時間序列的預言者:如何以RNN預測未來
Table of Contents

1. CNN的限制
在前面介紹CNN的章節中,我們提過CNN的想法源自於對人類大腦認知方式的模仿,當我們辨識一個圖像,會先注意到顏色鮮明的點、線、面,之後將它們構成一個個不同的形狀(眼睛、鼻子、嘴巴 …),這種抽象化的過程就是 CNN 演算法建立模型的方式。其過程如圖11。
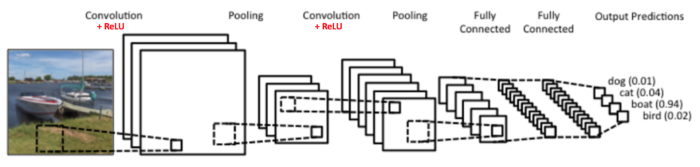
Figure 1: CNN 概念
至於圖片中的每一個特徵則是利用卷積核來取得(如圖2),換言之,CNN其實是在模擬人類的眼睛。也就是說,CNN的設計是為了處理靜態的、空間上有結構的資料,例如圖像、影像等,它所關注的是資料間的空間關係,例如圖2中卷積核(紅色矩陣)中各個pixel與鄰近pixel間的關係。
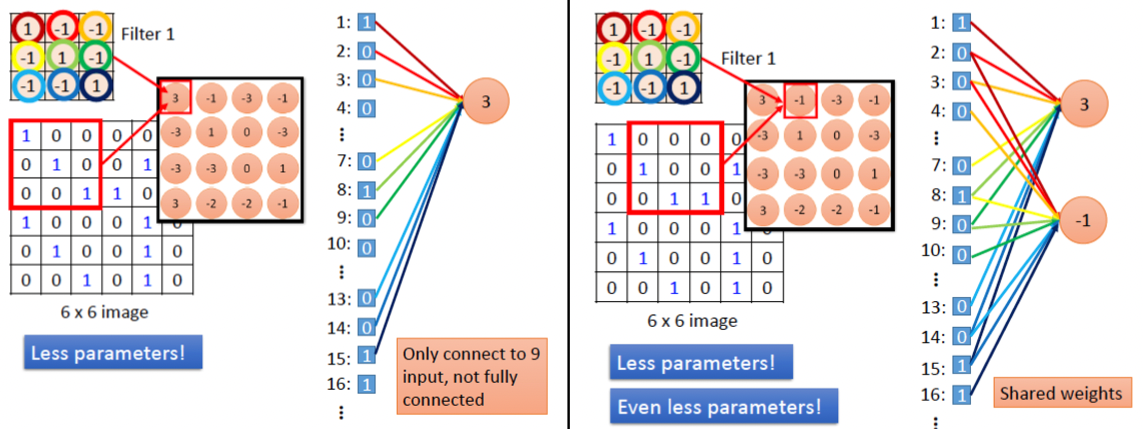
Figure 2: CNN原理
萬一我們所要處理的資料並不是一張張的圖、而是一系列連續性、有時間順序的資料呢?例如:
- 一篇文章: 也許我們想生成這篇文章的摘要
- 一段時間內蒐集的某地PM 2.5數值: 也許我們想預測該地下週的PM 2.5
- 一段演講錄音: 也許我們想生成逐字稿
你會發現,這類資料其實不太適合用眼睛,可能更適合用耳朵(關注連續資料間的關係),所以拿CNN來分析這類資料大概是用錯了工具。
那麼,哪一種模型比較適合模擬出人類的耳朵功能?這是本節的討論重點。
2. RNN
2.1. RNN的基本概念
回顧我們熟悉的CNN神經網路(如圖3),資料一律由模型的左側layer往右側傳送;而圖4的RNN則有點不同,每一層的神經元在將資料往右傳遞的同時,還偷偷留了一份給 自己 (參考圖中的紅色實線) ,這裡說的自己不是真正的自己,而是 下一個回合的自己 ) 。
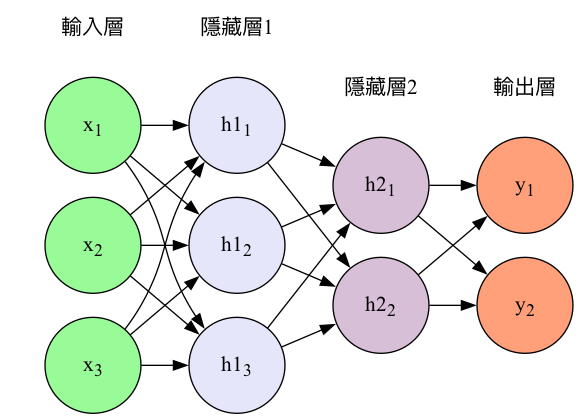
Figure 3: CNN模型架構
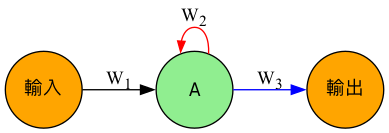
Figure 4: 一個簡單的RNN模型
事實上,比起圖4,我們平常更常看到的RNN模型是如圖5所示的展開架構:
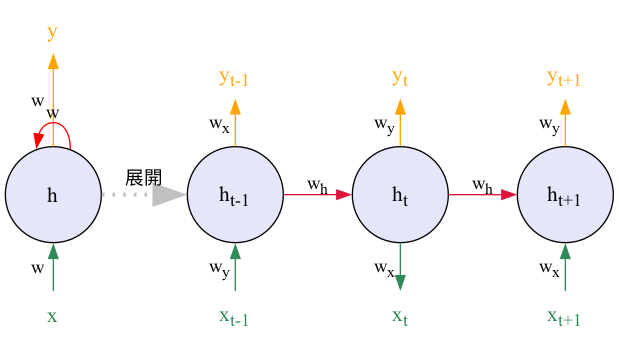
Figure 5: RNN模型的展開架構
要看懂圖5,你只要搞清楚三件事:
- 不像CNN那樣每次讀入一整張圖,RNN會 逐步讀入 一連串有時間順序的資料,如文字、每天的PM 2.5數值、每秒的股價變化等,而不是一次性將整串資料全部計算完。第1次(也就是第1個時間點(\(t_0\))讀入\(x_0\)、第2次(也就是第2個時間點(\(t_1\))讀入\(x_1\)…
- 原本常見的資料在模型中傳遞方向是由左而右,在圖5中這我們用“自下而上”來代表每個時間點的輸入(下方),輸出(上方),這只是圖的表示方法,不影響實際運算。也就是說輸入資料是底下的\(x_t\)、輸出為上面的\(h_t\)。
- 圖5中右側「展開後」的三個神經元其實是 同一個神經元 在不同時間點的重複使用。這裡的重點是: 三個神經元分別代表不同時間點的神經元 ,而 \(x_{t-1}, x_{t}, x_{t+1}\) 則代表在不同時間點的輸入;\(y_{t-1}, y_{t}, y_{t+1}\) 則代表在不同時間點的輸出。至於 \(h_{t-1}, h_{t}, h_{t+1}\) 則較為複雜,我們稍後再說明。
2.2. RNN神經元內部結構
為了讓大家能更清楚地了解RNN的運作原理,我們將圖5中的RNN神經元進一步展開,如圖6所示:
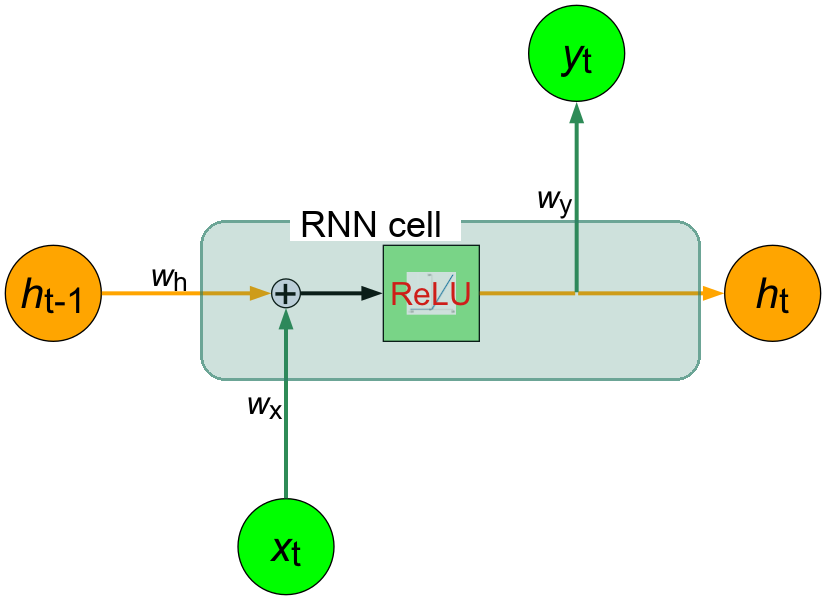
Figure 6: RNN神經元的內部結構
這個神經元在時間點t時會接收兩個輸入、並產生兩個輸出:
- 輸入:
- \(\boldsymbol{x_t}\): 來自外部的輸入,也就是時間點 \(t\) 時的股價 實際漲跌
- \(\boldsymbol{h_{t-1}}\): 來自上一個時間點的「隱藏狀態」,代表時間點t之前的股價漲跌資訊
- 輸出:
- \(\boldsymbol{h_t}=f(\boldsymbol{W_xx_t}+\boldsymbol{W_hh_{t−1}}+b_1)\): 到時間點 \(t\) 為止的「隱藏狀態」
- \(\boldsymbol{y_t}=\boldsymbol{W_yh_t}\): 時間點t的股價漲跌的預測結果)
其中:
- \(\boldsymbol{W_h, W_x, W_y}\) :權重(實際上是矩陣,這裡用簡化的一維符號),分別調整輸入與前一時刻狀態的影響力
- \(b_1, b_2\) :偏差項,但在後續的示範中我們會省略它們以簡化計算
- \(f\) :激活函數(activation function),RNN常用的激活函數為 tanh ,目的在於引入非線性特性,使模型能學習更複雜的模式。
這些權重是怎麼來的呢?還記得在CNN中我們提到的「訓練」嗎?RNN也是透過類似的方式來學習這些權重。它會在訓練過程中不斷調整這些權重,以便更好地預測序列資料中的模式。這個過程通常使用一種叫做反向傳播(backpropagation)的技術,這樣RNN就能夠學習如何根據過去的輸入和隱藏狀態來預測未來的輸出。
至於RNN中的啟動函數,較常見的是使用tanh,也有人用Sigmoid,較少用ReLU,原因是tanh 輸出區間在 [-1, 1],便於梯度傳遞(不會無限放大),而ReLU 可能導致梯度爆炸或消失得更嚴重。但是為了簡化以下的計算過程,讓大家能專注在RNN的運作原理,在接下來的示範中,我們會省略偏差項 \(b_1\),也將啟動函數 \(f\) 改為更簡單的ReLU,以便於理解。
接下來,我們就陸續將昨日與今日的股價漲跌狀況輸入這個模型中,並詳細解說RNN的運算過程。
3. 以RNN預測股價漲跌情況
我們以圖6的RNN為基礎,來設計一個簡單的RNN模型,用以預測股價的漲跌情況。這裡我們用一個很簡單(實際上會賠死)的RNN模型來預測明天股價的漲跌情況,這個模型的重點在於示範RNN模型如何輸入一段連續資料,最後生成預測結果,至於預測結果我們先不要去嫌棄它Q_Q。
以下三種不同的數值分別代表每日的股價變化情況:
- 上漲: yₜ ≥ 0.75
- 平盤: 0.25 < Xₜ < 0.75
- 下跌: Xₜ ≤ 0.25
然後,我們假設已知前兩天的股價變化情況,並希望RNN能夠根據這些資訊來預測明天的股價變化情況(此處的三個時間點請對照圖5):
- 昨天:平盤 (0.5)
- 今天:上漲 (1)
3.1. 輸入昨天的股價漲跌情況(目前的時間點t=1代表的是昨天)
首先,我們假定這個RNN是已經訓練好的模型,所以已經擁有以下的權重值:
- \(w_x = 1.8\)
- \(w_h = -0.5\)
- \(w_y = 1.1\)
此外,因為這是模型的初始階段,我們還沒有任何歷史資訊可以使用,於是我們將「隱藏狀態」\(h_{t-1}\)的值設為0。
接下來就可以開始將資料輸入到RNN模型中,而昨天的股價漲跌情況是「平盤(0.5)」,因此我們將\(x_{t} = 0.5\)輸入到RNN模型中。
現在,圖6中的RNN神經元大概如下所示:
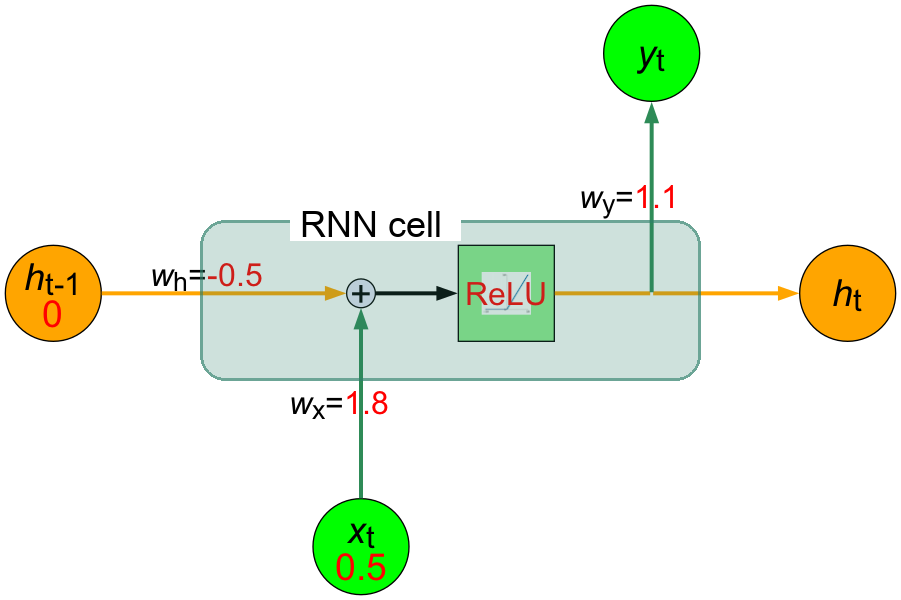
Figure 7: 輸入昨天的股價漲跌情況後的RNN神經元的內部結構
接下來就開始計算RNN的輸出結果:
- 計算加權和\(z\)。因為沒有前天的股價資訊可用,所以我們將隱藏狀態\(h_{t-1}\)設為0): \[ \text{z} = (w_x \cdot x_t) + (w_h \cdot h_{t-1}) = (1.8 \cdot 0.5) + (-0.5 \cdot 0) = 0.9 + 0 = 0.9 \]
- 計算隱藏狀態。由於此處使用ReLU激活函數,而ReLU的定義為 \( \text{ReLU}(z) = \max(0, z) \),也就是當輸入大於0時,輸出等於輸入,否則輸出為0。因此: \[ h_t = \text{ReLU}(\text{z}) = \text{ReLU}(0.9) = 0.9 \]
- 計算輸出: \[ y_t = w_y \cdot h_t = 1.1 \cdot 0.9 = 0.99 \]
- 總結:
- 隱藏狀態 \(h_t = 0.9\)
- 預測輸出 \(y_t = 0.99\)
現在,我們已經完成了將昨天的股價漲跌情況輸入RNN模型,並計算出隱藏狀態和預測輸出。對應的神經元內部結構如圖8所示。
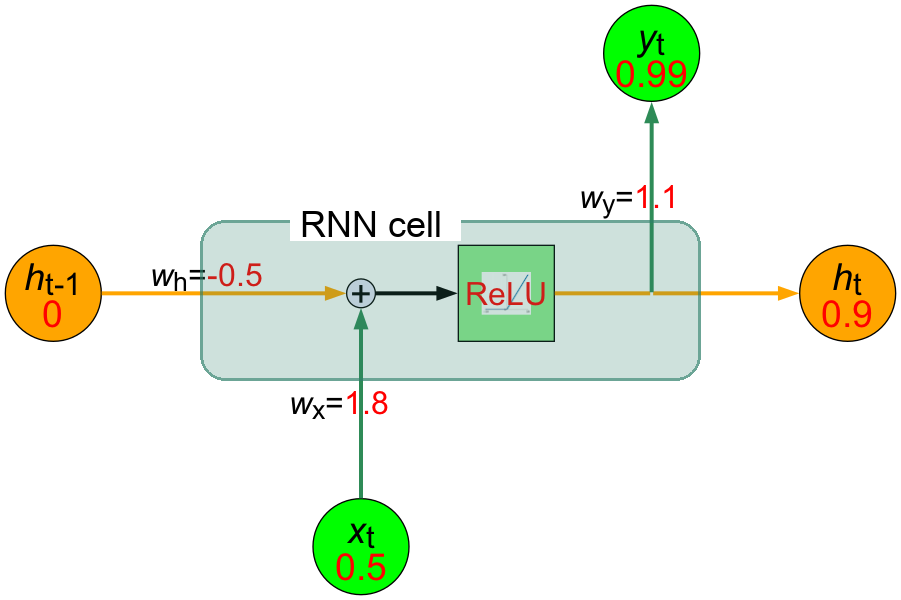
Figure 8: 計算完昨天的股價漲跌情況後的RNN神經元的內部結構
3.2. 輸入今天的股價漲跌情況(目前的時間點t=2代表的是今天)
在完成昨天的股價漲跌情況輸入後,接下來我們將今天的股價漲跌情況輸入RNN模型中。也就:
- 昨天計算出的隱藏狀態\(h_t = 0.9\)將作為今天的「前一時間點隱藏狀態」\(h_{t-1}\)使用。
- 根據前面的假設,今天的股價是「上漲(1)」,因此我們將\(x_{t} = 1\)輸入到RNN模型中。
現在,我們看到的神經元內部結構大概如下所示:
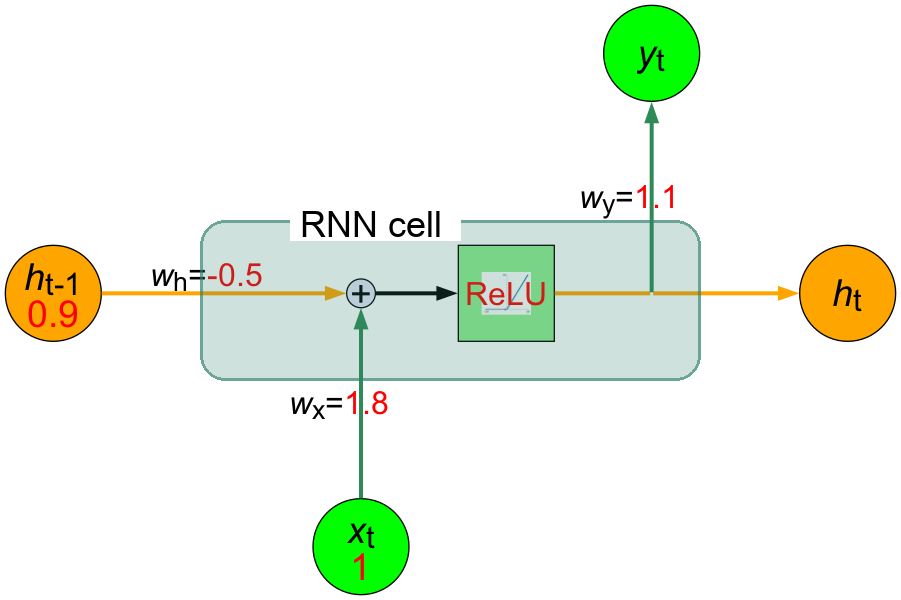
Figure 9: 輸入今天的股價漲跌情況後的RNN神經元的內部結構
接下來就繼續計算時間點t的輸出結果:
- 計算加權和\(z\): \[ \text{z} = (w_x \cdot x_t) + (w_h \cdot h_{t-1}) = (1.8 \cdot 1) + (-0.5 \cdot 0.9) = 1.8 - 0.45 = 1.35 \]
- 計算隱藏狀態: \[ h_t = \text{ReLU}(\text{z}) = \text{ReLU}(1.35) = 1.35 \]
- 計算輸出: \[ y_t = w_y \cdot h_t = 1.1 \cdot 1.35 = 1.485 \]
- 總結:
- 隱藏狀態 \(h_t = 1.35\)
- 預測輸出 \(y_t = 1.485\)
現在,我們已經完成了將今天的股價漲跌情況輸入RNN模型,並計算出隱藏狀態和對明天股價的預測輸出。對應的神經元內部結構如圖10所示。
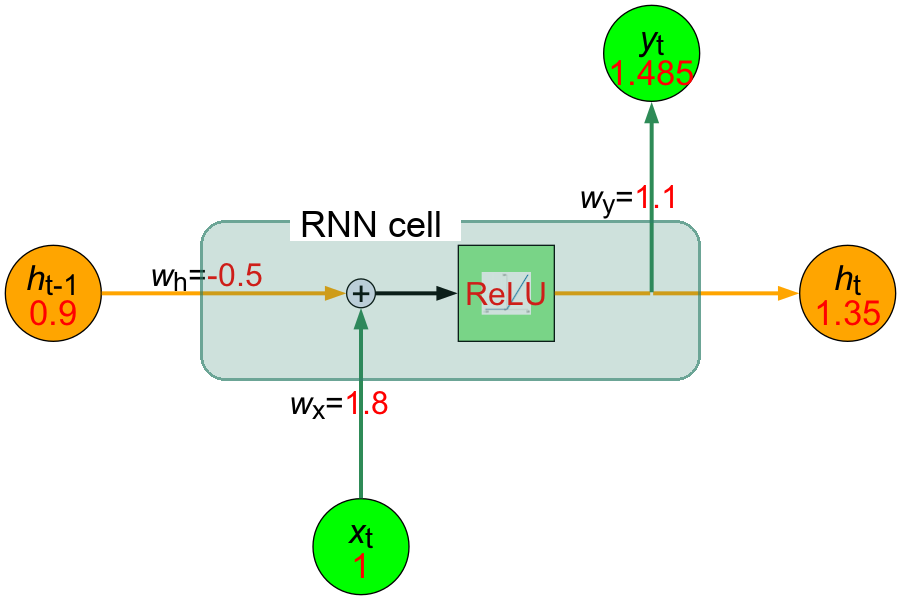
Figure 10: 計算完今天的股價漲跌情況後的RNN神經元的內部結構
RNN模型對於明天股價的預測結果是1.485,再參考我們之前對於股價漲跌情況的定義(yₜ ≥ 0.75 視為上漲、0.25 < yₜ < 0.75 視為平盤、yₜ ≤ 0.25 視為下跌),我們可以解讀為RNN模型預測明天的股價會上漲。
對於啟動函數有概念的讀者,應該會留意到在輸出層其實應該要再加入一個啟動函數(例如 Sigmoid 函數),將輸出值壓縮到0到1之間,這樣才能更合理地對應到「漲」、「跌」、「平盤」這三種情況的機率分布。不過為了簡化計算過程,我們在這個例子中省略了這個步驟。
3.3. 小結
本節我們用「預測股價漲跌」這個例子,說明了 RNN(遞迴神經網路)如何利用前一次的預測結果和新的實際資料,反覆計算並持續更新自己的隱藏狀態,讓模型能夠處理像時間序列這樣有「過去影響未來」特性的資料。就像追劇需要記住前情提要一樣,RNN 也能「記憶」過去的資訊,把昨天和今天的情況,合併用來推估明天的走勢。
此處我們用的是極簡單的模型(實際上預測股價可不能這麼天真 XD),這個例子清楚展現了RNN的「狀態遞傳」與「遞迴計算」的本質,為進一步學習更複雜的序列模型(像是 LSTM 或 GRU)打下基礎。
4. 其他類型的時間序列資料
在上面的例子中,神經元每次輸入的資料\(x_t\)可以是很簡單的一個數值,例如一個股價的漲跌情況(例如上漲0.5、下跌0.3等),而神經元會根據這些輸入資料以及過去的「隱藏狀態」\(h_{t-1}\)來計算出當前的「隱藏狀態」\(h_{t}\)和輸出結果\(y_{t}\)。這樣,RNN就能夠捕捉到股價變化的時間依賴性,從而更好地預測未來的股價走勢。
然而每次的輸入資料\(x_t\)並不一定只能是一個數值,它也可以是一個很大的數組,例如一個300維的向量,用來表示輸入的文字或圖像的特徵。
雖然在上述例子中,我們假設RNN的輸入序列是股價漲跌情況,但實際上這個序列可以是任何有時間順序的資料,例如文字、音頻或其他類型的序列資料。RNN的設計使它能夠捕捉這些資料中的時間依賴性,從而更好地理解和預測未來的趨勢。用個具體一點的例子,假設我們假設剛剛的序列 X 實際上是一個內容如下的英文問句:
X = [ What, time, is, it, ? ]
而且 RNN 已經處理完前兩個元素 What 和 time 了。
則接下來 RNN 會這樣處理剩下的句子:
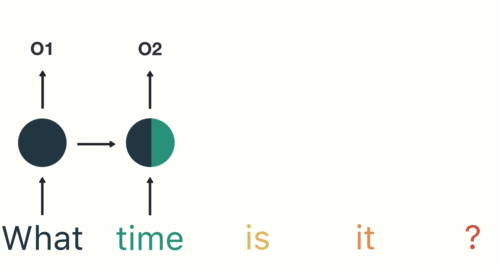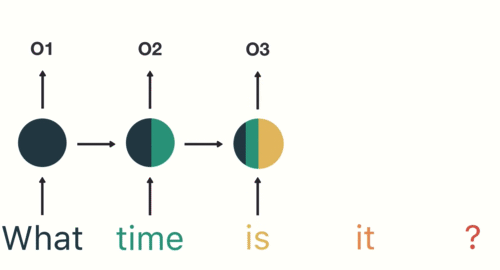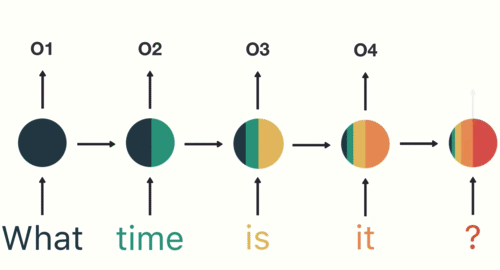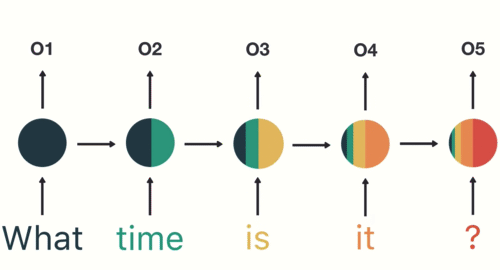
Figure 11: RNN如何處理自然語言
如同我們由左到右逐字閱讀這段文字同時不斷地更新你腦中的記憶狀態,RNN也是以相同的原理在做這件事。RNN的這種設計使它特別適合於像語言翻譯、語音識別或任何需要考慮過去資訊以更好地理解當前情境的任務。例如,在翻譯句子時,理解前面的詞可以幫助更準確地翻譯後面的詞。
但是,RNN也有一些限制,比如它們很難處理很長的序列,因為過長時間的記憶會逐漸消失。這就像如果你試圖回憶幾個月前看的某集連續劇的細節,可能會比較困難。這個問題在後來被一種叫做LSTM的更進階版本的RNN解決。
總之,RNN是一種強大的工具,專門用於處理和預測序列資料中的模式,就像我們用記憶來理解和預測日常生活中的事件一樣。
5. 一個簡單的RNN程式架構範例
在上面的例子中,我們已經介紹了RNN的基本概念和運作方式。這樣的RNN要如何實作出來呢?或者說,我們如何將這些概念轉化為程式碼?在本節中,我們將使用Python實作出一個最簡單的RNN模型,並用它來預測股價漲跌。
5.1. RNN的程式運作示例
RNN的運作概念非常簡單,就是在每個時間點 \(t\),RNN 會讀入一個新的序列資料 \(input_t\),並利用這個資料以及自己的記憶狀態 \(state_t\) 來產生一個輸出 \(output_t\)。
上述過程可以用下面的程式碼來表示:
1: def f(input_t, state_t): # f 函式是神經元的運算,也是利用遞迴的方式來處理序列資料 2: return input_t + state_t 3: 4: state_t = 0 # 初始化細胞的狀態 5: 6: for input_t in input_sequence: 7: output_t = f(input_t, state_t) # f 函式是神經元的運算 8: state_t = output_t # 更新細胞的狀態
在 RNN 每次讀入任何新的序列資料前,細胞 A 中的記憶狀態 \(state_t\) 都會被初始化為 0。
接著在每個時間點 t,RNN 會重複以下步驟:
- 讀入 \(input_{sequence}\) 序列中的一個新元素 \(input_t\)
- 利用 f 函式將當前細胞的狀態 \(state_t\) 以及輸入 \(input_t\) 做些處理產生 \(output_t\)
- 輸出 \(output_t\) 並同時更新自己的狀態 \(state_t\)
那麼,有了如下這個簡易版的RNN,要如何將神經元當下的記憶 \(state_t\) 與輸入 \(input_t\) 結合,才能產生最有意義的輸出 \(output_t\) 呢?
1: state_t = 0 2: # 細胞 A 會重複執行以下處理 3: for input_t in input_sequence: 4: output_t = f(input_t, state_t) 5: state_t = output_t
RNN神經元在時間點t的輸出 \(h_t\) 由以下公式計算: \[ h_t = f(W_x \cdot X_t + W_h \cdot h_{t-1} + b) \]
在 SimpleRNN 的神經元中,這個函數 \(f\) 的實作很簡單,這也導致了其記憶狀態 \(state_t\) 沒辦法很好地「記住」前面處理過的序列元素,因而造成 RNN 在處理後來的元素時,就已經把前面重要的資訊給忘記了,也就是只有短期記憶,沒有長期記憶。長短期記憶(Long Short-Term Memory, 後簡稱 LSTM)就是被設計來解決 RNN 的這個問題。
5.2. RNN的程式模型架構
當然,實際應用RNN模型時我們不可能使用自己手刻的這種陽春版RNN,而是會使用像是 TensorFlow 或 PyTorch 這樣的深度學習框架來建立更複雜的模型。這些框架提供了許多現成的 RNN 模組,可以讓我們更輕鬆地建立和訓練 RNN 模型。
以下是一個使用TensorFlow框架建立 RNN 模型的範例。不同於前面的股價漲跌預測例子中每次只輸入一個數值,在這個範例中,模型每次會輸入一組包含4個特徵的資料,在應用到不同領域時,這些特徵可以代表不同的意義。例如:
- 在股價預測中,這些特徵可以是股價、成交量、其他技術指標等多種資訊的組合,而RNN模型會根據這些特徵來預測未來的股價走勢。
- 在一個工廠的設備監控系統中,這些特徵可以是溫度、壓力、振動等多種感測器數據的組合,此時RNN模型可以用來預測設備是否會發生故障。
我們使用TensorFlow的 Keras API 來建立這個模型,RNN的模型架構非常簡單:建立一個 SimpleRNN 層,然後接上一個全連接層(Dense layer)來產生最終的輸出。
這個模型的架構如圖12所示:
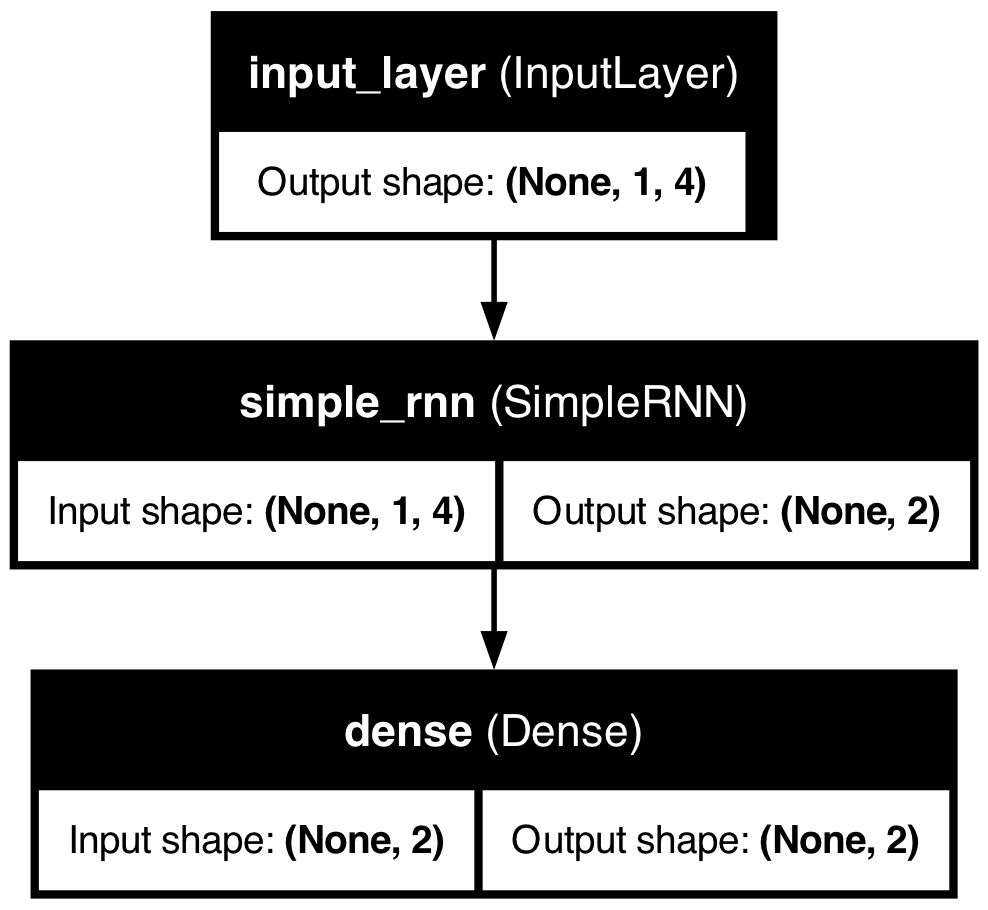
Figure 12: RNN模型架構
上述模型架構的資料流向如下:
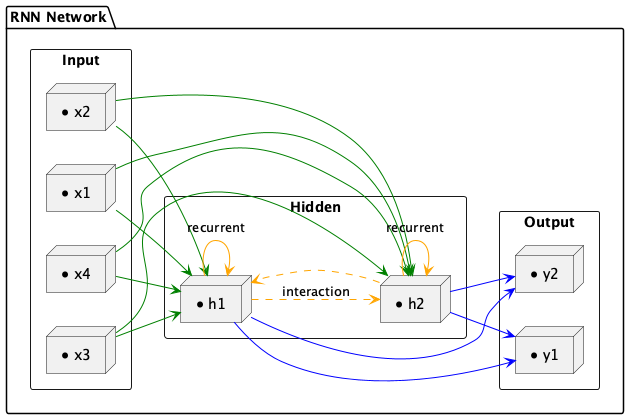
Figure 13: RNN架構
或如下圖
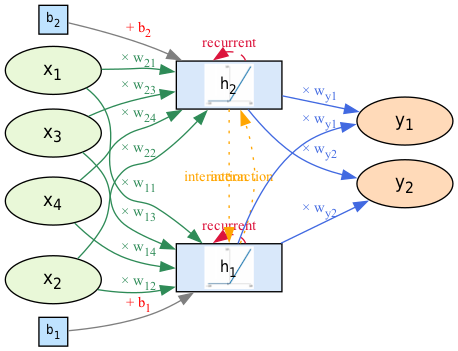
Figure 14: RNN資料流向圖
這個RNN模型的架構可分為四個主要部分,以工廠設備的預測性維護場景為例,模型的各層功能說明如下:
輸入層: 模型輸入層包含四個節點,機器感測器每分鐘會收到下列資料:
- 溫度(Temperature)
- 壓力(Pressure)
- 振動幅度(Vibration)
- 電流(Current)
這些感測器數據能夠即時反映設備運作狀態,是判斷異常與劣化趨勢的第一手依據。
- 隱藏層(RNN層): 隱藏層由兩個RNN單元(\(h_1\)、\(h_2\))組成,能夠捕捉時間序列資料的動態變化。RNN特有的「記憶能力」可根據歷史感測數據(如過去的震動紀錄、轉速變化)與當前輸入,判斷設備狀態變化趨勢,進而識別異常徵兆。
- 輸出層:
輸出層同樣設計為兩個節點:
- \(y_1\) :預測設備未來一段時間內出現故障的風險機率(例如馬達即將故障、異常發熱等)。
- \(y_2\) :預測是否需維修(建議立即維護/可繼續運行)
- 偏置節點: 每個RNN隱藏單元均設有對應的偏置(\(b_1\)、\(b_2\)),用於調整輸出,增強模型彈性與表現力。
這個模型的設計能夠有效地處理時間序列資料,並根據歷史數據預測設備的未來狀態,特別適合用於工廠設備的預測性維護。透過這樣的模型,工廠可以提前識別設備異常,降低突發停機風險,提高生產效率。
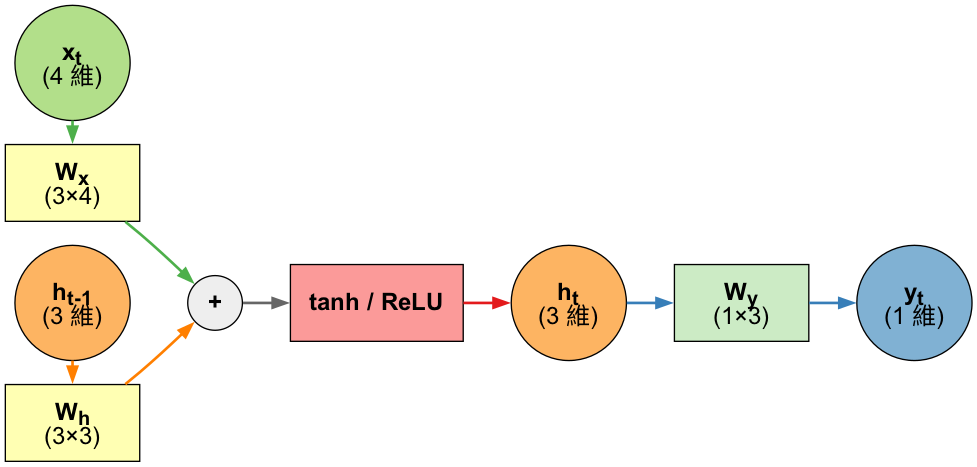

Figure 15: RNN單元內部結構(4-3-1架構)
6. RNN模型的實作範例:從訓練到預測
上述的程式架構只是展示了RNN模型的基本結構,實際應用中我們還需要進行資料準備、模型訓練以及預測等步驟。接下來,我們將實作一個簡單的RNN模型,使用Keras來預測時間序列資料。這個例子將展示如何生成一組帶有雜訊的sin(x) + cos(0.5x)時間序列資料,並使用RNN來預測未來的值。
我們的目的是用一個簡單的 RNN(SimpleRNN)模型,學會預測一段帶雜訊的週期性時間序列的未來值。我們先以人工方式生成一個簡單的、有規律的序列資料( \(sin(x)+cos(0.5x)\) 加入高斯雜訊),然後用 RNN 模型來預測這個序列的未來值。
程式預計的生成結果如圖16,其中的藍色線條是實際的資料,而橘色線條則是模型預測的結果。為了更清楚地展示預測效果,我們將只放大最後300個點。

Figure 16: RNN模型預測結果(局部放大)
6.1. 匯入與資料產生
首先以這段程式碼生成一個帶有雜訊的時間序列資料,這些是訓練模型所需的資料。這裡我們生成的時間序列資料是 \(sin(x) + cos(0.5x)\),並加入高斯雜訊來模擬實際情況中的雜訊干擾,這樣的資料可以幫助模型學習如何從雜訊中提取有用的信號。
1: import numpy as np 2: import matplotlib.pyplot as plt 3: 4: # 1. 生成 sin(x) + cos(x) 並加入雜訊的時間序列資料 5: def generate_sin_cos_data(total_length=3000, noise_std=0.1): 6: x = np.linspace(0, total_length * 0.1, total_length) 7: clean = np.sin(x) + np.cos(x * 0.5) # 不同頻率增加變化性 8: noise = np.random.normal(0, noise_std, size=clean.shape) 9: noisy_data = clean + noise 10: return x, noisy_data.reshape(-1, 1), clean.reshape(-1, 1) 11: 12: # 2. 繪圖展示 sin + cos 波型(含雜訊) 13: x, noisy_data, clean_data = generate_sin_cos_data() 14: 15: plt.figure(figsize=(12, 4)) 16: plt.plot(x, clean_data, label='Clean sin(x) + cos(0.5x)', alpha=0.6) 17: plt.plot(x, noisy_data, label='Noisy signal', alpha=0.8) 18: plt.title("Time Series: sin(x) + cos(0.5x) with Noise") 19: plt.xlabel("x") 20: plt.ylabel("Value") 21: plt.legend() 22: plt.grid(True) 23: plt.tight_layout() 24: plt.savefig("images/rnn_data.png", dpi=300) 25: #plt.show()
生成的時間序列資料如圖17所示,資料總數共 3000 個點,這些資料是我們用來訓練 RNN 模型的基礎。

Figure 17: 時間序列資料生成與展示
6.2. 前處理與序列資料製作
接下來我們對生成的時間序列資料進行標準化處理,把資料轉換為適合 RNN 模型訓練的序列格式。這裡我們使用 MinMaxScaler 來將資料縮放到 [0, 1] 範圍內,然後建立一個長度為 20 的序列資料集。進行標準化的目的在於提高模型的訓練效率和預測準確度,因為 RNN 模型對於輸入資料的尺度非常敏感,在將資料縮放到 [0, 1] 範圍內後,可以幫助模型更快地收斂。
1: import tensorflow as tf 2: from tensorflow import keras 3: from sklearn.preprocessing import MinMaxScaler 4: 5: # 標準化 6: scaler = MinMaxScaler() 7: scaled = scaler.fit_transform(noisy_data) 8: 9: # 建立序列 10: def create_sequences(data, seq_len=20): 11: X, y = [], [] 12: for i in range(len(data) - seq_len): 13: X.append(data[i:i+seq_len]) 14: y.append(data[i+seq_len]) 15: return np.array(X), np.array(y) 16: 17: SEQ_LEN = 20 18: X, y = create_sequences(scaled, SEQ_LEN) 19: 20: # 分訓練與測試集 21: split = int(len(X) * 0.8) 22: X_train, y_train = X[:split], y[:split] 23: X_test, y_test = X[split:], y[split:] 24: 25: print(f"X_train shape: {X_train.shape}, y_train shape: {y_train.shape}") 26: print(f"X_test shape: {X_test.shape}, y_test shape: {y_test.shape}") 27: 28: # 輸出X_train和y_train的前5筆資料 29: print("X_train sample (first 2 sequences):") 30: print(X_train[:2]) 31: print("Y_train sample (first 2 values):") 32: print(y_train[:2])
以下是這個訓練資料(X_train, Y_train)的形狀和前兩筆資料的輸出結果:藉由這些資料,我們想告訴想告訴模型:如果你看到類似的這樣20筆資料,那麼,接下來的第21筆資料應該是什麼樣子。
X_train shape: (2384, 20, 1), y_train shape: (2384, 1) X_test shape: (596, 20, 1), y_test shape: (596, 1) X_train sample (first 2 sequences): [[[0.73592459] [0.75703221] [0.76230877] [0.81056956] [0.81595172] [0.85598213] [0.83727388] [0.88166678] [0.95565607] [0.89441307] [0.89788997] [0.91241336] [0.94591805] [0.98031334] [0.90012658] [0.96128886] [0.90676585] [0.87651928] [0.92046898] [0.90352297]] [[0.75703221] [0.76230877] [0.81056956] [0.81595172] [0.85598213] [0.83727388] [0.88166678] [0.95565607] [0.89441307] [0.89788997] [0.91241336] [0.94591805] [0.98031334] [0.90012658] [0.96128886] [0.90676585] [0.87651928] [0.92046898] [0.90352297] [0.8413003 ]]] Y_train sample (first 2 values): [[0.8413003 ] [0.82853204]]
6.3. 建立RNN模型
許多框架都支援RNN模型,例如 TensorFlow、PyTorch 等。這裡我們使用 TensorFlow的 Keras API 來建立一個簡單的 RNN 模型。
我們使用 Keras 的 `SimpleRNN` 層來建立一個簡單的 RNN 模型,然後對模型進行編譯(compile),這裡的「編譯」和以往我們熟悉的那種「寫完程式後編譯、執行」的概念不同,這裡的編譯是指設定損失函數和優化器等參數,以便模型能夠進行訓練。
1: model = keras.models.Sequential([ 2: keras.layers.Input(shape=(None, 1)), 3: keras.layers.SimpleRNN(1) # 預設 activation='tanh' 4: ]) 5: model.compile(loss='mse', optimizer='adam') 6: model.summary()
Model: “sequential”
| Layer (type) | Output Shape | Param # |
|---|---|---|
| simple_rnn (SimpleRNN) │ (None, 1) | 3 |
Total params: 3 (12.00 B) Trainable params: 3 (12.00 B) Non-trainable params: 0 (0.00 B)
在 Keras 中,=Input(shape=(None, 1))= 的意思是:
| 維度 | 代表什麼 | 解釋 |
|---|---|---|
| None | 時間步長(timesteps) | 不指定具體長度,代表可以處理「任意長度」的序列 |
| 1 | 每個時間點的特徵數 | 這裡是一個數字(例如只有一個值:sin+cos),所以是 1 維特徵 |
在 Keras RNN 中,每筆資料會被視為一個 3 維陣列:
[樣本數, 時間步長 (None), 特徵數]
舉個例子:
X.shape = (1000, 20, 1)
| 維度 | 代表 | 舉例 |
|---|---|---|
| 1000 | 有 1000 筆序列 | 訓練樣本數 |
| 20 | 每筆序列長度是 20 步 | 每筆是一段長度 20 的時間序列 |
| 1 | 每步只有 1 個數字 | 像是 sin 值、溫度、股價 |
我們現在只知道每個時間點有 1 個特徵(像是溫度),但不知道資料序列會多長,因此時間的維度就交給模型在運作時決定,所以寫 None。」
好吧,其實我們是知道的(在這個例子中是 20 步長的序列),但這是這樣寫是為了讓模型能夠處理任意長度的序列資料這樣的設計可以讓模型在訓練時自動學習時間序列的長度和特徵數量。
6.4. 訓練模型
接下來,我們將使用訓練資料來訓練這個 RNN 模型。這裡我們使用 `fit` 方法來進行訓練,並設定訓練的輪數(epochs)為 20 次。每次訓練都會更新模型的權重,以便模型能夠更好地預測未來的值。參數verbose=2表示在訓練過程中輸出詳細的訓練進度,你也可以將其設為 1 或 0 來調整輸出細節。
1: model.fit(X_train, y_train, epochs=20, verbose=2)
Epoch 1/20 75/75 - 0s - 5ms/step - loss: 0.0055 Epoch 2/20 75/75 - 0s - 5ms/step - loss: 0.0055 Epoch 3/20 75/75 - 0s - 4ms/step - loss: 0.0054 Epoch 4/20 75/75 - 0s - 4ms/step - loss: 0.0054 Epoch 5/20 75/75 - 0s - 5ms/step - loss: 0.0054 Epoch 6/20 75/75 - 0s - 4ms/step - loss: 0.0053 Epoch 7/20 75/75 - 0s - 4ms/step - loss: 0.0053 Epoch 8/20 75/75 - 0s - 4ms/step - loss: 0.0053 Epoch 9/20 75/75 - 0s - 4ms/step - loss: 0.0052 Epoch 10/20 75/75 - 0s - 5ms/step - loss: 0.0052 Epoch 11/20 75/75 - 0s - 4ms/step - loss: 0.0051 Epoch 12/20 75/75 - 0s - 5ms/step - loss: 0.0051 Epoch 13/20 75/75 - 0s - 4ms/step - loss: 0.0051 Epoch 14/20 75/75 - 0s - 5ms/step - loss: 0.0050 Epoch 15/20 75/75 - 0s - 4ms/step - loss: 0.0050 Epoch 16/20 75/75 - 0s - 4ms/step - loss: 0.0050 Epoch 17/20 75/75 - 0s - 3ms/step - loss: 0.0049 Epoch 18/20 75/75 - 0s - 807us/step - loss: 0.0049 Epoch 19/20 75/75 - 0s - 671us/step - loss: 0.0049 Epoch 20/20 75/75 - 0s - 749us/step - loss: 0.0048
6.5. 評估預測效果並繪圖
模型訓練完後總要評估一下預測效果,這裡我們使用測試資料來評估模型的預測能力。首先,我們使用 `predict` 方法來獲取模型對測試資料的預測結果,然後將預測結果還原回原始數值範圍。接著,我們將實際值和預測值繪製在同一張圖上,以便直觀地比較模型的預測效果。
1: predicted = model.predict(X_test) 2: # 還原回原始數值 3: predicted_inv = scaler.inverse_transform(predicted) 4: actual_inv = scaler.inverse_transform(y_test) 5: 6: plt.figure(figsize=(12, 4)) 7: plt.plot(actual_inv, label='Clean Target', alpha=0.6) 8: plt.plot(predicted_inv, label='Predicted', alpha=0.8) 9: plt.title("Keras SimpleRNN Prediction") 10: plt.xlabel("Time step") 11: plt.ylabel("Value") 12: plt.legend() 13: plt.grid(True) 14: plt.savefig("images/rnn_prediction.png", dpi=300) 15: #plt.show()

Figure 18: RNN模型預測結果
由上圖大致可以看出,模型對於時間序列的預測效果還不錯,雖然有些波動,但整體趨勢是正確的。
但是,所謂「不錯」到底是到什麼程度呢?這裡我們需要使用一些評估指標來量化模型的預測效果。一般在評估這種數值預測模型時,我們會使用均方誤差(MSE)、平均絕對誤差(MAE)、均方根誤差(RMSE)和決定係數(\(R^2\))等指標來衡量模型的預測效果。幾種RNN模型的評估指標如下:
- MSE(均方誤差,Mean Squared Error), 是預測值與實際值之間的平均平方差,越小越好, 單位是平方的數值。計算公式如下: \[ MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 \] 其中,$y_i$是實際值,$\hat{y}_i$是預測值,$n$是樣本數。
- MAE(平均絕對誤差,Mean Absolute Error), 是預測值與實際值之間的平均絕對差,越小越好, 單位與資料本身一致, 優點是不容易被極端值影響。計算公式如下: \[ MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i| \] 其中,$y_i$是實際值,$\hat{y}_i$是預測值,$n$是樣本數。
- RMSE(均方根誤差,Root Mean Squared Error), 是預測值與實際值之間的均方根誤差,越小越好, 單位是平方根的數值,常用在實際工程應用。 計算公式如下: \[ RMSE = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2} \] 其中,$y_i$是實際值,$\hat{y}_i$是預測值,$n$是樣本數。
- \(R^2\)(決定係數,Coefficient of Determination),是用來評估模型預測能力的指標,值介於0~1之間,越接近1表示模型越好。$R^2$的計算公式如下: \[ R^2 = 1 - \frac{\sum_{i=1}^{n} (y_i - \hat{y}_i)^2}{\sum_{i=1}^{n} (y_i - \bar{y})^2} \]
1: import numpy as np 2: from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score 3: 4: # 計算各種評估指標 5: mse = mean_squared_error(actual_inv, predicted_inv) 6: mae = mean_absolute_error(actual_inv, predicted_inv) 7: rmse = np.sqrt(mse) 8: r2 = r2_score(actual_inv, predicted_inv) 9: 10: # 直接輸出結果 11: print("=== 評估指標 ===") 12: print(f"MSE : {mse:.6f}") 13: print(f"MAE : {mae:.6f}") 14: print(f"RMSE : {rmse:.6f}") 15: print(f"R^2 : {r2:.6f}")
=== 評估指標 === MSE : 0.073513 MAE : 0.218703 RMSE : 0.271133 R^2 : 0.926007
這些評估結果足夠好了嗎?能不能再提升?當然可以!在實際應用中,我們通常會嘗試不同的模型架構和參數來進一步提升預測效果。例如:
6.5.1. 增加隱藏層神經元數量
1: keras.layers.SimpleRNN(8) # 把神經元從 1 個增加到 8 個
6.5.2. 增加隱藏層數量
例如:SimpleRNN層、Dense層、Dropout層
SimpleRNN層
這個層是 RNN 的核心部分,負責處理序列資料。你可以增加這個層的神經元數量來提高模型的容量,讓模型能夠學習更複雜的模式。
1: model = keras.models.Sequential([ 2: keras.layers.Input(shape=(None, 1)), 3: keras.layers.SimpleRNN(4, return_sequences=True), # 第一層要回傳序列 4: keras.layers.SimpleRNN(4), # 第二層直接接收整段序列資訊 5: keras.layers.Dense(1) 6: ])
return_sequences=True :告訴第一層 RNN 回傳「每個時間步的輸出」,否則下一層 RNN 沒辦法處理。
Dense層
這個層可以增加模型的容量,讓模型能夠學習更複雜的模式。Dense層會將上一層的輸出進行線性變換,並加上偏置項,然後通過激活函數(默認是ReLU)來產生輸出。
1: model = keras.models.Sequential([ 2: keras.layers.Input(shape=(None, 1)), 3: keras.layers.SimpleRNN(4), # 增加容量 4: keras.layers.Dense(1) # 加輸出層 5: ])
Dropout層
這個層可以幫助減少過擬合,特別是在訓練資料較少的情況下。Dropout層會隨機丟棄一部分神經元的輸出,以防止模型過度依賴某些特定的神經元。
1: model = keras.models.Sequential([ 2: keras.layers.Input(shape=(None, 1)), 3: keras.layers.SimpleRNN(4, return_sequences=True), 4: keras.layers.SimpleRNN(4), 5: keras.layers.Dropout(0.2), 6: keras.layers.Dense(1) 7: ])
6.5.3. 增加訓練次數
也就是增加 epochs 的數量,讓模型有更多機會學習資料中的模式。
6.6. 標準的評估結果呈現方式
在輸出模型預測結果時,通常會將實際值和預測值繪製在同一張圖上,以便直觀地比較模型的預測效果。這樣的圖表可以幫助我們更好地理解模型的預測能力和局限性。

Figure 19: RNN模型詳細預測結果
同學們可以把重點放在圖19的第4張子圖上,這是模型的學習曲線(Learning Curve),它顯示了訓練過程中損失函數(Loss)的變化情況。從圖中可以看出,隨著訓練次數(Epoch)的增加,模型的損失逐漸減少,這表明模型在學習資料中的模式。
6.7. 好像有哪裡不對勁?
這麼一個簡單的模型就能達到這麼好的預測效果?真的嗎?
其實我們在過程中是有點作弊的:
- 首先,我們的資料是從一個已知的數學函數(sin+cos)生成的,所以模型能夠很容易地學習到這個模式。
- 其次,也是最重要的一點,我們每個預估點都是從20筆「正確」的資料中預估出來的,就算其中有某些資料預測錯誤,仍不影響接下來的預測(因為下一個預估值仍是依據正確的20筆資料),但這不是我們實際需要的預測,通常提及預測,我們需要的是「未來一週的PM 2.5變化」或是「未來一個月的股價走勢」。也就是說,我們需要的預測是基於「未來的資料」來預測「未來的值」,而不是基於「過去的資料」來預測「過去的值」。
你要不要改一下上面的程式碼,讓模型預測「未來的值」呢?這樣就能更真實地模擬實際應用中的情況了。
6.8. RNN的運作流程
如果我們將圖5左側的RNN神經元放大來看(如圖20),會發現它其實包含了三組權重:
- 來自外部輸入\(x_{t}\) 的權重 \(w_{x}\)
- 來自「上一個時間點的自己」(時間點 \(t-1\) )所傳來的「隱藏狀態」\(h_{t-1}\) 的權重 \(w_{h}\)
- 輸出結果 \(h_{t}\) 的權重 \(w_{y}\)
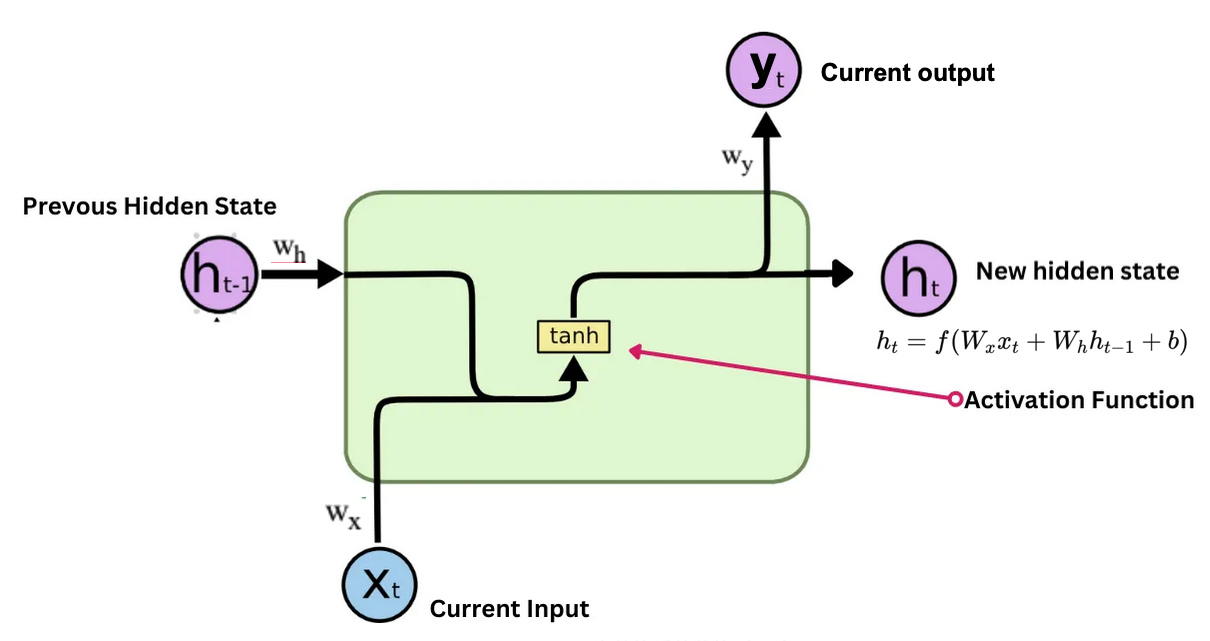
Figure 20: RNN神經元
圖20代表的是一個時間點\(t\)的RNN神經元狀態,在這個時間點下,他是如何讀入資料?又是如何處理資料並產生輸出的呢?我們可以透過以下步驟來理解:
- 首先,這個神經元在時間點\(t\)會收到兩項資訊:
- 來自外部的輸入\(x_{t}\)
- 來自「上一個時間點(\(t-1\))的自己」所傳來的「隱藏狀態」\(h_{t-1}\)
- 接下來我們來看一下這個神經元的第一項輸出\(h_t\),上面的兩項輸入會經過各自的權重( \(w_{x}\) 和 \(w_{h}\) )進行加權處理,然後將加權後的結果相加,形成一個新的總和,我們暫且把這個和叫做\(z_{t}\),其計算方式如下(為了簡化計算過程,此處省略了偏差項bias): \[ z_{t} = w_{x} \cdot x_{t} + w_{h} \cdot h_{t-1} \] 可以看出,這個總和\(z_{t}\)同時包含了來自當前輸入\(x_{t}\)的資訊以及來自過去時間點的歷史資訊\(h_{t-1}\)。然後,這個總和\(z_{t}\)會經過一個非線性激活函數(例如ReLU、tanh等)進行處理,產生這個時間點的輸出\(h_{t}\),其計算方式如下: \[ h_{t} = \text{activation}(z_{t}) \] 也就是說,其實完整的計算過程可以寫成: \[ h_{t} = \text{activation}(w_{x} \cdot x_{t} + w_{h} \cdot h_{t-1}) \] 這個\(h_t\)就是要傳遞給下一個時間點的「隱藏狀態」。
- 接下來我們來看這個神經元的第二項輸出\(y_t\),它是將剛剛計算出來的\(h_{t}\)經過另一組權重$w_{y}$進行加權處理後產生的,而最終在輸出前通常也會經過一個激活函數(例如softmax、sigmoid等)來產生最終的輸出結果,其計算方式如下(同樣省略了偏差項bias): \[ y_{t} = w_{y} \cdot h_{t} \] 這個\(y_t\)就是這個時間點的最終輸出結果,可以用來進行後續的任務(例如分類、回歸等)。 其實,不是每個時間點都會有這個輸出\(y_t\),有些RNN模型只在序列的最後一個時間點才會產生輸出,而有些則會在每個時間點都產生輸出,這取決於具體的應用場景和模型設計。 例如,在做機器翻譯的任務中,RNN通常會在每個時間點都產生一個輸出,對應到翻譯後的每個單詞;而在做股價預測的任務中,RNN可能只在最後一個時間點產生一個輸出,對應到未來某一天的股價預測。
- 這樣所提到的計算過程會一直重複下去,每個時間點的神經元都會按照上述步驟來處理輸入資料並產生輸出結果,直到整個序列資料被完全處理完畢為止。
7. 作業:RNN 大挑戰
7.1. 作業一:氣溫預測器 — 你比氣象局準嗎?
在教材中我們用 \(sin(x)+cos(0.5x)\) 來訓練 RNN,但那畢竟是假資料。現在請你用 RNN 來預測「真正的」時間序列 — 一整年的每日氣溫變化!
以下範例程式會生成一年份的模擬氣溫資料(有季節變化 + 隨機天氣擾動),並用 SimpleRNN 來預測氣溫:
1: import numpy as np 2: import matplotlib.pyplot as plt 3: from sklearn.preprocessing import MinMaxScaler 4: import tensorflow as tf 5: from tensorflow import keras 6: 7: np.random.seed(42) 8: tf.random.set_seed(42) 9: 10: # 生成一年份模擬氣溫(365天) 11: days = np.arange(365) 12: # 基礎溫度:夏天熱、冬天冷(用 cos 模擬季節) 13: base_temp = 25 - 10 * np.cos(2 * np.pi * days / 365) 14: # 加入每日隨機擾動 15: noise = np.random.normal(0, 2, size=365) 16: temperature = base_temp + noise 17: 18: # 標準化 19: scaler = MinMaxScaler() 20: temp_scaled = scaler.fit_transform(temperature.reshape(-1, 1)) 21: 22: # 建立序列(用過去 14 天預測明天) 23: SEQ_LEN = 14 24: X, y = [], [] 25: for i in range(len(temp_scaled) - SEQ_LEN): 26: X.append(temp_scaled[i:i+SEQ_LEN]) 27: y.append(temp_scaled[i+SEQ_LEN]) 28: X, y = np.array(X), np.array(y) 29: 30: # 分訓練/測試集(前 80% 訓練,後 20% 測試) 31: split = int(len(X) * 0.8) 32: X_train, y_train = X[:split], y[:split] 33: X_test, y_test = X[split:], y[split:] 34: 35: # 建立 SimpleRNN 模型 36: model = keras.models.Sequential([ 37: keras.layers.Input(shape=(SEQ_LEN, 1)), 38: keras.layers.SimpleRNN(1), 39: ]) 40: model.compile(loss='mse', optimizer='adam', metrics=['mae']) 41: model.fit(X_train, y_train, epochs=20, verbose=0) 42: 43: # 預測並還原 44: pred = model.predict(X_test, verbose=0) 45: pred_inv = scaler.inverse_transform(pred) 46: actual_inv = scaler.inverse_transform(y_test) 47: 48: # 畫圖 49: plt.figure(figsize=(10, 4)) 50: plt.plot(actual_inv, label='Actual', alpha=0.7) 51: plt.plot(pred_inv, label='Predicted', alpha=0.9) 52: plt.title('Temperature Prediction (SimpleRNN, 1 neuron)') 53: plt.xlabel('Day') 54: plt.ylabel('Temperature (°C)') 55: plt.legend() 56: plt.grid(True) 57: plt.tight_layout() 58: plt.savefig('images/hw_rnn_temp.png', dpi=150) 59: 60: from sklearn.metrics import mean_absolute_error 61: mae = mean_absolute_error(actual_inv, pred_inv) 62: print(f"MAE: {mae:.2f} °C")
7.1.1. 你的任務
上面的模型只用了 1 個神經元 ,預測效果當然不太好。請修改模型架構,讓 MAE(平均絕對誤差)降到 3.0°C 以下 。
提示:
- 可以增加 SimpleRNN 的神經元數量
- 可以堆疊多層 SimpleRNN(記得第一層要加
return_sequences=True) - 可以加 Dense 層
- 可以調整 epochs 數量
7.1.2. 預期輸出
MAE: 2.xx °C (只要低於 3.0 就算過關)
7.2. 作業二:手算 RNN — 當人體 GPU
在教材中,我們用 \(w_x=1.8\), \(w_h=-0.5\), \(w_y=1.1\) 這組權重,從「昨天平盤(0.5)」和「今天上漲(1)」預測出明天的股價。
現在換一組全新的設定:
- 權重:\(w_x = 2.0\), \(w_h = 0.3\), \(w_y = 0.8\)
- 激活函數:ReLU
- 初始隱藏狀態:\(h_{t-1} = 0\)
- 三天的股價變化序列:\(x_1 = 0.2\)(下跌), \(x_2 = 0.6\)(平盤), \(x_3 = 0.9\)(上漲)
7.2.1. 你的任務
請用紙筆(或計算機)手算以下內容,寫出每一步的計算過程:
- 依序輸入 \(x_1, x_2, x_3\),計算每個時間點的隱藏狀態 \(h_t\) 和輸出 \(y_t\)
- 根據最終的 \(y_3\) 值,判斷模型預測「後天」的股價是上漲、平盤還是下跌
- 上漲:\(y_t \geq 0.75\)
- 平盤:\(0.25 < y_t < 0.75\)
- 下跌:\(y_t \leq 0.25\)
7.2.2. 預期輸出
=== 時間點 1 (x₁ = 0.2) === z₁ = w_x × x₁ + w_h × h₀ = ??? h₁ = ReLU(z₁) = ??? y₁ = w_y × h₁ = ??? === 時間點 2 (x₂ = 0.6) === z₂ = w_x × x₂ + w_h × h₁ = ??? h₂ = ReLU(z₂) = ??? y₂ = w_y × h₂ = ??? === 時間點 3 (x₃ = 0.9) === z₃ = w_x × x₃ + w_h × h₂ = ??? h₃ = ReLU(z₃) = ??? y₃ = w_y × h₃ = ??? 預測結果:??? (上漲/平盤/下跌)
7.3. 作業三:序列長度大對決 — 記憶力比拚
RNN 號稱有「記憶力」,但記憶力到底有多強?讓我們來實驗看看:用不同的序列長度(也就是「看幾天前的資料來預測」)訓練模型,看看哪個長度的效果最好。
以下範例用 SEQ_LEN=5 來訓練:
1: import numpy as np 2: import matplotlib.pyplot as plt 3: from sklearn.preprocessing import MinMaxScaler 4: from sklearn.metrics import mean_absolute_error 5: import tensorflow as tf 6: from tensorflow import keras 7: 8: np.random.seed(42) 9: tf.random.set_seed(42) 10: 11: # 生成資料 12: x_vals = np.linspace(0, 300, 3000) 13: data = (np.sin(x_vals) + np.cos(x_vals * 0.5)).reshape(-1, 1) 14: noise = np.random.normal(0, 0.1, size=data.shape) 15: data_noisy = data + noise 16: 17: scaler = MinMaxScaler() 18: scaled = scaler.fit_transform(data_noisy) 19: 20: def train_and_evaluate(seq_len): 21: """用指定的序列長度訓練 RNN 並回傳 MAE""" 22: X, y = [], [] 23: for i in range(len(scaled) - seq_len): 24: X.append(scaled[i:i+seq_len]) 25: y.append(scaled[i+seq_len]) 26: X, y = np.array(X), np.array(y) 27: 28: split = int(len(X) * 0.8) 29: X_train, y_train = X[:split], y[:split] 30: X_test, y_test = X[split:], y[split:] 31: 32: model = keras.models.Sequential([ 33: keras.layers.Input(shape=(seq_len, 1)), 34: keras.layers.SimpleRNN(4), 35: keras.layers.Dense(1) 36: ]) 37: model.compile(loss='mse', optimizer='adam') 38: model.fit(X_train, y_train, epochs=20, verbose=0) 39: 40: pred = scaler.inverse_transform(model.predict(X_test, verbose=0)) 41: actual = scaler.inverse_transform(y_test) 42: return mean_absolute_error(actual, pred) 43: 44: # 只測試 SEQ_LEN = 5 45: mae = train_and_evaluate(5) 46: print(f"SEQ_LEN=5, MAE={mae:.4f}")
7.3.1. 你的任務
請修改上面的程式,測試以下四種序列長度:=SEQ_LEN = 5, 10, 20, 50= ,並比較它們的 MAE。
提示:用迴圈跑四次 train_and_evaluate() 就好了。
7.3.2. 預期輸出
SEQ_LEN= 5, MAE=0.xxxx SEQ_LEN=10, MAE=0.xxxx SEQ_LEN=20, MAE=0.xxxx SEQ_LEN=50, MAE=0.xxxx 最佳序列長度:xx
(通常 SEQ_LEN=20 左右效果最好,太短記不住、太長反而學不好)