來得到客觀數值
4.2. 建立標準作業流程(SOP, Standard Operating Procedure)
- 為確保資料一致與準確,須建立明確流程
- 量測時間與地點
- 測量方式與工具(需固定)
- 紀錄人員與方式
- 每位參與者的操作順序
- 量測時間與地點
📌 例如:若一人於安靜教室進行反應測驗,另一人則在吵雜環境,結果可能無法比較 → 所以「一致性」非常關鍵。
4.3. 資料記錄建議
- 使用 Google Sheets、Excel 或簡單的統計表格紀錄資料
- 表格欄位建議包含:
- 受試者編號
- 實驗組別(有 / 無)
- 測量值(如反應時間、問卷分數)
- 備註欄(記錄異常或特殊情況)
- 受試者編號
4.4. 實例示範:每天喝咖啡的人反應速度較快?
4.4.1. Four fundamental concepts you need to know about hypothesis testing
- 樣本數 Sample Size: 研究中實際納入分析並進行統計檢定的受試者數量。通常用 \(N\) 表示總樣本數(如 \(N=40\)),\(n\) 表示子樣本(如男性 \(n=20\)、女性 \(n=20\))
- 第一類型錯誤 \(\alpha\): 指在「實際上無差異」( \(H_0\) 成立)的情況下,卻錯誤判定為有差異的機率。 用希臘字母 \(\alpha\) 表示,或寫作 \(P(D| H_0)\), 亦即 \(H_0\) 為真的條件下觀察到結果 \(D\) 的機率。
- 檢定力 Power: 在「實際上有差異」時,研究能夠偵測出差異的能力,即 \(1-\beta\) 。換言之,Power 越高,研究越不容易錯失真正的效應(避免第二類型錯誤)。
- 效果量 Effect Size: 用來衡量兩組之間差異的實際大小,不受樣本數影響,是統計檢定的重要指標。常見指標有
- Cohen’s d(兩組平均數差異), 這裡的 d 是一種衡量「兩組之間差異效果大小」的指標,用來表示兩組平均數之間的差距有多明顯。有以下幾類型
- d = 0.2(小效果)
- d = 0.5(中等效果)
- d = 0.8(大效果)
- d = 0.2(小效果)
- \(R^2\)(解釋變異比例)
- Cohen’s d(兩組平均數差異), 這裡的 d 是一種衡量「兩組之間差異效果大小」的指標,用來表示兩組平均數之間的差距有多明顯。有以下幾類型
4.4.1.1. 統計推論中的錯誤類型
| 拒絕 \(H_0\)(判定有差異) | 不拒絕 \(H_0\)(判定無差異) | |
|---|---|---|
| \(H_0\) 為真(無差異) | 第一型錯誤(Type I Error) | 正確判斷(真陰性) |
| 誤判有差異(\(\alpha\)) | ||
| \(H_1\) 為真(有差異) | 正確判斷(真陽性) | 第二型錯誤(Type II Error) |
| 漏判差異(\(\beta\)) |
4.4.2. 如何決定樣本數?
在研究設計初期,我們經常會問:「到底要收多少樣本才夠?」其實只要設定以下三項,就可以推估所需樣本數 \(N\) :
- \(\alpha\)(第一型錯誤機率)
- Power(檢定力)
- ES(效果量)
常見預設值:
- \(\alpha = 0.05\)(表示可接受 5% 的假陽性率)
- Power = 0.8(表示有 80% 的機會偵測到實際存在的效應)
效果量的選擇:
效果量 ES 則依研究類型與統計方法而異,一般有兩種處理方式:
- 依慣例選擇:使用 Cohen 所定義的等級,將 ES 設為:
- 小:\(d = 0.2\)
- 中:\(d = 0.5\)
- 大:\(d = 0.8\)
- 小:\(d = 0.2\)
- 參考先前研究或前測結果:如果已有相關研究或先行實驗資料,可據此估算效果量。
目前大多數研究會使用專門軟體(如 G*Power)來進行樣本數估算。操作方式非常簡單,研究者只需輸入上述三項(\(\alpha\)、Power、ES),軟體就會自動計算所需樣本數。
4.4.2.1. statsmodels.stats.power
這是最常用的 Python 工具之一,提供與 G*Power 類似的功能。
1: from statsmodels.stats.power import TTestIndPower 2: 3: # 建立分析器物件 4: analysis = TTestIndPower() 5: 6: # 計算所需樣本數(每組) 7: sample_size = analysis.solve_power(effect_size=0.5, power=0.8, alpha=0.05, alternative='two-sided') 8: print(f"所需每組樣本數:{sample_size:.1f}")
4.4.3. 你需要多少樣本:以咖啡實驗為例
| 效果大小 | 每組最小人數 | 總人數 |
|---|---|---|
| 大( \(d=0.8\) ) | ~26 | 52 |
| 中( \(d=0.5\) ) | ~64 | 128 |
| 小( \(d=0.2\) ) | ~394 | 788 |
4.4.4. 咖啡實驗資料蒐集方式
- 自變數操作:指定某組受試者每天早上喝一杯 200ml 黑咖啡,連續 7 天
- 因變數量測:第 8 天使用線上反應測試網站進行測試,紀錄平均反應時間(毫秒)
- 補充問卷:進行自我清醒程度評分(Likert 1~5)
4.4.5. 咖啡實驗標準作業流程(SOP)
- 實驗第 1~7 天,於早上 8:30 提供咖啡,確保空腹與未進食其他刺激物
- 第 8 天於 9:00 準時測試反應速度,使用同一台筆電與網站
- 試驗過程由相同人員指導,避免操作差異
- 每位參與者完成測試後立即填寫問卷
4.4.6. 咖啡實驗資料記錄表格(建議格式)
| 受試者編號 | 組別 | 平均反應時間(ms) | 清醒自評(1~5) | 備註 |
|---|---|---|---|---|
| P001 | 實驗組 | 275 | 4 | 無異常 |
| P002 | 控制組 | 310 | 3 | 前一晚睡眠不足 |
| P003 | 實驗組 | 260 | 5 | 無異常 |
| … | … | … | … | … |
- 分析方式:
- 使用反應時間的平均與標準差進行描述統計
- 使用 t 檢定比較兩組之間的差異是否達顯著水準
- 使用反應時間的平均與標準差進行描述統計
5. 基本統計與結果檢定
5.1. 描述統計(Descriptive Statistics)
描述統計主要用於總結和描述資料的基本特徵,透過各種方法來呈現資料的概要資訊。它不涉及對整體資料之外的推論或預測。描述統計的主要工具包括:
- 集中趨勢測量:如平均值(Mean)、中位數(Median)和眾數(Mode)。
- 變異性測量:如範圍(Range)、四分位距(Interquartile Range, IQR)、標準差(Standard Deviation)和方差(Variance)。
- 分佈測量:如頻率分佈(Frequency Distribution)、百分比(Percentage)和直方圖(Histogram)。
- 圖形表示:如條形圖(Bar Chart)、折線圖(Line Graph)、餅圖(Pie Chart)和箱形圖(Box Plot)。
- 常見圖表:
- 長條圖(Bar Chart):比較不同組別平均
- 箱型圖(Box Plot):呈現分布與極端值
- 散佈圖(Scatter Plot):看兩變數的關係
- 長條圖(Bar Chart):比較不同組別平均
5.2. 推論統計(Inferential Statistics)簡介
推論統計則超越了對資料的描述,主要用於從樣本資料推論到更大的母體,並對母體特徵進行預測和假設檢驗。推論統計使用的主要方法包括:
- 估計:如點估計(Point Estimation)和區間估計(Interval Estimation),用來估計母體參數(如母體平均數和比例)。
- 假設檢定:如 t 檢驗(t-test)、卡方檢驗(Chi-Square Test)、ANOVA(分析變異數,Analysis of Variance)和回歸分析(Regression Analysis),用來檢驗假設是否成立。
- 信賴區間:用來表示母體參數的範圍,通常以一定的信心水準(如 95%)給出。
- 相關分析:如皮爾森相關係數(Pearson Correlation)和斯皮爾曼相關係數(Spearman Correlation),用來測量變量之間的相關程度。
- 常見統計方式
- t 檢定(t-test):
- 用於比較兩組平均是否有顯著差異
- 例:比較有喝咖啡與沒喝咖啡者的反應時間是否不同
- 用於比較兩組平均是否有顯著差異
- 卡方檢定(Chi-square test):
- 分析分類資料的關聯性(例如性別與是否喝咖啡)
- 適合問卷選項或人數比較
- 分析分類資料的關聯性(例如性別與是否喝咖啡)
- 相關分析(Correlation):
- 檢查兩個連續變數的線性關係
- 例:喝咖啡的頻率與清醒程度的關係
- 檢查兩個連續變數的線性關係
- t 檢定(t-test):
5.3. p 值的意義與解釋
- p 值(probability value)是指:
在零假設為真時,觀察到目前這種結果(或更極端結果)的機率 - 當 p < 0.05 時,常視為結果達到「統計顯著」
- 這表示:觀察到目前結果的機率低於 5%,可懷疑零假設不成立
- 小 p 值 → 結果罕見 → 有可能不是偶然(但不能直接說明原因)
5.4. 常見錯誤解釋與統計陷阱
- 「p 值小於 0.05 就證明假設為真」
→ 錯!只能說結果 與虛無假設(Null Hypothesis)不一致 , 不能證明假設為真 - 「p 值越小,效果越大」
→ 錯!p 值與效果大小無關,需使用效果量(effect size) - 「沒達顯著就代表沒效果」
→ 錯!可能是樣本數太少或變異太大
結論應該謹慎說明:「在本實驗條件下,資料顯示喝咖啡組的反應速度顯著較快,p = 0.03。」
6. 論文結果說明與討論
6.1. 什麼是「結果(Results)」?
- 結果章節的目的是:
- 客觀陳述實驗所得的資料與觀察
- 客觀描述, 不加入主觀解釋或評價
- 常使用表格、圖表輔助說明
- 客觀陳述實驗所得的資料與觀察
- 寫作原則:
- 實驗做了什麼 → 得到什麼
- 資料來說話,不添加推論
- 每個實驗目的或問題都有對應結果
- 避免使用「因為」「所以」「這表示」等詞語
- 實驗做了什麼 → 得到什麼
- 範例
「實驗組的平均反應時間為 275ms,控制組為 310ms,兩組間的差異達統計顯著(p = 0.004)。」
6.2. 什麼是「討論(Discussion)」?
- 討論章節的目的是:
- 解釋實驗結果的意義
- 對比其他研究、文獻
- 提出可能的機制、限制與後續建議
- 解釋實驗結果的意義
- 討論的重點包括:
- 解釋結果為什麼會這樣?
- 與你原來的假設一致嗎?
- 有沒有跟別人的研究結果不同?為什麼?
- 有什麼變因可能影響結果(限制)?
- 根據結果,可以有哪些應用或延伸研究?
- 解釋結果為什麼會這樣?
- 範例
「本研究結果支持『喝咖啡可提高反應速度』的假設,與 Lee et al. (2020) 的研究結果一致。他們指出咖啡因可刺激中樞神經系統,加速認知反應。可能的限制是未控制受試者的睡眠狀況與飲食影響,未來可進一步精確控制這些變項。」
6.3. 簡單比較:結果 vs 討論
| 項目 | 結果(Results) | 討論(Discussion) |
|---|---|---|
| 重點 | 呈現實驗的資料與結果 | 解釋、推論與評價實驗結果 |
| 內容 | 表格、統計、觀察 | 理由、對比、限制、建議 |
| 態度 | 客觀、描述性 | 主觀、分析性 |
| 語言 | 少用推論語句(如「因為」、「可能」) | 常用推論語句(如「這可能表示…」、「顯示…」) |
6.4. 教學延伸建議
- 帶學生閱讀一篇簡短論文或科展報告,標出哪些屬於「結果」,哪些屬於「討論」
- 安排練習活動:提供一組模擬資料,請學生分別寫出「結果」段落與「討論」段落
Footnotes:
Ferguson,2009,An Effect Size Primer: A Guide for Clinicians and Researchers
Card, David, and Alan B. Krueger. “Minimum Wages and Employment: A Case Study of the Fast Food Industry in New Jersey and Pennsylvania.” American Economic Review, 1994.
Brown, Charles, Curtis Gilroy, and Andrew Kohen. “The Effect of the Minimum Wage on Employment and Unemployment.” Journal of Economic Literature, 1982.
Neumark, David, and William Wascher. “Minimum Wages and Employment: A Review of Evidence from the New Minimum Wage Research.” NBER Working Paper No. 12663, 2006.
Dube, Arindrajit, T. William Lester, and Michael Reich. “Minimum Wage Effects Across State Borders: Estimates Using Contiguous Counties.” Review of Economics and Statistics, 2010.
Meer, Jonathan, and Jeremy West. “Effects of the Minimum Wage on Employment Dynamics.” Journal of Human Resources, 2016.