Pandas
Table of Contents

1. 簡介
對於使用 Python 進行資料分析的使用者來說,Pandas 是一個非常重要且常用的函式庫。Pandas 提供了高效能、易於使用的資料結構和資料分析工具,使得處理和分析資料變得更加簡單和方便。
1.1. 使用情境
對於以下這些同學來說,Pandas 是一個非常有用的工具:
- 未來你可能要在電腦上跑一些模擬軟體或資料分析軟體
- 未來你可能要接觸一些科學儀器或其他設備來收集數據,這類設備通常會生成大量的、格式複雜的資料
- 未來你可能要從網路上抓取一些資料來進行分析,這些資料通常是以 CSV、JSON、Excel 等格式存儲的
如果你還在想著Excel,早點放下它吧! Pandas 可以讓你更有效率地處理和分析資料,並且可以輕鬆地與其他 Python 函式庫(如 NumPy、Matplotlib、Scikit-learn)結合使用,讓你能夠更快地獲得有用的資訊。
學會使用 Pandas,可以幫助你更好地理解資料分析的流程和方法,並且可以讓你更快地完成資料分析的任務。它可以協助你輕鬆地完成以下幾個方面的工作:
- 資料清理與準備: Pandas 提供了強大的資料清理和準備功能,可以輕鬆地處理缺失值、重複值、資料轉換等問題。
- 資料探索與分析: Pandas 提供了豐富的資料探索和分析工具,可以快速地進行資料篩選、分組、聚合等操作。
- 資料視覺化: Pandas 可以與其他資料視覺化函式庫(如 Matplotlib、Seaborn)結合使用,方便地進行資料視覺化。
- 機器學習: Pandas 可以與機器學習函式庫(如 Scikit-learn)結合使用,方便地進行資料預處理和特徵工程。
1.2. Pandas
- 建構於 NumPy 之上分析模組,適合處理表格資料或異質資料。
- 於 2009 年底開源出來,提供高效能、簡易使用的資料格式(Data Frame,為 R 語言主要資料格式),可以讓使用者可以快速操作及分析資料。
- Pandas 強化了資料處理的方便性也能與處理網頁資料與資料庫資料等,有點類似於Office 的 Excel,能更加方便的進行運算、分析等1。
- Pandas 主要特色有2:
- 在異質數據的讀取、轉換和處理上,都讓分析人員更容易處理,例如:從列欄試算表中找到想要的值。
- Pandas 提供兩種主要的資料結構,Series 與 DataFrame。Series 顧名思義就是用來處理時間序列相關的資料(如感測器資料等),主要為建立索引的一維陣列。DataFrame 則是用來處理結構化(Table like)的資料,有列索引與欄標籤的二維資料集,例如關聯式資料庫、CSV 等等。
- 透過載入至 Pandas 的資料結構物件後,可以透過結構化物件所提供的方法,來快速地進行資料的前處理,如資料補值,空值去除或取代等。
- 更多的輸入來源及輸出整合性,例如:可以從資料庫讀取資料進入 Dataframe,也可將處理完的資料存回資料庫。
- 在異質數據的讀取、轉換和處理上,都讓分析人員更容易處理,例如:從列欄試算表中找到想要的值。
1.3. CSV
Pandas 最常用來處理的資料格式為 CSV 檔案,對於那些將來會有需要分析實驗數據的使用者來說,Pandas 是一個非常有用的工具。不管你是使用一些科學儀器或是其他設備來收集數據,這些數據通常都會以 CSV 檔案的形式存儲。就算你是在電腦上跑一些模擬軟體,這些軟體也通常會將結果輸出為 CSV 檔案。Pandas 可以幫助你輕鬆地讀取、處理和分析這些 CSV 檔案中的數據,讓你能夠更快地獲得有用的資訊。
- Comma-Separated Values, 為純文字檔,以逗號分隔值,有時也稱為字元分隔值,因為分隔字元也可以不是逗號)。
- 純文字意味著該檔案是一個字元序列,不含必須像二進位制數字那樣被解讀的資料。
- CSV 檔案由任意數目的記錄組成,記錄間以某種換行符分隔;每條記錄由欄位組成,欄位間的分隔符是其它字元或字串,最常見的是逗號。
- 如果你有使用過 Excel 或其他試算表軟體,應該對 CSV 檔案不陌生,因為這些軟體通常都可以將資料匯出為 CSV 檔案格式。
1.4. Pandas 資料結構
Pandas 兩類資料結構2:
- Series: 用來處理時間序列相關的資料(如感測器資料等),主要為建立索引的一維陣列。
- DataFrame: 是一個二維標籤資料結構,可以具有不同類型的行(column),類似 Excel的資料表,對於有使用過統計軟體的分析人員應該不陌生。簡單來說,Series 可以想像為一行多列(row)的資料,而 DataFrame 是多行多列的資料,藉由選擇索引(列標籤)和行(行標籤)的參數來操作資料,就像使用統計軟體透過樣本編號或變項名稱來操作資料。
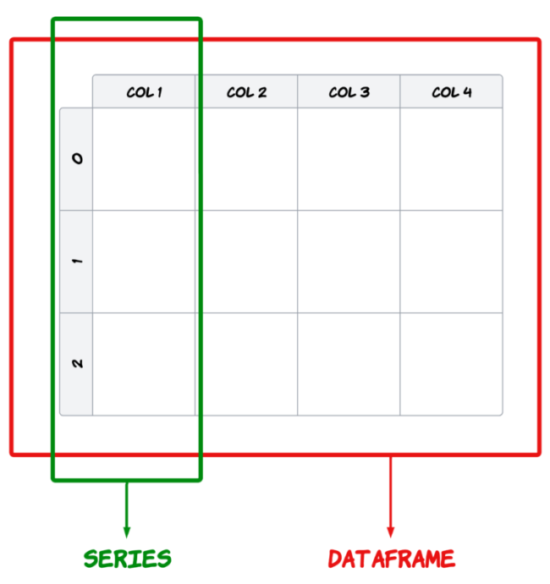
Figure 1: Series v.s. Dataframe
2. Series
一維資料(表格中的一欄),類似numpy中的vector,但可以儲存任何類型的數據,包括整數、浮點數、字串等等。
2.1. 建立: 資料類型可為 array, dictionary
2.1.1. 由 array 建立 Series
1: import pandas as pd 2: 3: cars = ["SAAB", "Audi", "BMW", "BENZ", "Toyota", "Nissan", "Lexus"] 4: print("資料型別:", type(cars)) 5: carsToSeries = pd.Series(cars) 6: print("資料型別:", type(carsToSeries)) 7: print(carsToSeries.shape) 8: print(carsToSeries) 9: print("carsToSeries[1]: ", carsToSeries[1])
資料型別: <class 'list'> 資料型別: <class 'pandas.core.series.Series'> (7,) 0 SAAB 1 Audi 2 BMW 3 BENZ 4 Toyota 5 Nissan 6 Lexus dtype: object Audi
2.2. 資料篩選
2.2.1. 由dict來建立pandas.Series()
就是把dict的key當成index
1: import pandas as pd 2: 3: dict = { 4: "city": "Kaohsiung", 5: "speedCamera1": "13213", 6: "speedCamera2": "3242", 7: "speedCamera3": "134343", 8: "speedCamera4": "4312", 9: "speedCamera5": "533" 10: } 11: 12: dictToSeries = pd.Series(dict, index = dict.keys()) # 排序與原 dict 相同 13: print(dictToSeries[0]) 14: print("=====") 15: print(dictToSeries['speedCamera1']) 16: print("=====") 17: print(dictToSeries[[0, 2, 4]]) 18: print("=====") 19: print(dictToSeries[['city', 'speedCamera1', 'speedCamera3']]) 20: print("=====") 21: print(dictToSeries[:2]) 22: print("=====") 23: print(dictToSeries[4:]) 24: # 查詢 25: print("====會發現有一個NaN=====") 26: search=['speedCamera1', 'speedCamera6'] 27: print(pd.Series(dictToSeries, index=search))
Kaohsiung ===== 13213 ===== city Kaohsiung speedCamera2 3242 speedCamera4 4312 dtype: object ===== city Kaohsiung speedCamera1 13213 speedCamera3 134343 dtype: object ===== city Kaohsiung speedCamera1 13213 dtype: object ===== speedCamera4 4312 speedCamera5 533 dtype: object ====會發現有一個NaN===== speedCamera1 13213 speedCamera6 NaN dtype: object
3. DataFrame
其實,你可以單純把DataFrame看成Excel裡的一大張工作表,裡面有很多列(row)和欄(column),每一列代表一筆資料,每一欄代表一個變數(欄位)。DataFrame可以讓你很方便地操作這些資料,例如篩選、排序、計算統計量等等。
唯一不同的是,DataFrame是用程式碼來操作的,而不是用滑鼠點來點去的。這樣可以讓你更有效率地處理大量資料,並且可以重複使用你的程式碼來處理不同的資料集。
永遠記住一件事,但凡某件事需要你 用滑鼠去重複點來點去 的,那麼這件事就 不值得你去做 ,因為你可以用程式碼來自動化這件事,讓電腦幫你做。
那麼,要如何在Python中建立你的DataFrame呢?很簡單,你可以使用Pandas這個函式庫來建立DataFrame。Pandas提供了很多方便的方法來建立和操作DataFrame,讓你可以輕鬆地處理你的資料。
3.1. DataFrame 建立
可利用 Dictionary 或是 Array 來建立,並使用 DataFrame 的方法來操作資料查看、資料篩選、資料切片、資料排序等運算。
3.2. 由 Dictionary 建立
如果你對Dictionary不熟,可以先跳過這一節,或是去參考Python 基礎的相關章節。
1: import pandas as pd 2: 3: hobby = ["Movies", "Sports", "Coding", "Fishing", "Dancing", "cooking"] 4: count = [46, 8, 12, 12, 6, 58] 5: 6: dict = {"hobby": hobby, 7: "count": count 8: } 9: print(dict) 10: df = pd.DataFrame(dict) 11: print(df)
{'hobby': ['Movies', 'Sports', 'Coding', 'Fishing', 'Dancing', 'cooking'], 'count': [46, 8, 12, 12, 6, 58]}
hobby count
0 Movies 46
1 Sports 8
2 Coding 12
3 Fishing 12
4 Dancing 6
5 cooking 58
3.3. 由 二維List 建立
就是先建立一個二維陣列(矩陣),然後再利用 pd.DataFrame() 來把這個二維陣列轉成 DataFrame。
1: import pandas as pd 2: 3: ary = [["Movies", 46],["Sports", 8], ["Coding", 12], ["Fishing",12], ["Dancing",6], ["cooking",8]] 4: print(ary) 5: ary2df = pd.DataFrame(ary, columns = ["hobby", "count"]) # 單純的二維矩陣沒有欄位名稱,要外加指定欄標籤名稱 6: print(ary2df) 7:
[['Movies', 46], ['Sports', 8], ['Coding', 12], ['Fishing', 12], ['Dancing', 6], ['cooking', 8]]
hobby count
0 Movies 46
1 Sports 8
2 Coding 12
3 Fishing 12
4 Dancing 6
5 cooking 8
3.4. 讀入外部資料檔來建立 Dataframe
當然,更常見的情況是,你會從外部資料檔案(如 CSV 檔)來讀取資料,然後把這些資料放入 DataFrame 中,進行資料查看、資料篩選、資料切片等運算。
首先,我們假設你的電腦上有一個CSV檔案,裡面包含了一些學生的成績資料。你可以先點擊以下連結下載這個範例檔案,然後依你的執行環境(Colab或PyCharm)來進行不同的操作。
3.4.1. 本機CSV(由本機端的PyCharm執行,不能在Google colab上跑)
如果你是在本機端使用PyCharm來執行Python程式碼,那你先看看你下載的CSV檔案放在哪個資料夾,然後把那個路徑填入下面的程式碼中,就可以直接讀取這個CSV檔案並建立DataFrame了。
以pd.read_csv()來讀取CSV檔案後就會變成DataFrame物件,接著就可以使用DataFrame的方法來操作資料了。
pd.read_csv() 常用參數:
| 參數 | 說明 | 預設值 |
|---|---|---|
| filepath | 檔案路徑或 URL | (必填) |
| sep | 分隔符號,CSV 用逗號,TSV 用 tab(=’\t’=) | ',' |
| header | 第幾列當欄位名稱;=None= 表示無標題列 | 0 |
| index_col | 指定哪一行做為索引 | None |
| usecols | 只讀取指定的行(欄位),傳入 list | None |
| encoding | 編碼格式,中文檔案常需指定 'utf-8' 或 'big5' |
None |
1: import pandas as pd 2: 3: # 讀取csv 4: df = pd.read_csv("/Users/student/Downloads/scores.csv") #這裡的路徑要自行更改 5: print("===全部資料===") 6: print(df)
3.4.2. Google Colab的檔案上傳
對於使用Google Colab的同學來說,因為Colab是雲端環境,所以你需要先把本機的檔案上傳到Colab,然後才能讀取這些檔案。以下是如何在Colab中上傳檔案並使用Pandas讀取CSV檔案的步驟:
3.4.2.1. 在Colab中執行以下程式碼來上傳檔案:
1: from google.colab import files 2: uploaded = files.upload()
- import google.colab後,使用files.upload() 就能夠產生上傳檔案,此時cell會進入等待狀態,選取你本機的檔案即可上傳。
- 執行後會出現以下畫面:

Figure 2: Colab上傳檔案
- 接下來點選「瀏覽」選取檔案後即可將檔案上傳至Colab
3.4.2.2. 檔案上傳到哪裡?
這個上傳的檔案會被放在Colab的臨時目錄中,通常是`/content/`。你可以使用以下程式碼來查看目前所在的目錄以及該目錄下的檔案:
1: !ls
ls是Linux系統的指令,可以列出目前目錄下的檔案清單,你應該可以看到剛剛上傳的CSV檔案。如果你想確認目前所在的目錄,
也可以執行!pwd查看現在在哪一個目錄(資料夾)
1: !pwd
pwd是Linux系統的指令,可以顯示目前所在的目錄路徑。
3.4.2.3. 在Google Colab以Pandas查看csv檔
接下來你就可以再新增一個Code Cell來讀取這個CSV檔案並建立DataFrame了。假設你上傳的檔案名稱是`scores.csv`,那麼你可以使用以下程式碼來讀取這個檔案:
1: import pandas as pd 2: 3: # 讀取csv 4: df = pd.read_csv("/content/scores.csv") #這裡的路徑要自行更改 5: print("===全部資料===") 6: print(df)
3.4.3. 由Pandas直接讀取線上CSV檔
最後,我們來看最簡單的方法: 直接讓Pandas讀取線上的CSV檔案。這樣你就不需要先下載檔案再上傳了,Pandas會自動幫你下載並讀取檔案。
1: import pandas as pd 2: docURL = 'https://letranger.github.io/PythonCourse/scores.csv' #直接指定檔案的URL 3: df = pd.read_csv(docURL) 4: print('=====dataFrame的維度') 5: print(df.shape) 6: print('=====dataFrame的數值分佈概況') 7: print(df.describe()) 8: print('=====dataFrame的前5筆記錄') 9: print(df.head(5))
=====dataFrame的維度
(212, 6)
=====dataFrame的數值分佈概況
classparti typing homework midexam finalexam
count 212.000000 212.00000 212.000000 211.000000 212.000000
mean 92.386792 82.09434 89.394764 62.863033 49.458491
std 13.798874 23.06041 19.471763 34.104173 34.831187
min 14.000000 0.00000 10.750000 0.000000 0.000000
25% 87.000000 68.00000 83.880000 35.000000 20.000000
50% 94.000000 80.00000 97.370000 67.000000 45.000000
75% 101.000000 96.00000 102.630000 95.000000 76.000000
max 120.000000 120.00000 107.890000 113.500000 115.000000
=====dataFrame的前5筆記錄
id classparti typing homework midexam finalexam
0 S201910901 100 72 92.11 48.0 16.0
1 S201910902 96 56 93.42 60.0 40.0
2 S201910903 96 76 102.63 45.0 28.0
3 S201910904 93 64 86.84 44.0 25.0
4 S201910905 93 56 42.11 0.0 20.0
4. DataFrame 的資料瀏覽
有了 DataFrame 之後,接下來就可以使用 DataFrame 提供的方法來瀏覽和操作資料了。以下是一些常用的方法:
4.1. 基本函數
這些是在你讀入一個DataFrame之後,最常用來查看DataFrame內容的函數:
- shape
用途:查看 DataFrame 的維度(行數與列數),傳回一個包含行數和列數的 tuple。 - describe()
提供數據的統計摘要, 對數值型資料列出統計資訊,如平均值、標準差、最小值、四分位數等。 - head()
顯示 DataFrame 的前幾行資料, 預設顯示前 5 行資料,但可以加入顯示行數參數。 - tail()
顯示 DataFrame 的後幾行資料, 預設顯示最後 5 行資料,和 head() 類似,可以指定顯示行數。 - columns
列出 DataFrame 的所有欄位名稱, 傳回所有列(欄)的名稱,幫助了解 DataFrame 的結構。 - index
返回 DataFrame 的索引(行標籤), 查看 DataFrame 中的行標籤,用於確認資料的索引範圍或類型。 - info()
顯示 DataFrame 的結構化資訊, 包含 DataFrame 中的行數、列數、欄位類型、非空值計數、記憶體使用情況等,常用於總覽資料集的結構。
4.1.1. 範例
1: import pandas as pd 2: docURL = 'https://letranger.github.io/PythonCourse/scores.csv' 3: df = pd.read_csv(docURL) 4: 5: print("====df.shape====") 6: print(df.shape) # 回傳列數與欄數 7: print("====df.describe()====") 8: print(df.describe()) # 回傳描述性統計 9: print("====df.head(3)====") 10: print(df.head(3)) # 回傳前三筆觀測值 11: print("====df.tail(3)====") 12: print(df.tail(3)) # 回傳後三筆觀測值 13: print("====df.columns====") 14: print(df.columns) # 回傳欄位名稱 15: print("====df.columns====") 16: print(df.index) # 回傳 index 17: print("====df.info====") 18: print(df.info) # 回傳資料內容
====df.shape====
(212, 6)
====df.describe()====
id classparti typing homework midexam finalexam
count 2.120000e+02 212.000000 212.00000 212.000000 211.000000 212.000000
mean 2.019113e+08 92.386792 82.09434 89.394764 62.863033 49.458491
std 2.933047e+02 13.798874 23.06041 19.471763 34.104173 34.831187
min 2.019109e+08 14.000000 0.00000 10.750000 0.000000 0.000000
25% 2.019110e+08 87.000000 68.00000 83.880000 35.000000 20.000000
50% 2.019111e+08 94.000000 80.00000 97.370000 67.000000 45.000000
75% 2.019116e+08 101.000000 96.00000 102.630000 95.000000 76.000000
max 2.019117e+08 120.000000 120.00000 107.890000 113.500000 115.000000
====df.head(3)====
id classparti typing homework midexam finalexam
0 201910901 100 72 92.11 48.0 16.0
1 201910902 96 56 93.42 60.0 40.0
2 201910903 96 76 102.63 45.0 28.0
====df.tail(3)====
id classparti typing homework midexam finalexam
209 201911728 83 48 102.63 83.0 75.0
210 201911729 87 84 105.26 112.3 103.0
211 201911730 96 72 102.63 91.0 100.0
====df.columns====
Index(['id', 'classparti', 'typing', 'homework', 'midexam', 'finalexam'], dtype='object')
====df.columns====
RangeIndex(start=0, stop=212, step=1)
====df.info====
<bound method DataFrame.info of id classparti typing homework midexam finalexam
0 201910901 100 72 92.11 48.0 16.0
1 201910902 96 56 93.42 60.0 40.0
2 201910903 96 76 102.63 45.0 28.0
3 201910904 93 64 86.84 44.0 25.0
4 201910905 93 56 42.11 0.0 20.0
.. ... ... ... ... ... ...
207 201911726 106 80 102.63 96.5 103.0
208 201911727 82 60 102.63 84.0 100.0
209 201911728 83 48 102.63 83.0 75.0
210 201911729 87 84 105.26 112.3 103.0
211 201911730 96 72 102.63 91.0 100.0
[212 rows x 6 columns]>
4.2. DataFrame 資料排序
當資料量很大時,排序是一個很常用的功能。Pandas 提供了兩個主要的方法來對 DataFrame 進行排序:
4.2.1. sort_values():
這個方法是根據指定的欄位值來排序,可以指定單一欄位或多個欄位來進行排序,並且可以選擇是要升冪(ascending=True)還是降冪(ascending=False)排序。
這也是最常用的排序方法,因為我們通常都是根據某個欄位的值來決定資料的順序。
1: import pandas as pd 2: docURL = 'https://letranger.github.io/PythonCourse/scores.csv' 3: df = pd.read_csv(docURL) 4: 5: print("====Original====") 6: print(df.head()) 7: print("===.sort_values()====") 8: print(df.sort_values(by = 'classparti')[:5]) 9: print(df.sort_values(by = ['midexam', 'finalexam'], ascending=False)[:5])
====Original====
id classparti typing homework midexam finalexam
0 S201910901 100 72 92.11 48.0 16.0
1 S201910902 96 56 93.42 60.0 40.0
2 S201910903 96 76 102.63 45.0 28.0
3 S201910904 93 64 86.84 44.0 25.0
4 S201910905 93 56 42.11 0.0 20.0
===.sort_values()====
id classparti typing homework midexam finalexam
18 S201910919 14 56 25.92 0.0 0.0
42 S201911006 20 68 92.11 27.0 20.0
27 S201910928 37 108 89.47 0.0 20.0
116 S201911307 53 60 41.45 0.0 0.0
10 S201910911 62 44 20.39 4.0 0.0
id classparti typing homework midexam finalexam
88 S201911115 120 88 105.26 113.5 111.00
98 S201911125 119 80 107.89 113.2 115.00
210 S201911729 87 84 105.26 112.3 103.00
11 S201910912 87 92 92.11 110.8 103.75
195 S201911714 102 44 107.89 110.0 110.00
4.2.2. sort_index():
依欄位名稱或index值來排。當你的資料欄位很多而且大多是依照字母順序排列時,這個方法就很有用。
1: import pandas as pd 2: docURL = 'https://letranger.github.io/PythonCourse/scores.csv' 3: df = pd.read_csv(docURL) 4: 5: print("====Original====") 6: print(df.head()) 7: print("===.sort_index()====") 8: print(df.sort_index(axis = 1, ascending = True)) 9: print("===.sort_index()====") 10: print(df.sort_index(axis = 0, ascending = False))
====Original====
id classparti typing homework midexam finalexam
0 S201910901 100 72 92.11 48.0 16.0
1 S201910902 96 56 93.42 60.0 40.0
2 S201910903 96 76 102.63 45.0 28.0
3 S201910904 93 64 86.84 44.0 25.0
4 S201910905 93 56 42.11 0.0 20.0
===.sort_index()====
classparti finalexam homework id midexam typing
0 100 16.0 92.11 S201910901 48.0 72
1 96 40.0 93.42 S201910902 60.0 56
2 96 28.0 102.63 S201910903 45.0 76
3 93 25.0 86.84 S201910904 44.0 64
4 93 20.0 42.11 S201910905 0.0 56
.. ... ... ... ... ... ...
207 106 103.0 102.63 S201911726 96.5 80
208 82 100.0 102.63 S201911727 84.0 60
209 83 75.0 102.63 S201911728 83.0 48
210 87 103.0 105.26 S201911729 112.3 84
211 96 100.0 102.63 S201911730 91.0 72
[212 rows x 6 columns]
===.sort_index()====
id classparti typing homework midexam finalexam
211 S201911730 96 72 102.63 91.0 100.0
210 S201911729 87 84 105.26 112.3 103.0
209 S201911728 83 48 102.63 83.0 75.0
208 S201911727 82 60 102.63 84.0 100.0
207 S201911726 106 80 102.63 96.5 103.0
.. ... ... ... ... ... ...
4 S201910905 93 56 42.11 0.0 20.0
3 S201910904 93 64 86.84 44.0 25.0
2 S201910903 96 76 102.63 45.0 28.0
1 S201910902 96 56 93.42 60.0 40.0
0 S201910901 100 72 92.11 48.0 16.0
[212 rows x 6 columns]
4.2.3. 有關排序的重要說明
sort 後的結果為 複本 ,不改變原本的資料,意思是說,當你使用 sort_values() 或 sort_index() 來排序 DataFrame 時,Pandas 會回傳一個 新的 DataFrame,這個新的 DataFrame 是排序後的結果,而原本的 DataFrame 仍然 保持不變 。
1: import pandas as pd 2: docURL = 'https://letranger.github.io/PythonCourse/scores.csv' 3: df = pd.read_csv(docURL) 4: 5: print("====Original====") 6: print(df.head()) 7: print("===.sort_index()====") 8: print(df.sort_index(axis = 1, ascending = True)) 9: 10: print('=== 在經過排序後,現在的df內容為 ===') 11: print(df.head())
====Original====
id classparti typing homework midexam finalexam
0 S201910901 100 72 92.11 48.0 16.0
1 S201910902 96 56 93.42 60.0 40.0
2 S201910903 96 76 102.63 45.0 28.0
3 S201910904 93 64 86.84 44.0 25.0
4 S201910905 93 56 42.11 0.0 20.0
===.sort_index()====
classparti finalexam homework id midexam typing
0 100 16.0 92.11 S201910901 48.0 72
1 96 40.0 93.42 S201910902 60.0 56
2 96 28.0 102.63 S201910903 45.0 76
3 93 25.0 86.84 S201910904 44.0 64
4 93 20.0 42.11 S201910905 0.0 56
.. ... ... ... ... ... ...
207 106 103.0 102.63 S201911726 96.5 80
208 82 100.0 102.63 S201911727 84.0 60
209 83 75.0 102.63 S201911728 83.0 48
210 87 103.0 105.26 S201911729 112.3 84
211 96 100.0 102.63 S201911730 91.0 72
[212 rows x 6 columns]
=== 在經過排序後,現在的df內容為 ===
id classparti typing homework midexam finalexam
0 S201910901 100 72 92.11 48.0 16.0
1 S201910902 96 56 93.42 60.0 40.0
2 S201910903 96 76 102.63 45.0 28.0
3 S201910904 93 64 86.84 44.0 25.0
4 S201910905 93 56 42.11 0.0 20.0
4.3. DataFrame 處理遺漏值
在現實世界的資料集中,遺漏值(Missing Values)是非常常見的情況。不管你的資料是來自問卷調查、感測器讀取,還是從網路下載,都可能會有一些資料缺失的情況。Pandas 提供了多種方法來檢查和處理這些遺漏值,以下是一些常用的方法:
4.3.1. 觀察遺失狀況
不要只想著你可以用眼睛看資料來找遺漏值,因為當資料量很大時,這樣做是非常不切實際的。
我們可以使用以下幾個函數來檢查 DataFrame 中的遺漏值:
- isnull(): 用來檢查 DataFrame 中的遺漏值,並傳回一個布林值的 DataFrame,True 表示該值為 NaN,False 表示該值不是 NaN。
- notnull(): 傳回一個與原資料相同大小的布林值 DataFrame,其中 True 表示資料為 NaN。
- any(): 一個常用於處理布林值資料的函數,它用來檢查在一個特定的軸(列或行)上,是否有 任何一個值 為 True。這在處理遺漏值時特別有用,因為你可以用它來檢查一個 DataFrame 的每一行或每一列中是否存在至少一個 True 值(例如:NaN 值)。
1: import pandas as pd 2: docURL = 'https://letranger.github.io/PythonCourse/scores-null.csv' 3: df = pd.read_csv(docURL) 4: 5: print("====原始資料====") 6: print(df) 7: # 查詢遺失值狀況 8: print('====遺失值====') 9: print(df.isnull()) 10: print(df.isnull().sum())
====原始資料====
id classparti typing homework finalExam
0 201910901 100.0 72.0 92.11 48.0
1 201910902 96.0 56.0 93.42 60.0
2 201910903 96.0 76.0 102.63 NaN
3 201910904 NaN 64.0 86.84 44.0
4 201910905 93.0 56.0 42.11 0.0
5 201910906 101.0 108.0 100.00 NaN
6 201910907 101.0 NaN 92.11 55.0
7 201910908 94.0 68.0 105.26 61.0
8 201910909 NaN 64.0 44.74 20.0
9 201910910 93.0 120.0 97.37 16.0
====遺失值====
id classparti typing homework finalExam
0 False False False False False
1 False False False False False
2 False False False False True
3 False True False False False
4 False False False False False
5 False False False False True
6 False False True False False
7 False False False False False
8 False True False False False
9 False False False False False
id 0
classparti 2
typing 1
homework 0
finalExam 2
dtype: int64
4.3.2. dropna()
在確定資料中有遺失值之後,接下來就要考慮如何處理這些遺失值。最簡單的方法就是刪除這些包含遺失值的行或列,Pandas 提供了 dropna() 方法來實現這個功能。
什麼?刪除?
是的,直接刪除!雖然聽起來有點殘酷,但在某些情況下,刪除包含遺失值的行或列是最有效的方法,特別是當遺失值的比例很小時。當然,在刪除之前,你應該先評估這樣做是否會對你的分析結果產生重大影響。
dropna()就是用來刪除包含遺失值的行或列的方法。以下是 dropna() 方法的主要參數說明:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
- axis: 指定刪除的方向。axis=0 刪除包含遺失值的行,axis=1 刪除包含遺失值的列,預設為 0(行)。
- how: 確定是否刪除的條件。how=’any’ 表示只要行或列中有一個 NaN 就刪除,how=’all’ 表示必須全部是 NaN 才刪除,預設為 ’any’。
- thresh: 保留至少有 thresh 個非 NaN 的行或列。
- subset: 只在特定列中尋找遺失值。
- inplace: 是否在原 DataFrame 中直接修改,True 表示在原地修改,False 則返回一個新的 DataFrame。
1: import pandas as pd 2: docURL = 'https://letranger.github.io/PythonCourse/scores-null.csv' 3: df = pd.read_csv(docURL) 4: print("====原始資料====") 5: print(df.shape) 6: print("====刪除有遺失值的記錄====") 7: df0 = df.dropna() 8: print(df0.shape) 9: print(df.shape) #原來的df不受影響 10: df.dropna(inplace=True) 11: print(df.shape) #原來的df被改掉了QQ
====原始資料==== (10, 5) (5, 5) (10, 5) (5, 5)
4.3.3. fillna()
當然,有些情況下,刪除遺失值並不是一個好選擇,特別是當遺失值的比例較高時。或者,你在處理學生的段考資料,有幾個學生有某幾科缺考,你總不能把這些學生整個刪掉吧?這時候,我們可以選擇用某個值來填補這些遺失值,Pandas 提供了 fillna() 方法來實現這個功能。
fillna() 方法允許你指定一個值或方法來填補 DataFrame 中的遺失值。以下是 fillna() 方法的主要參數說明:
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None)
- value: 用來填補遺失值的值,這個值可以是單個標量或字典來指定每列不同的填補值。
- method: 填補方法,例如 ffill 代表用前一個有效值填補,bfill 代表用後一個有效值填補。
- axis: 指定填補的方向,axis=0 填補行,axis=1 填補列,預設為 0(行)。
- inplace: 是否直接修改原 DataFrame,預設為 False。
- limit: 限制每一行或每一列最多填補幾個遺失值。
1: import pandas as pd 2: docURL = 'https://letranger.github.io/PythonCourse/scores-null.csv' 3: df = pd.read_csv(docURL) 4: 5: print("====原始資料====") 6: print(df) 7: 8: fill0 = df.fillna(0) 9: print("====遺失值填零====") 10: print(fill0) 11: fillv = df.fillna({"classparti":999, "typing":0, "finalExam":"NULL"}) 12: print("====遺失值填特定值====") 13: print(fillv)
====原始資料====
id classparti typing homework finalExam
0 201910901 100.0 72.0 92.11 48.0
1 201910902 96.0 56.0 93.42 60.0
2 201910903 96.0 76.0 102.63 NaN
3 201910904 NaN 64.0 86.84 44.0
4 201910905 93.0 56.0 42.11 0.0
5 201910906 101.0 108.0 100.00 NaN
6 201910907 101.0 NaN 92.11 55.0
7 201910908 94.0 68.0 105.26 61.0
8 201910909 NaN 64.0 44.74 20.0
9 201910910 93.0 120.0 97.37 16.0
====遺失值填零====
id classparti typing homework finalExam
0 201910901 100.0 72.0 92.11 48.0
1 201910902 96.0 56.0 93.42 60.0
2 201910903 96.0 76.0 102.63 0.0
3 201910904 0.0 64.0 86.84 44.0
4 201910905 93.0 56.0 42.11 0.0
5 201910906 101.0 108.0 100.00 0.0
6 201910907 101.0 0.0 92.11 55.0
7 201910908 94.0 68.0 105.26 61.0
8 201910909 0.0 64.0 44.74 20.0
9 201910910 93.0 120.0 97.37 16.0
====遺失值填特定值====
id classparti typing homework finalExam
0 201910901 100.0 72.0 92.11 48.0
1 201910902 96.0 56.0 93.42 60.0
2 201910903 96.0 76.0 102.63 NULL
3 201910904 999.0 64.0 86.84 44.0
4 201910905 93.0 56.0 42.11 0.0
5 201910906 101.0 108.0 100.00 NULL
6 201910907 101.0 0.0 92.11 55.0
7 201910908 94.0 68.0 105.26 61.0
8 201910909 999.0 64.0 44.74 20.0
9 201910910 93.0 120.0 97.37 16.0
4.4. [課堂練習] TNFSH
以下列程式碼讀取線上資料檔,然後完成下列任務
- print出原始資料,觀察數據中是否有遺漏值。
- 使用 isnull() 和 notnull() 來檢查 DataFrame 中的遺漏值。顯示哪些欄位包含遺漏值。
- 列出成績不完整(有缺失值)的學生姓名
- 使用 dropna() 刪除包含遺漏值的學生記錄,並顯示刪除後的結果。
- 使用 fillna() 將遺漏值填充為平均值或其他特定值。依續以下列幾種填充方式:
- 科學、地理兩科缺考者一律給60分。
- 使用 0 填充其他所有遺漏值。
- 科學、地理兩科缺考者一律給60分。
4.4.1. 參考
1: import pandas as pd 2: docURL = 'https://letranger.github.io/PythonCourse/prac_scores.csv' 3: df = pd.read_csv(docURL) 4: print(df.head())
數學 英文 科學 歷史 地理 姓名
0 NaN 76.0 84.0 96.0 56.0 學生1
1 78.0 NaN 63.0 73.0 58.0 學生2
2 64.0 77.0 66.0 75.0 57.0 學生3
3 92.0 NaN 85.0 74.0 61.0 學生4
4 57.0 64.0 99.0 94.0 83.0 學生5
4.5. [課堂練習]成績表操作 TNFSH
使用以下資料建立 DataFrame,完成指定任務:
指定 seed:
1: import pandas as pd 2: import numpy as np 3: np.random.seed(8888) 4: 5: data = { 6: '姓名': ['小明', '小華', '小美', '小強', '小玲', '小偉', '小芳', '小傑'], 7: '國文': np.random.randint(50, 100, 8), 8: '英文': np.random.randint(40, 100, 8), 9: '數學': np.random.randint(30, 100, 8), 10: } 11: df = pd.DataFrame(data)
任務:
- 新增「總分」欄位(國文+英文+數學)
- 按總分由高到低排序
- 篩選出數學不及格(<60)的同學
- 計算各科平均分數
結果範例
=== 原始成績表 === 姓名 國文 英文 數學 0 小明 53 91 51 1 小華 85 49 91 2 小美 58 78 30 3 小強 91 99 84 4 小玲 50 68 70 5 小偉 94 71 67 6 小芳 98 69 68 7 小傑 65 51 98 === 1. 新增總分欄位 === 姓名 國文 英文 數學 總分 0 小明 53 91 51 195 1 小華 85 49 91 225 2 小美 58 78 30 166 3 小強 91 99 84 274 4 小玲 50 68 70 188 5 小偉 94 71 67 232 6 小芳 98 69 68 235 7 小傑 65 51 98 214 === 2. 按總分排序 === 姓名 國文 英文 數學 總分 3 小強 91 99 84 274 6 小芳 98 69 68 235 5 小偉 94 71 67 232 1 小華 85 49 91 225 7 小傑 65 51 98 214 0 小明 53 91 51 195 4 小玲 50 68 70 188 2 小美 58 78 30 166 === 3. 數學不及格的同學 === 姓名 數學 0 小明 51 2 小美 30 === 4. 各科平均分數 === 國文: 74.2 英文: 72.0 數學: 69.9
5. Dataframe 的選取與過濾
比起Python內建的資料結構,Pandas的DataFrame提供了更多方便的資料選取與過濾功能。這些功能讓使用者能夠更靈活地操作資料,進行各種分析與處理。以下將介紹幾種常用的選取與過濾方法。
5.1. 資料選取:選取欄位 (Column)
- 使用 df[’column_name’] 來選取單個欄位
這種方式傳回的是一個 Series,適用於只選取一個欄位的情況。這種方法最為直觀,當你知道欄位名稱時,直接使用 df[’column_name’] 即可。 - 使用
df[['col1', 'col2']]選取多個欄位
如果需要一次選取多個欄位,可以將多個欄位名稱放入一個列表中,再傳入 DataFrame 中。這樣做會傳回一個新的 DataFrame,並且可以進行進一步操作,例如使用 head() 來查看前幾行的數據。 - 使用 df.column_name 的簡寫方式
這是一種更簡潔的語法,它只適用於列名為有效的 Python 識別符時(例如,列名中沒有空格或特殊字符)。通過 df.column_name 來選取欄位和 df[’column_name’] 效果相同,傳回一個 Series。
5.1.1. 範例
1: import pandas as pd 2: docURL = 'https://letranger.github.io/PythonCourse/scores.csv' 3: df = pd.read_csv(docURL) 4: 5: print(df.head(3)) 6: # 以 df.column name來選欄位 7: print('=== df.id ===') 8: print(df.id) 9: # 以 df[['column']] 來選欄位 10: print("=== df[['id']] ===") 11: print(df[['id']]) 12: # df[['id', 'typing']]的結果仍是dataframe,後面可以再加上dataframe的function 13: print(df[['id', 'typing']].head(3)) 14: # 以 df.column 來選欄位 15: print(df.id, df.homework)
id classparti typing homework midexam finalexam
0 S201910901 100 72 92.11 48.0 16.0
1 S201910902 96 56 93.42 60.0 40.0
2 S201910903 96 76 102.63 45.0 28.0
=== df.id ===
0 S201910901
1 S201910902
2 S201910903
3 S201910904
4 S201910905
...
207 S201911726
208 S201911727
209 S201911728
210 S201911729
211 S201911730
Name: id, Length: 212, dtype: object
=== df[['id']] ===
id
0 S201910901
1 S201910902
2 S201910903
3 S201910904
4 S201910905
.. ...
207 S201911726
208 S201911727
209 S201911728
210 S201911729
211 S201911730
[212 rows x 1 columns]
id typing
0 S201910901 72
1 S201910902 56
2 S201910903 76
0 S201910901
1 S201910902
2 S201910903
3 S201910904
4 S201910905
...
207 S201911726
208 S201911727
209 S201911728
210 S201911729
211 S201911730
Name: id, Length: 212, dtype: object 0 92.11
1 93.42
2 102.63
3 86.84
4 42.11
...
207 102.63
208 102.63
209 102.63
210 105.26
211 102.63
Name: homework, Length: 212, dtype: float64
5.2. 資料選取:使用索引選取列 (Row)
在資料處理與分析中,Pandas 提供了方便的方法來根據列索引或條件選取 DataFrame 中的資料列。這讓使用者能夠靈活地篩選與操作資料,進行更精細的分析。
- 使用索引範圍選取資料列
Pandas 支援使用索引範圍來選取 DataFrame 的資料列。類似於 Python 的切片語法:
- df[start:end] : 選取第 start 到 end 行的資料。這種方法非常直觀,用於選取連續的一組資料列。
- df[start:end] : 選取第 start 到 end 行的資料。這種方法非常直觀,用於選取連續的一組資料列。
- 使用條件選取資料列
除了直接選取特定的資料列,Pandas 也允許使用條件來篩選資料:
- df[condition] :可以選取符合條件的資料。例如,篩選出作業成績小於 30 的學生記錄。
- 可以用df.column_name來表示條件
- df[condition] :可以選取符合條件的資料。例如,篩選出作業成績小於 30 的學生記錄。
- 合併列索引與欄位條件
我們還可以結合列索引與欄位條件來選取資料。例如,使用條件選取特定列後,再篩選出符合條件的資料列,進行進一步操作。
5.2.1. 範例
1: import pandas as pd 2: docURL = 'https://letranger.github.io/PythonCourse/scores.csv' 3: df = pd.read_csv(docURL) 4: 5: # 以row index來選取資料 6: print(df[1:3]) 7: # 以條件來選取資料 8: print(df[df.homework<30]) 9: # 合併row and column兩項條件 10: print(df.id[df.homework<30]) 11: print(df[['id', 'homework']][1:3])
id classparti typing homework midexam finalexam
1 201910902 96 56 93.42 60.0 40.0
2 201910903 96 76 102.63 45.0 28.0
id classparti typing homework midexam finalexam
10 201910911 62 44 20.39 4.0 0.0
18 201910919 14 56 25.92 0.0 0.0
23 201910924 75 48 10.75 0.0 0.0
124 201911315 71 120 15.35 0.0 0.0
140 201911331 93 120 25.88 0.0 16.0
10 201910911
18 201910919
23 201910924
124 201911315
140 201911331
Name: id, dtype: int64
id homework
1 201910902 93.42
2 201910903 102.63
5.3. 條件式選取資料
- 單一條件篩選
需要根據單一條件篩選資料時:
- df[condition]: 傳回一個新的 DataFrame,包含所有符合條件的資料列。
- df[condition]: 傳回一個新的 DataFrame,包含所有符合條件的資料列。
- 多條件篩選
如果你需要根據多個條件來篩選資料,可以使用邏輯運算符來結合條件:
- df[(condition)]
- df[(condition 1) & (condition 2) ] : 使用 & 代表「且」的邏輯運算符,表示同時滿足兩個條件。
- df[(condition 1) | (condition 2) ] : 使用 | 代表「或」的邏輯運算符,表示滿足任一條件。
- 使用多個條件時,必須 將每個條件放在括號內 ,這樣才能正確解析每個條件的優先級。
- df[(condition)]
5.3.1. 範例
1: import pandas as pd 2: 3: docURL = 'https://letranger.github.io/PythonCourse/scores.csv' 4: df = pd.read_csv(docURL) 5: 6: print(df[(df.midexam >= 100) & (df.finalexam >= 100)])
id classparti typing homework midexam finalexam
11 S201910912 87 92 92.11 110.8 103.75
70 S201911034 104 92 102.63 100.8 101.00
88 S201911115 120 88 105.26 113.5 111.00
98 S201911125 119 80 107.89 113.2 115.00
102 S201911129 106 52 102.63 103.6 100.00
127 S201911318 108 80 102.63 104.8 100.00
138 S201911329 105 48 107.89 100.0 100.00
143 S201911334 100 120 81.58 104.8 113.00
153 S201911608 88 0 102.63 100.0 100.00
169 S201911624 82 100 102.63 101.5 105.00
182 S201911701 103 108 92.63 100.0 100.00
189 S201911708 106 108 102.63 107.2 101.00
190 S201911709 108 88 107.89 104.8 105.00
191 S201911710 102 100 102.63 100.0 105.00
193 S201911712 105 96 101.58 107.5 100.00
195 S201911714 102 44 107.89 110.0 110.00
196 S201911715 106 120 107.89 102.4 105.00
198 S201911717 80 120 107.89 106.0 100.00
201 S201911721 109 76 100.00 100.0 100.00
203 S201911722 105 120 102.63 101.5 105.00
210 S201911729 87 84 105.26 112.3 103.00
5.4. 進階條件過濾[loc/iloc]
在 Pandas 中,除了基本的索引與條件篩選,loc 和 iloc 提供了更加靈活且強大的資料篩選功能。這些方法允許我們根據行標籤、列標籤,或者純粹基於數值索引來選取資料。此外,between 方法則可以用來方便地篩選特定區間內的數值。
先來看看 loc 和 iloc 的差異:
| 特性 | loc |
iloc |
|---|---|---|
| 索引方式 | 用標籤(名稱)選取 | 用整數位置選取 |
| 語法 | df.loc[row_label, col_label] |
df.iloc[row_index, col_index] |
| 切片範圍 | 頭尾都包含(=’a’:’c’= 包含 c) | 包含頭、不包含尾(=0:3= 不含 3) |
| 適用情境 | 你知道欄位名稱或列標籤時 | 你知道確切位置(第幾列第幾行)時 |
簡單來說:用名字找就用 loc ,用位置編號找就用 iloc 。
5.4.1. loc, iloc, between 4
5.4.1.1. loc
- 用法:df.loc[row_label, column_label]
- 這種方式是基於標籤(label)的選取,適合用於對特定行列進行精準選取。基於行標籤和列標籤(x_label、y_label)進行索引,以 column 名做為 index
1: import pandas as pd 2: 3: # 從遠端讀取 CSV 檔案 4: docURL = 'https://letranger.github.io/PythonCourse/scores.csv' 5: df = pd.read_csv(docURL) 6: 7: # 查看前3行資料 8: print(df.head(3)) 9: print("========") 10: 11: # 使用 loc 選取 'homework' 小於 25 的資料,並只顯示 'id' 和 'homework' 兩個欄位 12: print(df.loc[df.homework < 25, ['id', 'homework']]) 13: print("========") 14: 15: # 使用 loc 選取第 2 行的 'homework' 欄位數值 16: print(df.loc[2, 'homework'])
id classparti typing homework midexam finalexam
0 S201910901 100 72 92.11 48.0 16.0
1 S201910902 96 56 93.42 60.0 40.0
2 S201910903 96 76 102.63 45.0 28.0
========
id homework
10 S201910911 20.39
23 S201910924 10.75
124 S201911315 15.35
========
102.63
5.4.1.2. iloc
- iloc 是基於行索引和列索引的數字位置來選取資料。這種方法使用索引的數值來選擇資料,從 0 開始計數,適合在你知道具體位置而非標籤時使用。
- 用法:df.iloc[row_index, column_index]
- 索引都是基於數字的位置,而不是標籤。
1: import pandas as pd 2: 3: # 從遠端讀取 CSV 檔案 4: docURL = 'https://letranger.github.io/PythonCourse/scores.csv' 5: df = pd.read_csv(docURL) 6: 7: # 使用 iloc 選取前 3 行資料 8: print(df.iloc[:3]) 9: 10: # 使用 iloc 選取前 2 行的第 2 和第 3 欄資料 11: print(df.iloc[:2, 1:3])
id classparti typing homework midexam finalexam
0 S201910901 100 72 92.11 48.0 16.0
1 S201910902 96 56 93.42 60.0 40.0
2 S201910903 96 76 102.63 45.0 28.0
classparti typing
0 100 72
1 96 56
5.4.1.3. between
- between 方法可以用來篩選特定區間內的數值資料。例如,如果你需要篩選出某列的值位於某個範圍之間,可以使用 between 方法。
- 用法:df[’column’].between(left, right, inclusive=True)
- 這種方法會傳回布林值序列,表示每個值是否位於指定範圍內。
1: import pandas as pd 2: 3: # 從遠端讀取 CSV 檔案 4: docURL = 'https://letranger.github.io/PythonCourse/scores.csv' 5: df = pd.read_csv(docURL) 6: 7: # 使用 between 方法篩選期中考成績在 50 到 60 之間的資料 8: print(df['midexam'].between(50, 60)) 9: 10: # 篩選期中考成績在 50 到 55 之間的學生資料 11: midFilter = df['midexam'].between(50, 55) 12: print(df[midFilter]) 13:
0 False
1 True
2 False
3 False
4 False
...
207 False
208 False
209 False
210 False
211 False
Name: midexam, Length: 212, dtype: bool
id classparti typing homework midexam finalexam
6 S201910907 101 120 92.11 55.0 20.0
65 S201911029 93 60 82.00 50.0 16.0
72 S201911036 88 80 102.63 53.0 76.0
92 S201911119 82 104 89.47 50.0 20.0
94 S201911121 95 100 88.51 52.0 72.0
109 S201911136 91 100 81.58 51.0 4.0
171 S201911626 98 72 97.37 50.0 75.0
6. 進階分析
6.1. 由其他 column 產生新的 column(重要、實用)
在資料分析過程中,我們經常需要從現有的資料欄位中計算出新的欄位,以便進行進一步的分析。Pandas 提供了靈活且簡便的方法來根據現有欄位生成新的欄位,這可以應用在加總、條件篩選和分組操作上。
6.1.1. 生成新欄位 - 全部指定
我們可以使用運算符來操作 DataFrame 的欄位,並將結果存入新的欄位。這種方式適合應用於所有資料列,並且可以用於進行數值運算。
6.1.1.1. 範例: 生成新欄位 Final(學期總分)
1: import pandas as pd 2: 3: # 讀取csv 4: docURL = 'https://letranger.github.io/PythonCourse/scores.csv' 5: df = pd.read_csv(docURL) 6: 7: # 計算學期總分,並生成新欄位 'Final' 8: df['Final'] = df.classparti * 0.1 + df.typing * 0.1 + df.homework * 0.2 + df.midexam * 0.3 + df.finalexam * 0.3 9: 10: # 查看新增的欄位 11: print(df.head())
id classparti typing homework midexam finalexam Final
0 S201910901 100 72 92.11 48.0 16.0 54.822
1 S201910902 96 56 93.42 60.0 40.0 63.884
2 S201910903 96 76 102.63 45.0 28.0 59.626
3 S201910904 93 64 86.84 44.0 25.0 53.768
4 S201910905 93 56 42.11 0.0 20.0 29.322
6.1.2. 生成新欄位 - 條件指定
我們還可以根據條件來生成新欄位。使用 loc 方法,可以根據某欄位的值來篩選資料,並指定符合條件的資料對應的欄位值。例如,可以依據成績來指定 PASS 或 FAIL 狀態,或者依據打字速度來分類為 LOW、MID、HIGH。
6.1.2.1. 範例: 依條件新增欄位 PASS 和 TypingSpeed
1: # 依學期總分新增一個欄位 'PASS' 2: df.loc[df.Final < 60, 'PASS'] = False 3: df.loc[df.Final >= 60, 'PASS'] = True 4: 5: # 依據打字速度新增一個分類欄位 'TypingSpeed' 6: df.loc[df.typing < 30, 'TypingSpeed'] = 'LOW' 7: df.loc[df.typing.between(30, 60), 'TypingSpeed'] = 'MID' 8: df.loc[df.typing > 60, 'TypingSpeed'] = 'HIGH' 9: 10: # 查看結果 11: print(df.head(3))
id classparti typing homework midexam finalexam Final PASS TypingSpeed
0 S201910901 100 72 92.11 48.0 16.0 54.822 False HIGH
1 S201910902 96 56 93.42 60.0 40.0 63.884 True MID
2 S201910903 96 76 102.63 45.0 28.0 59.626 False HIGH
6.2. 資料型別轉換:astype()
在處理資料時,有時候欄位的型別不是你要的(例如數字被讀成字串),這時候就需要用 astype() 來轉換。
- 語法:
series.astype(dtype)或df.astype(dtype) - 常用 dtype 值:=int=,
float,str,'category'
1: # 把 score 欄位轉成浮點數 2: df['score'] = df['score'].astype(float) 3: 4: # 把學號轉成字串(方便後續做字串操作) 5: df['id'] = df['id'].astype(str) 6: 7: # 一次轉多個欄位 8: df = df.astype({'score': float, 'id': str})
6.3. 字串操作:.str 存取器
當 Series 裡面裝的是字串資料時,可以用 .str 存取器來對每個元素進行向量化的字串操作,不用自己寫迴圈。
常用方法:
| 方法 | 說明 | 範例 |
|---|---|---|
.str.contains() |
檢查是否包含特定字串 | df['name'].str.contains('王') |
.str.replace() |
取代字串 | df['tel'].str.replace('-', '') |
.str.split() |
分割字串 | df['addr'].str.split('市') |
.str.strip() |
去除前後空白 | df['name'].str.strip() |
.str.len() |
字串長度 | df['name'].str.len() |
.str.upper() |
轉大寫 | df['name'].str.upper() |
.str[start:end] |
字串切片 | =df[’id’].str[4:7]=(取第 5~7 碼) |
1: # 範例:從學號中取出班級代碼(假設學號第 5~7 碼是班級) 2: df['班級'] = df['學號'].astype(str).str[4:7] 3: 4: # 範例:把名字全部轉大寫 5: df['name'] = df['name'].str.upper()
注意:使用 .str 之前,要先確定該欄位的型別是字串。如果不是,先用 .astype(str) 轉換。
6.4. 交叉分析:分組與資料轉置
分組分析是資料分析的核心操作之一,Pandas 的 groupby() 可以把資料依照某個欄位分組,然後對每組進行統計運算。
df.groupby() 常用參數:
| 參數 | 說明 | 預設值 |
|---|---|---|
| by | 欄位名稱或名稱 list,用來分組 | (必填) |
| axis | 0 按列分組、=1= 按行分組 |
0 |
| sort | 是否對分組的 key 排序 | True |
| as_index | 分組欄位是否設為索引;=False= 則結果保持一般 DataFrame | True |
groupby() 後面常搭配聚合函式來計算各組的統計量:
.mean():平均值.sum():加總.count():計數.agg():同時套用多種聚合函式,如.agg(['mean', 'max'])
6.4.1. 範例:依打字速度分組與資料統計
1: # 依據打字速度分組,計算每組的學期總分平均值 2: print('---依打字速度分組---') 3: print(df.groupby('TypingSpeed')['Final'].mean()) 4: 5: # 依據 PASS 分組,計算打字成績和作業成績的平均值 6: print(df.groupby('PASS')[['typing', 'homework']].mean()) 7: 8: # 將結果轉置,查看不同分組下的平均打字成績和作業成績 9: print('---置換row/column(轉90度)---') 10: print(df.groupby('PASS')[['typing', 'homework']].mean().T)
---依打字速度分組---
TypingSpeed
HIGH 69.977451
LOW 68.517333
MID 64.086303
Name: Final, dtype: float64
typing homework
PASS
False 77.567568 76.409054
True 84.525547 96.350730
---置換row/column(轉90度)---
PASS False True
typing 77.567568 84.525547
homework 76.409054 96.350730
6.5. 資料檔下載: scores.csv
7. 資料視覺化
Pandas自己內建了一些簡單的繪圖功能,可以快速地將DataFrame資料視覺化。以下介紹幾種常用的圖表類型及其範例。
df.plot() 常用參數:
| 參數 | 說明 | 預設值 |
|---|---|---|
| kind | 圖表類型:=’line’, ='bar', 'barh', 'hist', 'box', 'scatter', 'pie' 等 |
'line' |
| x | 指定欄位名稱作為 x 軸 | None |
| y | 指定欄位名稱作為 y 軸 | None |
| figsize | 圖片大小(英吋),格式為 (寬, 高) |
None |
| title | 圖表標題 | None |
| rot | x 軸標籤旋轉角度 | None |
| legend | 是否顯示圖例 | True |
7.1. Bar chart
1: # 載入函式庫 2: import pandas as pd 3: import matplotlib.pyplot as plt 4: 5: # 讀取csv 6: docURL = 'https://letranger.github.io/PythonCourse/scores.csv' 7: df = pd.read_csv(docURL) 8: 9: # 計算總分 10: df['Final'] = df.classparti*.1 + df.typing*.1 + df.homework*.2 + df.midexam*.3 + df.finalexam*.3 11: 12: # create new column according to typing speed 13: df.loc[df.typing < 30, 'TypingSpeed' ] = 'Level-1' 14: df.loc[df.typing.between(30, 60), 'TypingSpeed' ] = 'Level-2' 15: df.loc[df.typing > 60, 'TypingSpeed' ] = 'Level-3' 16: 17: x = df.groupby('TypingSpeed')[['homework','classparti']].mean() 18: print(x) 19: # 關於圖表的屬性設定方式 20: fig = df.groupby('TypingSpeed')[['homework','classparti']].mean().plot(kind='bar', title="XXX", rot=0, legend=True) 21: fig.set_xlabel("Typing Speed") 22: fig.set_ylabel("score") 23: #savefig = fig.get_figure() # 如果不存圖檔就不用設定這行 24: # 關於圖表的屬性設定方式 25: fig1 = df.groupby('TypingSpeed')[['homework','classparti']].mean().T.plot(kind='bar', title="XXX", rot=0, legend=True) 26: fig1.set_xlabel("Subject") 27: fig1.set_ylabel("score") 28: #savefig1 = fig1.get_figure()# 如果不存圖檔就不用設定這行 29: 30: # 如果不存圖檔就不用執行以下程式 31: savefig.savefig('images/pandasPlot1.png', bbox_inches='tight') 32: savefig1.savefig('images/pandasPlot10.png', bbox_inches='tight')
homework classparti
TypingSpeed
Level-1 96.053333 87.666667
Level-2 85.273939 88.696970
Level-3 90.053920 93.159091
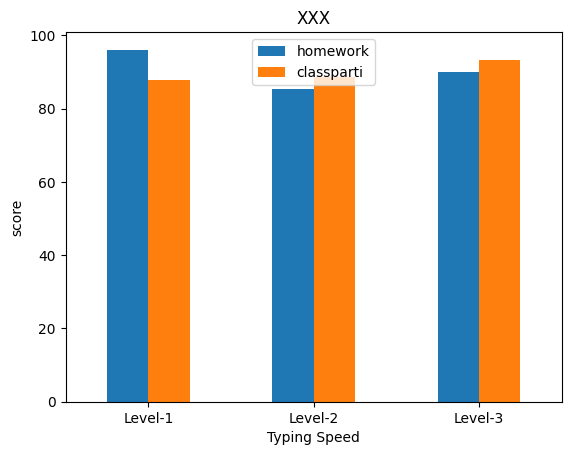
Figure 3: Pandas plot bar chart
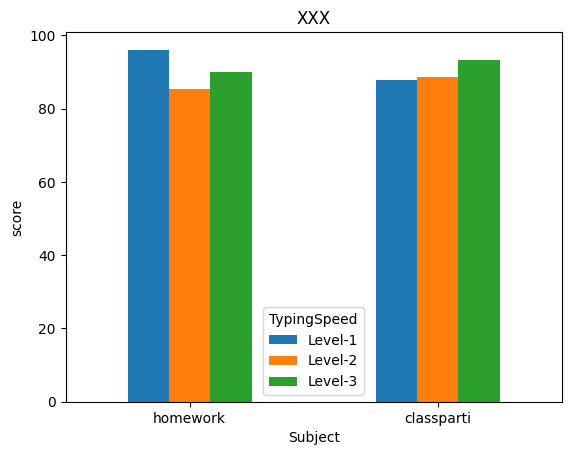
Figure 4: Pandas plot bar chart
7.2. Regression line chart
1: # 載入函式庫 2: import pandas as pd 3: import seaborn as sns 4: 5: # 讀取csv 6: docURL = 'https://letranger.github.io/PythonCourse/scores.csv' 7: df = pd.read_csv(docURL) 8: 9: sns.regplot(x="midexam", y='finalexam', data=df); 10: 11: #fig = sns.regplot(x="midexam", y='finalexam', data=df); 12: #savefig = fig.get_figure() 13: #savefig.savefig('images/PandasPlot4.png') 14:
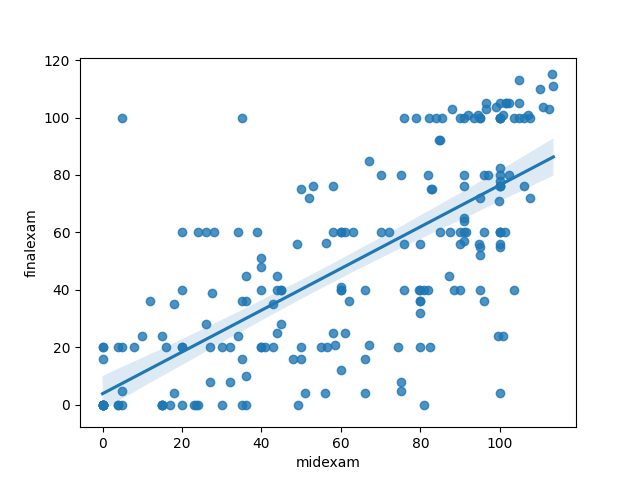
Figure 5: Pandas plot scatter chart
7.3. Pie chart
7.3.1. DEMO
1: # 載入函式庫 2: import pandas as pd 3: 4: # 讀取csv 5: docURL = 'https://letranger.github.io/PythonCourse/scores.csv' 6: df = pd.read_csv(docURL) 7: 8: # 計算總分 9: df['Final'] = df.classparti*.1 + df.typing*.1 + df.homework*.2 + df.midexam*.3 + df.finalexam*.3 10: 11: # create new column according to typing speed 12: df.loc[df.typing < 60, 'TypingSpeed' ] = 'Level-1' 13: df.loc[df.typing.between(60, 80), 'TypingSpeed' ] = 'Level-2' 14: df.loc[df.typing > 80, 'TypingSpeed' ] = 'Level-3' 15: print(df.groupby('TypingSpeed').count()) 16: df.groupby('TypingSpeed')['TypingSpeed'].count().plot(kind='pie', title="XXX", rot=0, legend=True) 17: # 如果不存圖檔就不用執行以下程式 18: #fig = df.groupby('TypingSpeed')['TypingSpeed'].count().plot(kind='pie', title="XXX", rot=0, legend=True) 19: #savefig = fig.get_figure() 20: #savefig.savefig('images/pandasPlot2.png', bbox_inches='tight')
id classparti typing homework midexam finalexam Final
TypingSpeed
Level-1 25 25 25 25 25 25 25
Level-2 86 86 86 86 86 86 86
Level-3 101 101 101 101 100 101 100
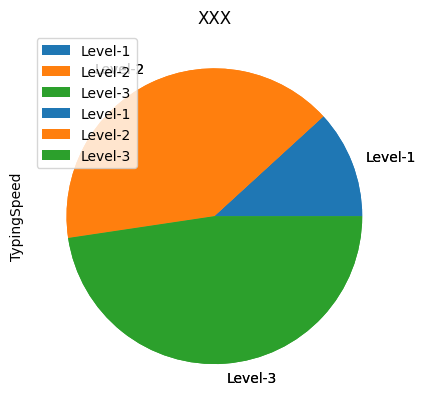
Figure 6: Pandas plot pie chart
7.3.2. 如何避免圖例擋住圖表
7.4. Scatter chart
1: # 載入函式庫 2: import pandas as pd 3: 4: # 讀取csv 5: docURL = 'https://letranger.github.io/PythonCourse/scores.csv' 6: df = pd.read_csv(docURL) 7: 8: df[['midexam','finalexam']].plot(kind='scatter', x=1, y=0) 9: fig = df[['midexam','finalexam']].plot(kind='scatter', x=1, y=0) 10: 11: # 如果不存圖檔就不用執行以下程式 12: #savefig = fig.get_figure() 13: #savefig.savefig('images/PandasPlot3.png')
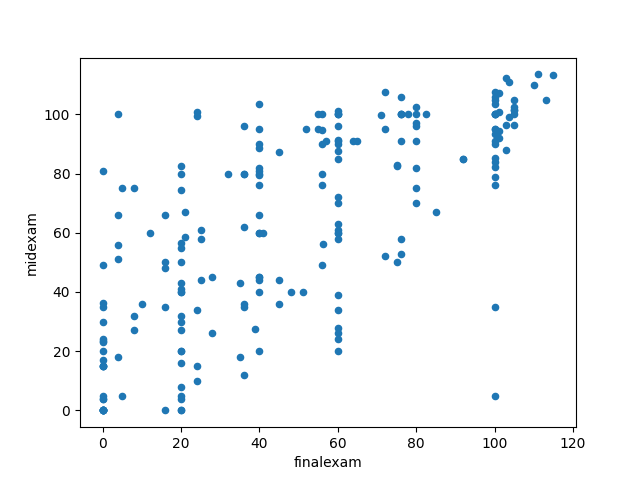
Figure 7: Pandas plot scatter chart
7.5. 六角箱圖 (Hexbin Chart)
1: # 載入函式庫 2: import pandas as pd 3: 4: # 讀取csv 5: docURL = 'https://letranger.github.io/PythonCourse/scores.csv' 6: df = pd.read_csv(docURL) 7: 8: df[['midexam','finalexam']].plot(kind='hexbin', x=1, y=0, gridsize=25) 9: 10: fig = df[['midexam','finalexam']].plot(kind='hexbin', x=1, y=0, gridsize=25) 11: #savefig = fig.get_figure() 12: #savefig.savefig('images/PandasPlot6.png')
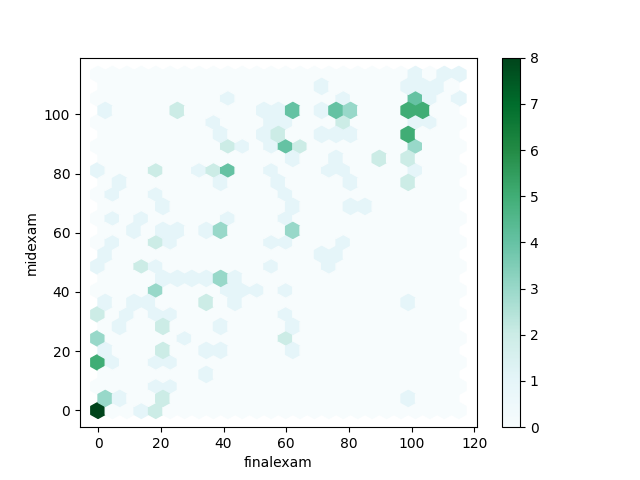
Figure 8: Pandas plot hexbin chart
8. [作業] TNFSH
8.1. 403期中考得分統計
- 原始數據
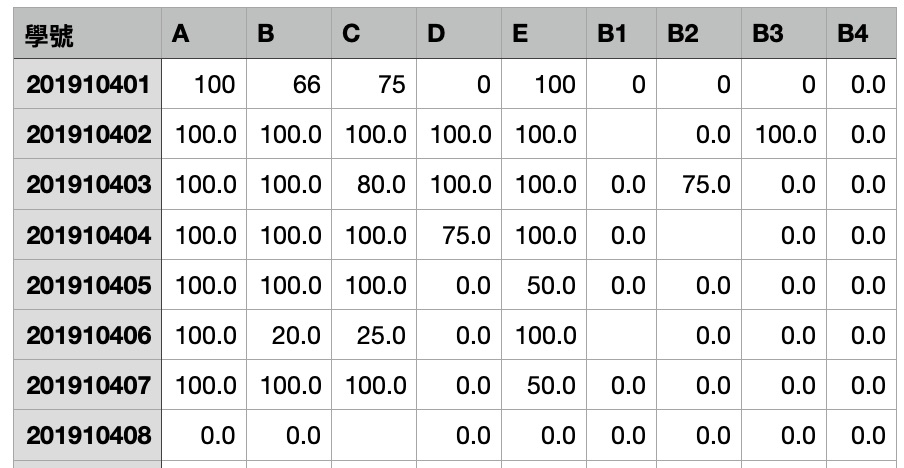
Figure 9: CSV 內容
- cs109score.csv為 T 市某校的資訊科線上期中考系統所匯出的成績檔,該次考試共計 10 題,其中
- 前 5 題(A,B,C,D,E)為基本題,每題 100 分,
- 後 4 題為加分題(Bonus1~Bonus4),每題 25 分
- 本份考卷總分:600;
- 總得分除以 5 即為期中考得分
- 此次期中考總分 120分。
- 前 5 題(A,B,C,D,E)為基本題,每題 100 分,
8.1.1. 任務 1 (10%):
- 將有缺失值的部份以 0 分取代。
- 直接輸出前10筆資料
8.1.2. 任務 2 (20%):
- 求出每個人的原始總分(即所有分數),新增的欄位名稱為TOTAL
- 新增欄位SCORE, 其值為每個人的實際得分(原始總分TOTAL除以 5)
- 直接輸出前10筆資料
8.1.3. 任務 3 (20%)
- 新增班級欄位(已知學號的前四碼為入學年份、接下來的三碼為班級、末兩碼為座號)
- 輸出前10筆資料(依SCORE由高到低排序)
8.1.4. 任務 4 (10%):
求所有受試者第 B 及 B1 兩題的 scatter plot 以及 regression line。如下圖:
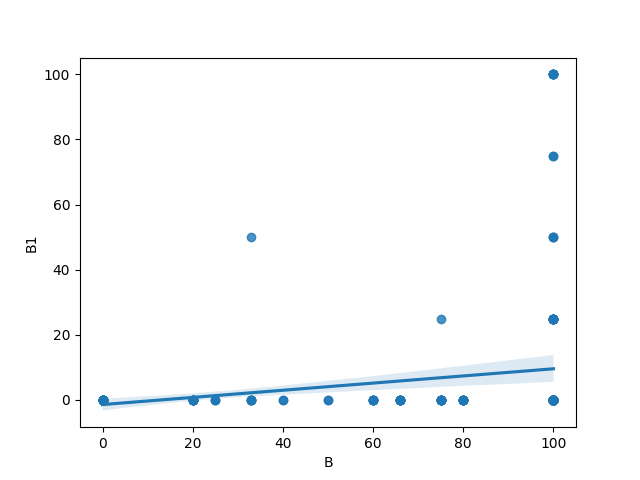
Figure 10: 任務3
8.1.5. 任務 5 (20%):
- 新增ABILITY欄位,依以下條件填入類別
- SCORE <= 50, ABILITY: ’LEVEL-1’
- 50 < SCORE < 80, ABILITY: ’LEVEL-2’
- SCORE >= 80, ABILITY: ’LEVEL-3’
- SCORE <= 50, ABILITY: ’LEVEL-1’
8.1.6. 任務 6 (20%):
交叉分析,依ABILITY分組,查看此三組學生的前三題(A, B, C)得分情況,並繪製圖表
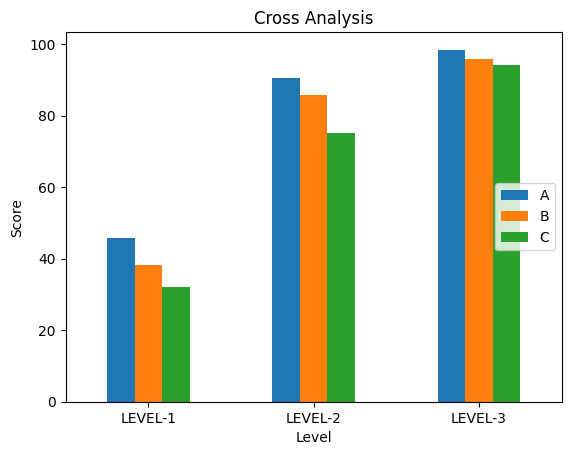
Figure 11: 任務5
8.2. 進階練習
一dataframe如下
import numpy as np import pandas as pd scores = {'Math': [900, 50, 70, 80], 'English': [60, 30, 90, 50], 'History': [33, 75, np.NaN, np.NaN]} df = pd.DataFrame(scores, index=['Simon', 'Allen', 'Jimmy', 'Vanessa'])
試解決以下問題:
- 列出Math分數>100資料
- 將Simon之Math改為90分
- 計算History遺漏值筆數
- 以History平均值取代History中遺漏值
- 新增“平均”欄位,計算四人各科平均
- 新增“名次”欄位,以四人平均分數為排序依據
- 列出平均不及格者
- 列出數學最高分者姓名