Advanced Materials of Python
Table of Contents

1. FUNCTION
在 Python 中,function 屬於一級物件(first-class object),意思是可以被指派給變數、存在資料結構中、做為參數傳給其他 function,甚至可以當作其他 function 的傳回值。
1.1. Function 有什麼用?
1.1.1. 2B. 三角形面積求解[基本變數輸入輸出]
在作業 2B 中,我們的任務是根據三角形的三邊長來計算面積
1: a, b, c = 3, 4, 5 2: s = (a + b + c) / 2 3: area = (s * (s - a) * (s - b) * (s - c)) ** 0.5 4: print(area)
1.1.2. 如果有個 function 叫 triangleArea(),傳給它三個整數、它就會傳回面積,那上面的程式就可以簡化為:
1: a, b, c = 3, 4, 5 2: print(triangleArea(a, b, c))
若真能如此,一切就太完美了。但,雖然 python 提供了很多有用的 function,但是總不可能預測到所有人的需求,此時就需要我們自己來設計這個 function 了…..
1.2. 函式(function)基本操作
1.2.1. 函式(function)的重要性
- function 為一段程式的集合,可視為一個獨立的區段。
- function 可重覆使用,因此為結構化程式語言的重要元素。
可將龐大複雜的程式分解為小問題,由多人分別以 function 解決,縮短開發時間。
- function 可區分為以下三類:
- Python 內建 function,如: print()、len()、int()、str()…。
- 第三方公司所開發的模組 module(多個 function 組合)。
- 自定義 function。
- Python 內建 function,如: print()、len()、int()、str()…。
1.2.2. 自定義函式
宣告語法
1: def 函式名稱 ( [參數1, 參數2, ...] ): 2: 程式區塊 3: [ return 值 ]
- 說明 :
- 參數可省略,亦即呼叫 function 不需傳入任何資料(引數)。
- 若無回傳值,則無需 return。
- 若多個回傳值可用逗號隔開。
- 參數可省略,亦即呼叫 function 不需傳入任何資料(引數)。
1.2.3. 自定義函式的呼叫
- 呼叫函式語法:
1: [ 變數 ] = 函式名稱( [引數1, 引數2, ... ] )
範例:
1: def circle(r): 2: return r*r*3.14 3: 4: r = 10 5: print('半徑%d的圓面積:%.2f' %(r, circle(r)))
半徑 10 的圓面積:314.00
1.2.4. 多參數函式
- 呼叫函式時引數(argument)個數
- 自定義函式的參數(parameter)個數
- 設定參數初始值。
若呼叫時無引數傳入,
則使用其初始值。
前文中提及的 triangleArea()需要傳入三個參數(三角形的三邊),這就是典型的多參數 function。
1: def triangleArea(a, b, c): 2: s = (a + b + c) / 2 3: area = (s * (s - a) * (s - b) * (s - c)) ** 0.5 4: return area 5: 6: print(triangleArea(3, 4, 5))
6.0
1.2.5. 多回傳值函式
呼叫函式多個回傳值語法
1: [ 變數1, 變數2, ... ] = 函式名稱( [引數1, 引數2, ... ] )
範例: 輸入全班分數,傳回全班總分、全班平均
1: def scoreProcessor(score): 2: sos = 0 3: for x in score: 4: sos += x 5: # sos = sum(score) 6: return sos, sos/len(score) 7: 8: scores = (21, 33, 83, 100, 75, 60) 9: sum, avg = scoreProcessor(scores) 10: print('sum=',sum,',average=',avg)
sum= 372 ,average= 62.0
1.3. 引數(argument)的傳遞
- 每一個函式都是獨立的,所以函式只知道自己程式區域內的變數,不認識函式外的變數。
- 變數因其所宣告位置,可區分為全域變數(Global variable)、區域變數(Local variable)。
- 全域變數:宣告在任何函式外,所有函式皆可存取。
- 區域變數:宣告在函式內,僅函式內可存取。
- 全域變數:宣告在任何函式外,所有函式皆可存取。
全域變數與區域變數範例
1: # 這是全域變數,所有函式都可以讀取與使用 2: x = 5 3: y = 10 4: 5: def use_global(): 6: # 使用全域變數 x 和 y 來計算 7: print("use_global:", x + y) 8: 9: def use_local(): 10: # 這裡定義了區域變數 x 和 y,僅在這個函式中有效 11: x = 20 12: y = 30 13: print("use_local:", x + y) 14: 15: use_global() # 使用全域的 x=5, y=10,輸出 15 16: use_local() # 使用區域的 x=20, y=30,輸出 50 17: 18: # 再次使用全域變數確認未受影響 19: print("Global variables remain:", x, y) # 輸出 5 10
use_global: 15 use_local: 50 Global variables remain: 5 10
1.3.1. 說明重點:
- use_global():函式內沒有定義 x 或 y,因此會使用函式外的全域變數。
- use_local():函式內重新定義了 x 和 y,這些是區域變數,只在這個函式中有效,函式外的全域變數不會受到影響。
- 最後再次印出全域變數,確認它們仍然是原本的值。
1.3.2. 傳值與傳址
這裡要講的概念是:我傳給 function 的參數到底會不會被 function 偷偷改掉?
舉個例子:如果我在 function circle 裡把主程式傳過來的半徑改掉,那麼,原來主程式的半徑會不會跟著被改掉呢?
1: def circle(r): 2: r = 100 #我在這裡把半徑改掉 3: return r*r*3.14 4: 5: r = 10 6: print('原來的r:', r) 7: print('算面積:', circle(r)) 8: print('後來的r:', r)
原來的 r: 10 算面積: 31400.0 後來的 r: 10
有些參數可以在 function 中被修改,有些則不行,這就是傳值/傳址的差異。
- 引數(argument)的傳遞分為兩種方式,由 Python 自動判別:
- 傳值呼叫(Call-by-Value): 參數不會被 function 修正
- 傳址呼叫(Call-by-Reference): 參數可以被 function 修改
- 傳值呼叫(Call-by-Value): 參數不會被 function 修正
| 引數傳遞 | 傳遞內容 | 參數改變 | 資料型別 |
|---|---|---|---|
| 傳值呼叫 call-by-value | 引數值 | 否 | bool, int, float, str, tuple, chr |
| 傳址呼叫 call-by-reference | 引數記憶體位址 | 是 | List, dict, set |
也就是說,如果你傳進去的參數是 list,那很有可能就會被修改:
範例:
1: # str傳值、List傳址 2: def ccc(name, score): 3: name = 'Amy' 4: score.append(99) 5: print('--函式內輸出---') 6: print('name:', name,'\tscore:',score) 7: 8: name = 'Josh' 9: score = [77, 88] 10: 11: print('--原來的list--') 12: print(score) 13: print('--呼叫function ccc--') 14: ccc(name, score) 15: print('--現在的list--') 16: print(score)
--原來的 list-- [77, 88] --呼叫 function ccc-- --函式內輸出--- name: Amy score: [77, 88, 99] --現在的 list-- [77, 88, 99]
1.4. 模組(module)
1.4.1. 匯入模組語法:
Python 中的函式庫稱為模組(module)。
1: import 模組1 [, 模組2, ... ] 2: from 模組 import 函式
1.4.2. 範例
1: import random as ran 2: 3: print(ran.randint(1, 100)) 4: print(ran.randint(1, 100)) 5: print(ran.randint(1, 100))
50 78 16
1.4.3. 自訂模組
- 定義: myModule.py
1: # name: myModule.py 2: 3: def pp(n): 4: return n+1 5: 6: def mm(n): 7: return n-1
- 使用
1: import myModule as my 2: 3: print(my.pp(5)) 4: print(my.mm(5)) 5: print(my.__name__) 6: print(dir(my))
6 4 myModule ['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'mm', 'pp']
1.5. 全域變數(Global variable)
前面提到 function 內的變數是區域變數,無法影響外部。但如果你真的需要在 function 裡修改全域變數,可以使用 global 關鍵字。
1: 2: def f1(x): 3: y = x - 3 # 這裡的 y 是區域變數,和外面的 y 無關 4: if y < 0: 5: return 2*x+1 6: return x - 1 7: 8: def f2(x): 9: global y # 宣告要使用全域的 y 10: y = x - 3 # 這裡會修改到全域的 y 11: if y < 0: 12: return 2*x+1 13: return x - 1 14: 15: y = -1 16: print(f1(1), y) # f1 不會改到全域的 y,所以 y 仍然是 -1 17: print(f2(1), y) # f2 用了 global,所以全域的 y 被改成 1-3 = -2
3 -1 3 -2
注意:雖然 global 可以用,但過度使用全域變數會讓程式難以維護(因為不知道哪個 function 偷偷改了它)。建議盡量用參數傳遞和 return 來交換資料。
2. 遞迴(Recursion)
從前有座山,山上有座廟,廟裡有個老和尚和一個小和尚,一天,老和尚給小和尚講了一個故事,故事的內容是「從前有座山,山上有座廟,廟裡有個老和尚和一個小和尚,一天,老和尚給小和尚講了一個故事,是「從前有座山,山上有座廟,廟裡有個老和尚和一個小和尚,故事的內容……」」。
前節提及我們寫了一支 function 後,可以在其他地方呼叫(call)執行這支程式,像底下這樣:
1: def storyTeller(): 2: print('從前有座山,山上有座廟,廟裡有個老和尚和一個小和尚,一天,老和尚給小和尚講了一個故事') 3: 4: # 主程式 5: storyTeller()
從前有座山,山上有座廟,廟裡有個老和尚和一個小和尚,一天,老和尚給小和尚講了一個故事
但,如果我們 *在 function 裡又呼叫自己呢?像底下這樣:
1: def storyTeller(): 2: print('從前有座山,山上有座廟,廟裡有個老和尚和一個小和尚,一天,老和尚給小和尚講了一個故事') 3: storyTeller() #storyTeller在結束前呼叫自己 4: # 主程式 5: storyTeller()
上述的概念即是 recursion,明明我們沒寫 for 或 while,但確有重複執行的能力;只是它有個小小但致命的缺點: 停不下來…QQ
再看另一個例子:
1: def printN(n): 2: print(n) 3: printN(n-1) 4: 5: #主程式 6: printN(5)
猜一下上述程式會得到什麼結果…
2.1. Recursion 的必要條件
- 自我呼叫
即,在 function 自己呼叫自己 - 停止條件
顯然,上面的自我呼叫必須有所節制,例如,將之置於 if 裡,只在某些條件成立下才允許呼叫自己
2.2. 練習
為 printN()加入停止條件,讓它可以傳入一個參數 n,輸出 1 到 n,即,當參數(n)的值小於 1 時就不再呼叫自己
1: #主程式 2: printN(5)
輸出以下結果
5 4 3 2 1
2.3. Recursion 能幹嘛?
上述這種 function 自己呼叫自己的有趣執行方式,除了能拿來取代重複架構(for, while)之外,還能用來做什麼事?
2.3.1. 例 1: N!
for-solution
1: def frac(n): 2: fsum = 1 3: for i in range(1, n+1): 4: fsum *= i 5: return fsum 6: 7: print(frac(5))
120
Recursion-solution
\[f(n)=
\begin{cases}
1 & n=1\\
n*f(n-1) & n \geq 2
\end{cases}\]
1: def frac(n): 2: if n == 1: 3: return 1 4: return n*frac(n-1) 5: #主程式 6: print(frac(5))
120
2.3.2. 例 2: 費氏數列
費氏數列數學表示法
\[f(n)=
\begin{cases}
1 & n=1\\
1 & n=2\\
f(n-1)+f(n-2) & n > 2
\end{cases}\]
for-solution
1: def fib(n): 2: if n <=2: 3: return 1 4: a = b = 1 5: for i in range(2, n): 6: c = a + b 7: a, b = b, c 8: return c 9: #主程式 10: print('The %d-th Fibonacci number = %d' %(5, fib(5)))
The 5-th Fibonacci number = 5
2.4. 實作練習
2.4.1. 最大公因數 Recursion
2.4.2. 計算 C(n, r)組合數
排列組合中的組合數公式為:
\[ C(n, r) = \frac{n!}{r! \times (n-r)!} \]
請利用遞迴寫一個 function 計算 C(n, r) 的值。
提示:可以先寫一個遞迴的階乘 function factorial(n) ,再利用它來計算組合數。
2.4.3. 調和級數 Recursion
寫一個遞迴 function 計算前 n-1 項的調和級數(harmonic sum),也就是正整數倒數的和:
\[ 1 + \frac{1}{2} + \frac{1}{3} + \frac{1}{4} + ... + \frac{1}{n-1} \]
2.4.4. 遞迴 List 加總 List recursion
寫一個遞迴 function,計算巢狀 List 中所有數字的總和。
測試資料: [1, 2, [3,4], [5,6]]
預期結果: 21
2.5. 作業
2.5.1. permutation
2.5.2. 遞迴計算
說明
寫一個遞迴 function,計算 n+(n-2)+(n-4)+… 的總和(一直加到 n-x ≤ 0 為止)。
輸入
6
輸出
12
2.5.3. 這不是巴斯卡
說明
給你一串數字,請你依序兩兩相加,直到剩下一個數字,並將過程反向輸出
輸入
1 2 3 4 5
輸出
48
28 28
8 12 16
3 5 7 9
1 2 3 4 5
3. yield 與 Generator
yield 的用法很像 return ,但有一個關鍵差異:=return= 會結束整個 function,而 yield 只是「暫停」function,等下一次被呼叫時會從暫停的地方繼續執行。
使用 yield 的 function 叫做 *generator function*,呼叫它不會立即執行,而是產生一個 generator object,可以用 next() 或 for 迴圈來逐步取值。
1: def countdown(n): 2: while n > 0: 3: yield n # 每次暫停在這裡,傳回 n 的值 4: n -= 1 5: 6: for num in countdown(5): 7: print(num, end=' ')
5 4 3 2 1
Generator 的好處是「用多少算多少」——不會一次把所有結果都存在記憶體裡,特別適合處理大量資料。
4. 星號
在 Python 中,星號除了用於乘法數值運算和冪運算外,還有一種特殊的用法“在變量前添加單個星號或兩個星號”,實現多參數的傳入或變量的拆解1。
5. 函數的參數傳遞
最初,星號變量是用在函數的參數傳遞上,其用法如下:
- *: 該位置接受任意多個非關鍵字(non-keyword)參數,在函數中將其轉化為元組(1,2,3,4)
- **: 該位置接受任意多個關鍵字(keyword)參數,在函數**位置上轉化為詞典 [key:value, key:value ]
5.1. 單星號的用法
1: def one(a, *b): 2: #a是一個普通的傳入參數; *b是一個非關鍵字(non-keyword)參數 3: print('a的type為:', type(a)) 4: print('a的value為:', a) 5: print('b的type為:', type(b)) 6: print('b的value為:', b) 7: 8: one(11, 22, 33, 44, 55)
a 的 type 為: <class 'int'> a 的 value 為: 11 b 的 type 為: <class 'tuple'> b 的 value 為: (22, 33, 44, 55)
由執行結果可以看出,第 1 個參數(11)對映到 function one 的第一個引數(a),至於剩下的 4 個參數(22, 33, 44, 55)則全都被引數(b)接收了,原因就是 b 前面的星號,這個單星號代表這個位置接收任意多個非關鍵字參數,接收後的所有資料會被轉成一個 tuple。
5.2. 單星號使用情境
例如,我們想寫個 function 計算某學生成績,這個 function 會傳若干成績,成績數不確定,最後傳回該生總分、平均。
1: def scoProc(*scores): 2: return sum(scores), sum(scores)/len(scores) 3: 4: sctot, scavg = scoProc(10, 30, 88, 17, 96, 94) 5: print('總分', sctot) 6: print('平均', scavg) 7:
總分 335 平均 55.833333333333336
5.3. 雙星號的用法
1: def two(a, **b): 2: #a是一個普通的關鍵字參數,**b是一個關鍵字雙星號參數 3: print('a的type為:', type(a)) 4: print('a的value為:', a) 5: print('b的type為:', type(b)) 6: print('b的value為:', b) 7: two(a=3, b=2, c=3, d=4, e=5, f=6)
a 的 type 為: <class 'int'>
a 的 value 為: 3
b 的 type 為: <class 'dict'>
b 的 value 為: {'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6}
由執行結果可以看出:第 1 個參數(3)的值被 assign 給引數 a,至於其他的 5 個參數(b, c, d, e, f)則都被第 2 個引數(b)接收了,原因是雙星號代表這個位置接收任意多個關鍵字參數,至於接收後的值,其類型變為 dict。
5.4. 雙星號使用情境
例如,我們想寫個 function 計算某學生成績,這個 function 會傳入各科成績,學科數不確定,最後傳回該生總分、平均。
1: def scoProc(**scores): 2: return sum(scores.values()), sum(scores.values())/len(scores) 3: 4: sctot, scavg = scoProc(ch=10, ma=30, en=88, ph=17, sc=96, ar=94) 5: print('總分', sctot) 6: print('平均', scavg) 7:
總分 335 平均 55.833333333333336
6. Function II
6.1. Function的特性
在第一章我們學了如何定義和呼叫 function。這一章要來看看 Python 的 function 還有哪些有趣的特性。在 Python 中,function 和整數、字串一樣,都是一種物件(object),因此可以像操作一般變數一樣來操作 function。
6.1.1. Function 為物件
既然 function 是物件,那就可以把它「指定」給其他變數。看看底下的例子:
1: def yell(text): 2: return text.upper() + '!' 3: 4: print(yell('hello')) 5: bark = yell # 把 yell 這個 function 指定給 bark 6: print(bark('woof')) # bark 和 yell 指向同一個 function,所以效果一樣
HELLO! WOOF!
注意第 5 行:我們把 yell 指定給 bark 時,後面沒有加小括號 () ,因為我們不是要「呼叫」它,而是要把這個 function 本身當成一個值來傳遞。
6.1.2. Function可被放在資料結構中
1: def yell(text): 2: return text.upper() + '!' 3: 4: bark = yell 5: 6: funcs = [bark, str.lower, str.capitalize] 7: 8: for func in funcs: 9: print(func('hey there!'))
HEY THERE!! hey there! Hey there!
6.1.3. Function可做為參數傳給其他function
Function是物件,所以除了能指定給變數,更可以當成其他function的參數。
1: def yell(text): 2: return text.upper() + '!' 3: 4: bark = yell 5: 6: def greet(func): 7: greeting = func('Hi, I am a Python Program') 8: print(greeting) 9: 10: greet(bark)
HI, I AM A PYTHON PROGRAM!
這種能接續其他function做為參數的格式也稱為高階function(higher-order function)。Python內建的map function即為higher-order的經典範例,它接受一個function object與一個可走訪物件(iterable)做為參數,然後會套用該function到iterable object內的每一元素,產出一系列結果:
1: list = map(function, iterable object)
注意: map() 回傳的不是 list,而是一個 map 物件 (惰性求值,lazy evaluation),也就是說它不會馬上算完全部結果,而是等你真的去取值的時候才一個一個算。所以如果你想看到完整結果,要用 list() 把它轉成 list。另外 map() 也可以傳多個 iterable:
1: # 多個 iterable 的用法 2: result = map(pow, [2, 3, 4], [3, 2, 1]) # 2^3, 3^2, 4^1 3: print(list(result))
[8, 9, 4]
例如:
1: def yell(text): 2: return text.upper() + '!' 3: 4: bark = yell 5: 6: list1 = ['hello', 'hey', 'hi'] 7: print(list(map(bark, list1)))
6.1.4. Function可構成巢狀結構
在function內定義function,稱之為巢狀function(nested function)或內部function(inner function)
1: def speak(text): 2: def whisper(t): 3: return t.lower() + '...' 4: return whisper(text) 5: 6: print(speak('Hello, world'))
hello, world...
每次呼叫speak時,它會先定義內部function,而這個inner function在speak外並不存在。若一定要在speak之外存取內部function whisper,則要先把內部function傳回給父function的呼叫者:
1: def get_speak_func(volume): 2: def whisper(text): 3: return text.lower() + '...' 4: def yell(text): 5: return text.upper() + '!' 6: if volume > 0.5: 7: return yell 8: else: 9: return whisper 10: 11: print(get_speak_func(0.3)) 12: print(get_speak_func(0.7))
<function get_speak_func.<locals>.whisper at 0x101986af0> <function get_speak_func.<locals>.yell at 0x101986a60>
6.1.5. Inner function可記住父function的參數狀態
Function還可「捕捉並保留父function的部份狀態」:
1: def get_speak_func(text, volume): 2: def whisper(): 3: return text.lower() + '...' 4: def yell(): 5: return text.upper() + '!' 6: if volume > 0.5: 7: return yell 8: else: 9: return whisper 10: 11: func = get_speak_func('Hello, world', 0.7) 12: print(func())
HELLO, WORLD!
這種會捕捉並記住外部參數的function,稱之為詞法閉包(lexical closure),或簡稱閉包(closure)。閉包會記住外圍程式範圍裡的變數值,即便其程式流程已經離開該變數所在的範圍也一樣。
簡單來說:closure 就像一個「帶著行李箱的 function」——它不只記得自己要做什麼事,還記得當初被建立時周圍的環境(變數)。上面的例子中,即使 get_speak_func 已經執行完畢,=func= 仍然記得 text 的值是 ’Hello, world’ 。
6.1.6. 物件也能像function一樣被呼叫
在Python中,function皆為object,反之object不見得是function,不過,我們能讓不是function的object變成可呼叫(callable),許多情況下,甚至可以把callable object當成function,在後面加上小括號來呼叫它,甚至能傳入參數。要使object變為callable,方法是在類別加入__call__:
1: class Addr: 2: def __init__(self, n): 3: self.n = n 4: def __call__(self, x): 5: return self.n + x 6: 7: plus_3 = Addr(3) #建立Addr物件,屬性n=3 8: print(plus_3(4))
7
6.2. lambda
lambda 提供了可用來宣告小型匿名 function 的快速宣告方式:
函式名稱 = lambda 參數:運算式
這種語法也稱為function expression,這與用def宣告的function一樣
1: add = lambda x, y : x + y 2: 3: print(add(5, 3))
8
那麼,以lambda定義function的優勢為何?
1: print((lambda x, y : x + y)(5, 3))
8
在許多場合中,使用lambda來定義臨時性的function就比較方便,但 lambda function 有個語法上的限制:只能含有一條運算式。
lambda function使用時機: 任何需要快速用上function object的地方,例如sorted():
1: sorted(iterable object, key=function)
其中參數key可輸入一個function, sorted()會依據function的傳回值來排序物件的元素,如果忽略key參數,則會依據原始元素(或者元素的第一個值)來排序。
1: tuples_list = [(1, 'd'), (2, 'b'), (4, 'a'), (3, 'c')] 2: print(sorted(tuples_list)) 3: 4: print(sorted(tuples_list, key=lambda x: x[1])) #指定key以tuple元素的第二子元素來排序 5: print(sorted(range(-5, 6), key=lambda x: x**2)) #指定依平方值來排序 6: # 上述方式只是為展示lambda用法,更精簡的方式為: 7: print(sorted(range(-5, 6), key=abs))
[(1, 'd'), (2, 'b'), (3, 'c'), (4, 'a')] [(4, 'a'), (2, 'b'), (3, 'c'), (1, 'd')] [0, -1, 1, -2, 2, -3, 3, -4, 4, -5, 5] [0, -1, 1, -2, 2, -3, 3, -4, 4, -5, 5]
使用lambda的缺點:不易閱讀
6.3. decorator
簡單來說,decorator(修飾器)就是一個「包裝函式的函式」——它能在不修改原本 function 程式碼的情況下,幫它加上額外的功能。想像你有一個蛋糕(原本的 function),decorator 就像在外面加上一層糖霜,蛋糕本身沒變,但吃起來多了新風味。
Python 的修飾器可用來間接修改 callable object(function, method, class)的行為,但不直接改動 object 本身,其用途包括:
- 加入日誌(logging)
- 存取權限管控與身份驗證
- 加入監測function及衡量執行時間
- 限制function執行頻率
- 用快取暫存function的執行結果
6.3.1. 修飾無參數function
先看一個最簡單的例子,然後拆解它的運作流程:
1: def uppercase(func): # (1) 定義一個 decorator,接收一個 function 做為參數 2: def wrapper(): # (2) 在裡面定義一個新的 function(叫 wrapper) 3: original_result = func() # (3) 呼叫原始 function 4: modified_result = original_result.upper() # (4) 對結果加工 5: return modified_result 6: return wrapper # (5) 傳回這個加工過的 wrapper 7: 8: @uppercase #以uppercase修飾greet 9: def greet(): 10: return 'Hello' 11: 12: print(greet())
HELLO
上面的 @uppercase 放在 greet() 上方,效果等同於:
1: greet = uppercase(greet)
也就是說,=greet= 被「偷天換日」了——原本的 greet 被丟進 uppercase() 裡加工,出來的是一個會自動轉大寫的新版 greet 。
6.3.2. 多重修飾
1: def strong(func): 2: def wrapper(): 3: return f'<strong> { func() } </strong>' 4: return wrapper 5: 6: def emphasis(func): 7: def wrapper(): 8: return f'<em> { func() } </em>' 9: return wrapper 10: 11: @strong 12: @emphasis 13: def greet(): 14: return 'Hello!' 15: 16: print(greet) 17: print(greet())
<function strong.<locals>.wrapper at 0x10fd3ab80> <strong> <em> Hello! </em> </strong>
唯一要注意的是:若套用修飾器的層級過多會影響程式執行效能。
Decorator 語法小整理:
@decorator語法等同於func = decorator(func)——就是把 function 丟進去包一層再指派回來- Decorator 本質上就是一個「接收函式、回傳函式」的函式
- Python 有幾個常見的內建 decorator:
@staticmethod— 定義不需要存取 object 或 class 的靜態方法@classmethod— 定義可存取 class 本身(而非 object)的方法@property— 讓 method 可以像 attribute 一樣用obj.xxx存取
6.3.3. 修飾有傳入參數的function
若要修飾的function有帶參數,則wrapper()要改為wrapper(*args, **kwargs),這分別用來收集所有傳入的positional與keyword類參數,以tuple及dict形式儲存在args與kwargs變數裡,然後wrapper利用*與**將收集到的參數unpack後傳給原始func,如此就不會限制到參數個數。
1: def trace(func): 2: def wrapper(*args, **kwargs): 3: print(f'trace: callable function {func.__name__}, with arguments: {args}, {kwargs}') 4: original_results = func(*args, **kwargs) 5: print(f'trace: function {func.__name__} return results: {original_results}!') 6: return original_results 7: return wrapper 8: 9: @trace 10: def say(name, line): 11: return f'{name}, {line}' 12: 13: print(say('James', 'hi'))
trace: callable function say, with arguments: ('James', 'hi'), {}
trace: function say return results: James, hi!
James, hi
幫function加上效能監測功能
1: import time 2: def eval_time(func): 3: def wrapper(*args, **kwargs): 4: start = time.perf_counter() 5: res = func(*args, **kwargs) 6: finish = time.perf_counter() 7: print(f'Finished in {round(finish-start, 2)} second(s)') 8: return res 9: return wrapper 10: 11: @eval_time 12: def sigma(n): 13: sum = 0 14: for i in range(n): 15: sum = sum + i 16: return sum 17: 18: print(sigma(100000000))
Finished in 5.3 second(s) 4999999950000000
6.4. *args and **kwargs
*與**能讓function接受數量不定的額外參數,讓module與class能提供更有彈性的存取介面:
1: def foo(required, *args, **kwargs): 2: print(required) 3: if args: 4: print(f'args: {args}') 5: if kwargs: 6: print(f'kwargs: {kwargs}') 7: 8: foo('1. Hi') 9: foo('2. Hi', 1, 2, 3) 10: foo('3. Hi', 1, 2, 3, Key1='value1', key2=456)
1. Hi
2. Hi
args: (1, 2, 3)
3. Hi
args: (1, 2, 3)
kwargs: {'Key1': 'value1', 'key2': 456}
- *args接收額外的位置型參數(positional parameters)(沒有鍵的參數),將之放入一個tuple。
- **kwargs接收額外的關鍵字參數(keyword parameters)(有鍵的參數),將之放入一個dict。
6.5. 拆解函式參數(Unpack)
* 與 ** 除了用在定義 function 時接收不定數量參數,也可以反過來在 呼叫 function 時 使用,把現有的資料「拆開」傳入:
*加在 list 或 tuple 前面:會把裡面的元素一個一個拆開,當成位置型參數(positional parameters)傳入**加在 dict 前面:會把 key-value 拆開,當成關鍵字參數(keyword parameters)傳入
1: def print_vector(x, y, z): 2: print(f'<{x}, {y}, {z}>') 3: 4: tuple_vector = (1, 0, 1) 5: print_vector(tuple_vector[0], tuple_vector[1], tuple_vector[2]) 6: print_vector(*tuple_vector) 7: 8: dict_vector = { 'y': 4, 'z': 5, 'x': 3} 9: print_vector(**dict_vector)
<1, 0, 1> <1, 0, 1> <3, 4, 5>
6.6. 要不要寫 return?
return與return None效果一樣,都會傳回None- 如果 function 沒有需要傳回的值,可以省略
return。例如,一個只負責print的 function 並沒有任何值需要傳回,硬寫return反而很奇怪 - 小技巧:如果你的 function 是「做事」(印出、儲存、修改),通常不需要 return;如果是「算東西」(計算面積、找最大值),就需要 return 把結果傳出來
7. Class v.s. Object
到目前為止,我們一直在使用 Python 內建的型態(int, str, list…)。但如果我們想自己「發明」一種新的型態呢?例如,你想寫一個程式管理學校的學生資料,每個學生都有姓名、學號、成績——這時候 class 就派上用場了。
7.1. 什麼是class? 什麼是object?
影片參考:https://youtu.be/JeznW_7DlB0
在 Python 中,所有東西都是物件(object)。
1: a = 2022 2: b = 'TNFSH' 3: 4: def c(): 5: print('TNFSH') 6: 7: print(type(a)) 8: print(type(b)) 9: print(type(c))
<class 'int'> <class 'str'> <class 'function'>
由上面的例子,我們可以發現:在Python裡,幾乎所有我們用到的變數、函數都是class。
當我們寫下
1: a = 2022
其實是在說,我們有一個變數,它是一種int class,它的值是2022。這個變數就是一個object: 某種屬於某一類class的實體。
一種常見的說法是:class是一張藍圖,依照這張藍圖蓋出的房子有同樣的架構,有同樣的功能,但是可能在外觀或顏色上會有些許差異,就好比一樣是整數物件,每個變數的值可能會有所不同。
不同的class有其特定的功能與限制,例如:
1: x = 1 2: y = 'TNFSH' 3: print(x+y)
執行上述程式會得到以下錯誤訊息:
File "<stdin>", line 3, in <module> TypeError: unsupported operand type(s) for +: 'int' and 'str'
這裡告訴我們:int與str這兩種class的object不支援+這個運算。我們再來看另一個例子:
1: x = 'tnfsh' 2: y = 1 3: print(x.upper()) 4: print(y.upper())
TNFSH
上述程式會產生如下錯誤訊息:
1: Traceback (most recent call last): 2: File "<stdin>", line 4, in <module> 3: AttributeError: 'int' object has no attribute 'upper'
意思是:int這種class的object沒有一種叫做upper的屬性。這就是我們上面所說的,不同的class有其特定的功能與限制。
7.2. 建立自己的class
用 class 關鍵字就能定義一個新的 class。class 裡面可以定義 method(屬於這個 class 的 function),每個 method 的第一個參數一定要寫 self ,它代表「這個 object 本身」。
1: class Dog: 2: def bark(self): 3: print('汪汪汪') 4: 5: a = Dog() # 用 Dog() 建立一個 Dog 物件 6: print(type(a)) # 看看它的型態 7: a.bark() # 呼叫這個物件的 bark method
<class '__main__.Dog'> 汪汪汪
在上述範例中,我們建立了一個叫 Dog 的 class,然後用 Dog() 建立一個屬於 Dog 這個 class 的 object。
從這個 object 的 type,可以看出它是 <class '__main__.Dog'> ,這裡的 __main__ 意思是這個 class 被定義在目前這支 Python 程式中。
7.2.1. init 建構子
大多數 class 都需要一個 __init__ method(建構子),它會在建立 object 時自動被呼叫,通常用來設定 object 的初始屬性:
1: class Dog: 2: def __init__(self, name, age): 3: self.name = name # 設定 object 的 name 屬性 4: self.age = age # 設定 object 的 age 屬性 5: 6: def bark(self): 7: print(f'{self.name} 說:汪汪汪!') 8: 9: def info(self): 10: print(f'名字:{self.name},年齡:{self.age} 歲') 11: 12: dog1 = Dog('小白', 3) 13: dog2 = Dog('阿黑', 5) 14: dog1.bark() 15: dog2.bark() 16: dog2.info()
小白 說:汪汪汪! 阿黑 說:汪汪汪! 名字:阿黑,年齡:5 歲
上面的例子中,=Dog(’小白’, 3)= 會自動呼叫 __init__(self, '小白', 3) ,把名字和年齡存進這個 object 裡。之後透過 self.name 和 self.age 就能存取這些資料。
7.3. == 與 is 的差異
==比較的是「值(value)」是否相等:內容一樣就是 Trueis比較的是「身份(identity)」是否相同:必須是同一個物件才是 True(可以想成:是不是住在記憶體中的同一個地址)
1: a = [1, 2, 3] 2: b = [1, 2, 3] 3: c = a 4: print(a == b) 5: print(a is b) 6: print(a == c) 7: print(a is c)
True False True True
上面的例子中,=a= 和 b 雖然內容一樣(都是 [1, 2, 3]),但它們是分別建立的兩個 list,住在不同的記憶體位址,所以 a == b 是 True,但 a is b 是 False。而 c = a 只是幫 a 取了一個別名,所以 a is c 是 True。
實用建議:一般比較資料時用 == 就好。只有在你特別需要確認「這是不是同一個物件」時才用 is (最常見的用法是 ~if x is None~)。
7.4. 淺複製與深複製(Shallow copy v.s. Deep copy)
簡單來說,淺與深的區別2:
- 淺複製僅複製容器中元素的地址
- 深複製完全複製了一份副本,容器與容器中的元素地址都不一樣
7.4.1. shallow copy
1: xs = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] 2: ys = list(xs) # shallow copy 3: print(xs == ys) # 二者內容相同 4: print(xs is ys) # 但為不同物件 5: 6: xs.append([10, 11, 12]) 7: print(xs) 8: print(ys) 9: 10: # 但若是修改二者相同的部份,如 11: xs[1][0] = 'X' 12: print(xs) 13: print(ys)
True False [[1, 2, 3], [4, 5, 6], [7, 8, 9], [10, 11, 12]] [[1, 2, 3], [4, 5, 6], [7, 8, 9]] [[1, 2, 3], ['X', 5, 6], [7, 8, 9], [10, 11, 12]] [[1, 2, 3], ['X', 5, 6], [7, 8, 9]]
由上述例子中可發現,xs與ys其實共享同一份資料。
7.4.2. deep copy
1: import copy 2: xs = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] 3: zs = copy.deepcopy(xs) 4: 5: print(xs == zs) 6: print(xs is zs) 7: 8: xs[1][0] = 'X' 9: print(xs) 10: print(zs)
True False [[1, 2, 3], ['X', 5, 6], [7, 8, 9]] [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
7.4.3. copy any object
不管想copy什麼object,包括自訂物件,解決之道亦是用copy module的copy()與deepcopy()。
1: import copy 2: 3: class Point: 4: def __init__(self, x, y): 5: self.x = x 6: self.y = y 7: def __repr__(self): 8: return f'Point({self.x}, {self.y})' 9: 10: a = Point(23, 42) 11: b = Point(23, 42) 12: #b = copy.copy(a) 13: print(a) 14: print(b) 15: print(a == b) 16: print(a is b)
Point(23, 42) Point(23, 42) False False
7.5. 繼承(Inheritance)
繼承是 OOP 的核心概念之一——子類別可以「繼承」父類別的所有屬性與方法,然後再加上自己的東西或覆寫(override)父類別的行為。
1: class 子類別(父類別): 2: def __init__(self, ...): 3: super().__init__(...) # 呼叫父類別的建構子
重點整理:
class 子類別(父類別):— 子類別會繼承父類別的所有屬性與方法super().__init__()— 在子類別的__init__中呼叫父類別的建構子,確保父類別的初始化邏輯也有執行- 子類別可以覆寫(override)父類別的方法,只要定義同名的 method 就好
- Python 支援多重繼承:=class C(A, B):= ,不過用的時候要小心,繼承鏈太複雜會讓人頭痛
1: class Animal: 2: def __init__(self, name): 3: self.name = name 4: 5: def speak(self): 6: return f'{self.name} 發出聲音' 7: 8: class Dog(Animal): 9: def __init__(self, name, breed): 10: super().__init__(name) # 呼叫 Animal 的 __init__ 11: self.breed = breed 12: 13: def speak(self): # 覆寫父類別的 speak 14: return f'{self.name} 說:汪汪!' 15: 16: dog = Dog('小白', '柴犬') 17: print(dog.speak()) 18: print(f'品種:{dog.breed}')
小白 說:汪汪! 品種:柴犬
7.6. ABC: Abstract Base Class
C++、Java等語言都有「介面」(interface)這種本身無法建立object、卻能當成建立object template的機制。Python則可藉由ABC來實作。藉由ABC來建立class,便是可確保繼承之sub-class均有正確的特定method。
1: from abc import ABC, abstractmethod 2: 3: class Base(ABC): 4: 5: @abstractmethod 6: def foo(self): 7: pass 8: 9: @abstractmethod 10: def bar(self): 11: pass 12: 13: class Concrete(Base): 14: def foo(self): 15: pass 16: 17: print(issubclass(Concrete, Base))
True
7.7. 物件方法、類別方法與靜態方法
在 class 中可以定義三種不同類型的 method,它們的差異在於能存取的資料範圍不同:
1: class MyClass: 2: 3: def objmethod(self): #object method 4: print(f'呼叫object method: {self}') 5: 6: @classmethod 7: def clsmethod(cls): 8: print(f'呼叫class method: {cls}') 9: 10: @staticmethod 11: def stcmethod(): 12: print(f'呼叫static method') 13: 14: obj = MyClass() 15: obj.objmethod() 16: obj.clsmethod() 17: obj.stcmethod()
呼叫object method: <__main__.MyClass object at 0x1081f7940> 呼叫class method: <class '__main__.MyClass'> 呼叫static method
- objmethod為一般object method,必須有self參數,該參數指向object本身
- clsmethod為class method,必須有cls參數,指向class本身
- stcmethod為static method,沒有參數,無法修改物件或類別狀態,只能處理user傳入的參數
7.7.1. DEMO
1: class Drink: 2: def __init__(self, name, price, counts): 3: self.name = name 4: self.price = price 5: self.counts = counts 6: 7: def costs(self): 8: return self.drink_costs(self.price, self.counts) 9: 10: @classmethod 11: def blacktea(cls): 12: return cls('紅茶', 1, 25) 13: 14: @classmethod 15: def coffee(cls): 16: return cls('熱美式', 1, 50) 17: 18: @staticmethod 19: def drink_costs(price, counts): 20: return price * counts 21: 22: drink1 = Drink.blacktea() 23: drink2 = Drink.coffee() 24: drink3 = Drink('義式', 60, 3) 25: print(f'{drink1.name}') 26: print(f'{drink2.price}') 27: print(f'{drink3.name!r} * {drink3.counts} = {drink3.costs()}')
紅茶 1 '義式' * 3 = 180
7.8. 類別變數與實例變數(class variable v.s. instance variable)
- class variable(類別變數): 宣告在 class 定義裡,但位置在所有 method 之外。所有由這個 class 建立的 object 都共享同一份資料
- instance variable(實例變數): 屬於由 class 所建立的某個 instance,其內容並非存在 class 中,而是由各別 instance 各自負責。每個 object 有自己獨立的一份
7.8.1. 差異
1: class Dog: 2: num_dogs = 0 #Demo class variable的適用時機 3: num_leg = 4 4: 5: def __init__(self, name): 6: self.name = name 7: self.__class__.num_dogs += 1 8: 9: dd = Dog('DaiDai') 10: bd = Dog('Bad luck') 11: lk = Dog('Lucky') 12: bd.num_leg = 3 13: print(dd.num_leg) 14: print(bd.num_leg) 15: print(f'目前共有{Dog.num_dogs}隻狗')
4 3 目前共有3隻狗
由class variable num_dogs的示範也可看出,善用class variable可以在各個instance object間取得某程程度的連繫。
8. 資料型別 II
8.1. Dict
8.1.1. collections.ChainMap
collections.ChainMap可以把多個dict集結串成單一個dict,如
1: import collections 2: 3: dict1 = {'one':1, 'two': 2} 4: dict2 = {'two':'貳', 'three': 'III', 'four': 4} 5: chain = collections.ChainMap(dict1, dict2) 6: 7: print(chain) 8: print(chain['two']) 9: chain['five'] = 5 10: print(chain)
ChainMap({'one': 1, 'two': 2}, {'two': '貳', 'three': 'III', 'four': 4})
2
ChainMap({'one': 1, 'two': 2, 'five': 5}, {'two': '貳', 'three': 'III', 'four': 4})
要留意的是:若對ChainMap做新增、修改、刪除,則只會影響裡面的第一個dict。
8.2. types.MappingProxyType
透過MappingProxyType class可以把dict變為唯讀。
1: from types import MappingProxyType 2: 3: writable = {'one': 1, 'two': 2} 4: writable['three'] = 3 5: readOnly = MappingProxyType(writable) 6: readOnly['three'] = 4 #TypeError: 'mappingproxy' object does not support item assignment 7: readOnly['four'] = 4 #TypeError: 'mappingproxy' object does not support item assignment
8.3. array.array
若要和C語言程式交換資料,或是只需要一個儲存數值型態資料的空間,則可用array.array,優點是比list或tuple省空間。array.array的method與list大致相同,許多情況下甚至可直接交換二者的資料型別而無需修改相關程式碼。
1: import array 2: arr = array.array('f', (1.0, 3.5, 2.0, 6.1)) 3: print(arr) 4: print(arr[1]) 5: arr.append(2.1) 6: del arr[1] 7: print(arr)
array('f', [1.0, 3.5, 2.0, 6.099999904632568])
3.5
array('f', [1.0, 2.0, 6.099999904632568, 2.0999999046325684])
8.4. Record(紀錄型態)
當我們需要把多個相關的資料欄位組合在一起時(就像資料庫裡的一筆「紀錄」),Python 提供了好幾種做法。以下用儲存一台車的紀錄(color, mileage, automatic)為例,比較不同做法的優缺點:
8.4.1. list/tuple
- 建立速度快、執行效率高,
- 但沒有欄位名稱,建立資料時可能弄錯順序
- 很難檢查兩個資料物件是否有一致的欄位
1: car1 = ['red', 3812, True] #list, 可變 2: car2 = ('blue', 3123, False) #tuple, 不可變 3: car3 = (343, 'black', True, 'James') #順序錯誤、欄位也不一致
8.4.2. dict
- 可透過key/value來當成欄位名稱
- 仍缺乏欄位監控機制,防止使用者在建立object時打錯或漏打欄位
1: Car = { 2: 'color': 'red', 3: 'mileage': 3213, 4: 'automatic': True 5: } 6: print(Car) 7: print(Car['color']) 8: Car['windshield'] = 'broken' 9: print(Car)
{'color': 'red', 'mileage': 3213, 'automatic': True}
red
{'color': 'red', 'mileage': 3213, 'automatic': True, 'windshield': 'broken'}
8.4.3. 自訂類別
- 麻煩,在其__init__建構子內要設定每個欄位,還要自己寫__repr__ method
1: class Car: 2: def __init__(self, color, mileage): 3: self.color = color 4: self.mileage = mileage 5: 6: car = Car('red', 1234) 7: car.mileage = 4343 #可修改欄位內容 8: car.automatic = True #可新增欄位
8.4.4. typing.NamedTuple
- readonly
- 欄位型別無強制性
1: from typing import NamedTuple 2: 3: class Car(NamedTuple): 4: color: str 5: mileage: float 6: automatic: bool 7: 8: car = Car('red', 3123, True) 9: print(car) 10: #car.mileage = 3123 # 不能變更欄位內容 11: #car.windshield = 'broken' #不能新增欄位 12: car2 = Car('blue', 'test', 1234) 13: print(car2)
Car(color='red', mileage=3123, automatic=True) Car(color='blue', mileage='test', automatic=1234)
8.4.5. types.SimpleNamespace
- 本質上是dict,把dict的key變成class attribute
- 可以新增、修改、刪除attribute
- 不若想動用到class,此為簡易替代品
- 仍缺乏結構
1: from types import SimpleNamespace 2: 3: car = SimpleNamespace(color = 'red', 4: mileage = 1341, 5: automatic = True) 6: 7: car.color = 'blue' 8: print(car)
namespace(color='blue', mileage=1341, automatic=True)
8.4.6. dataclass (Python 3.7+)
@dataclass 是 Python 3.7 引入的語法糖,幫你省掉一堆重複的樣板程式碼(boilerplate):
@dataclass會自動產生__init__()、__repr__()、__eq__()等 method,不用自己寫- 可加入自訂method
- 可繼承(跟一般 class 一樣用
class 子類別(父類別):) @dataclass(frozen=True)— 建立不可變(immutable)的資料類別,設定後就不能改屬性值- 欄位可設預設值:例如
name: str預設為 ’unknown’
1: from dataclasses import dataclass 2: 3: @dataclass 4: class Car: 5: color: str 6: mileage: float 7: automatic: bool 8: 9: def mileage_km(self): #可自訂method 10: return self.mileage * 1.609 11: 12: car = Car('red', 3123, True) 13: print(dir(car)) 14: print(car.mileage_km) 15: print(car.__repr__) 16: 17: @dataclass 18: class ElectronicCar(Car): #繼承 19: charge: float = 0.0 20: 21: car2 = ElectronicCar('white', 3123, True, 1000) 22: print(car2) 23:
['__annotations__', '__class__', '__dataclass_fields__', '__dataclass_params__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'automatic', 'color', 'mileage', 'mileage_km'] <bound method Car.mileage_km of Car(color='red', mileage=3123, automatic=True)> <bound method __create_fn__.<locals>.__repr__ of Car(color='red', mileage=3123, automatic=True)> ElectronicCar(color='white', mileage=3123, automatic=True, charge=1000)
slots
如果你的程式會建立同一類別的大量object,但不會增刪object attribute,則可以考慮使用__slots__來節省object占用的記憶體,同時加快存取速度。
1: from dataclasses import dataclass 2: 3: @dataclass 4: class Car: 5: 6: __slots__ = ['color', 'mileage', 'automatic'] 7: 8: color: str 9: mileage: float 10: automatic: bool
__slots__不限於dataclass,在任何class均可使用
8.4.7. struct.Struct
- 與C的struct交換資料的管道
1: from struct import Struct 2: 3: MyStruct = Struct('1?f') #指定資料格式 4: data = MyStruct.pack(23, False, 42.0) #資料打包成二進位資料 5: print(data) 6: x = MyStruct.unpack(data) 7: print(x)
8.5. Set
- Python建立set,除了用{}、也可以用set comprehension
- 若要建立empty set,一定要call set()建構子,因為空的{}會被當成dict
1: vowels = {'a', 'e', 'i', 'o', 'u'} 2: squares = { x ** 2 for x in range(10) } 3: empty = set() 4: 5: print(vowels) 6: print(squares) 7: print(empty)
{'a', 'o', 'i', 'u', 'e'}
{0, 1, 64, 4, 36, 9, 16, 49, 81, 25}
set()
8.5.1. frozenset
- frozenset class為set的不可變版本,一旦建立就無法增刪修,只能查詢
- 但frozenset為靜態iterable object,故為hashable object,能當成dict object的key或其他set的element,這是一般set無法做到的事
1: vowels = frozenset({'a', 'e', 'i', 'o', 'u'}) 2: d = {vowels: 'hello'} # set變為dict的key 3: print(d) 4:
{frozenset({'e', 'o', 'u', 'a', 'i'}): 'hello'}
8.5.2. collections.Counter
- collections module底下的Counter實作了「多重集合」(multisets),能輸入多個iterable object(set, dict, string)並統整各元素的出現次數
- Counter實際為dict的subclass,當我們把新的iterable object輸入Counter object時,該iterable object的element會新增為dict的key,而該element出現次數則為dict的value
1: from collections import Counter 2: 3: inventory = Counter() 4: loot = {'sward': 1, 'bread': 3} #裝備品名及數量 5: inventory.update(loot) 6: print(inventory) 7: 8: more_loot = ['sward', 'coins'] 9: inventory.update(more_loot) 10: 11: yet_more_loot = ['sward', 'bread', 'drink'] 12: inventory.update(yet_more_loot) 13: print(inventory)
Counter({'bread': 3, 'sward': 1})
Counter({'bread': 4, 'sward': 3, 'coins': 1, 'drink': 1})
8.6. Stack
Stack(堆疊)是一種 *後進先出*(Last In, First Out, LIFO)的資料結構。想像一疊盤子:你只能從最上面放盤子(push),也只能從最上面拿盤子(pop)。Python 有幾種方式可以實作 Stack:
8.6.1. list
- python內部以動態陣列來實作list,所以會配置比element所需更大的空間,視需要增減。故push與pop不見會需要調整大小,平均效率可達O(1)
- 但為了達到這種效率,element必須從tail做push, pop
- 若改由list的head做push,pop,則list內所有element均需位移,效率會降為O(n)
1: a = [] 2: a.append('eating') 3: a.append('sleeping') 4: a.append('coding') 5: print(a) 6: a.pop() 7: print(a) 8: 9: #自head做push, pop 10: a.insert(0, 'drinking') 11: a.insert(0, 'playing') 12: a.pop(0) 13: print(a)
['eating', 'sleeping', 'coding'] ['eating', 'sleeping'] ['drinking', 'eating', 'sleeping']
8.6.2. collections.deque
- 快速穩定的stack
- 支援從head,tail做push,pop,效率均為O(1)
- 若要取出中間element,效率為O(n)
1: from collections import deque 2: 3: a = deque() 4: 5: a.append('eating') 6: a.append('sleeping') 7: a.append('coding') 8: print(a) 9: a.pop() 10: print(a) 11: 12: #自中間取值,效能差 13: print(a[1]) 14:
deque(['eating', 'sleeping', 'coding']) deque(['eating', 'sleeping']) sleeping
8.6.3. queue.LifoQueue
- 可用於multithreading進行parallelism平行運算時的共享資料
- 這些資料結構還提供了上鎖機制,好讓同一時間只有一個thread能從queue取出資料
- queue module裡的LifoQueue class雖名為queue,但採Last In, First Out(LIFO),運作上與Stack相同
1: from queue import LifoQueue 2: s = LifoQueue() 3: s.put('eating') 4: s.put('sleeping') 5: s.put('coding') 6: print(s.get()) 7: print(s.get())
coding sleeping
8.7. Queue
Queue(佇列)是一種 *先進先出*(First In, First Out, FIFO)的資料結構。想像排隊買飲料:先排的人先買,後排的人後買。以下是幾種實作 Queue 的方式:
8.7.1. list
- 用 list 來當 Queue 非常慢,沒有效率(因為從頭部取出元素時,後面所有元素都要往前移)
8.7.2. collections.deque
- 快速穩定
1: from collections import deque 2: q = deque() 3: q.append('eating') 4: q.append('sleeping') 5: q.append('coding') 6: q.append('writing') 7: print(q) 8: print(q.popleft()) 9: print(q.popleft()) 10: print(q) 11:
deque(['eating', 'sleeping', 'coding', 'writing']) eating sleeping deque(['coding', 'writing'])
8.7.3. queue.Queue
- 和queue.LifoQueue一樣,內建上鎖機制,可以用來讓multithreading共享資料或任務
8.7.4. multiprocessing.Queue
- multi-thread在python中其實不算真正的平行運算,各thread實際上是在同一個interpreter下執行,只用到一個core,藉由不斷切換的方式來達到平行運算的效果。
8.7.5. priority queue
- 不遵循FIFO原則,而是以priority為順序考量
- priority由totally-ordered key來決定
8.7.6. heapq
- 借用list實作的binary tree(heap)結構
- 可實作priority
- 可於O(log n)的時間完成插入元素或取出最小元素
- heapq的各note實際上是存在一個list中;node在list中是依binary tree的順序儲存
- 借由binary tree所依據的sort key即可實作出priority queue
- 限制之一是預設為由小到大排序
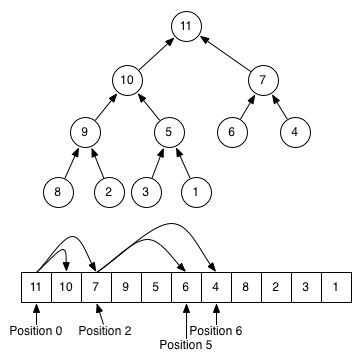
Figure 1: heapq
1: import heapq 2: 3: q = [] 4: heapq.heappush(q, (2, 'coding')) 5: heapq.heappush(q, (1, 'eating')) 6: heapq.heappush(q, (3, 'sleeping')) 7: while q: 8: next_item = heapq.heappop(q) 9: print(next_item)
(1, 'eating') (2, 'coding') (3, 'sleeping')
8.7.7. queue.PriorityQueue
- 可用於multi-thread的heapq
9. LOOP
9.1. enumerate()
- 如果想保留for-each的寫法,但同時又希望能取得每個element的index
1: my_items = ['a', 'b', 'c'] 2: print(list(enumerate(my_items))) 3: for i, item in enumerate(my_items): 4: print(f'{i}: {item}')
[(0, 'a'), (1, 'b'), (2, 'c')] 0: a 1: b 2: c
9.2. zip()
- 可用來同時走訪多個container
- 可用來旋轉二維list
1: my_items = ['a', 'b', 'c'] 2: my_no = [1, 2, 3] 3: print(list(zip(my_no, my_items))) 4: 5: for no, item in zip(my_no, my_items): 6: print(f'{no}: {item}')
[(1, 'a'), (2, 'b'), (3, 'c')] 1: a 2: b 3: c
9.2.1. 旋轉list
1: a = [1, 2, 3] 2: b = [4, 5, 6] 3: c = [7, 8, 9] 4: matrix = [a, b, c] 5: print(matrix) 6: print(list(zip(*matrix))) 7: print(list(zip(*reversed(matrix))))
[[1, 2, 3], [4, 5, 6], [7, 8, 9]] [(1, 4, 7), (2, 5, 8), (3, 6, 9)] [(7, 4, 1), (8, 5, 2), (9, 6, 3)]
9.3. comprehension
- 即簡單的單行for-loop
- 可以讓我們用單行程式產生出包含特定元素的list, set, dict
9.3.1. 語法
1: list = [運算式 for 變數 in iterable object]
9.3.2. list comprehension
1: squares = [x ** 2 for x in range(10)] 2: print(squares)
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
9.3.3. comprehension過濾條件
1: list = [x ** 2 for x in range(10) if x % 2 == 0] 2: print(list)
[0, 4, 16, 36, 64]
9.3.4. set與dict comprehension
1: setA = [x ** 2 for x in range(10)] 2: print(setA) 3: dicA = {x: x ** 2 for x in range(10)} 4: print(dicA)
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
9.4. list
9.4.1. slice
語法
1: list[index start: index end: step]
1: nums = [1, 2, 3, 4, 5, 6, 7, 8] 2: print(nums[::]) 3: print(nums[1:6:2]) 4: nums[1:6:2] = [10, 20, 30] 5: print(nums) 6:
[1, 2, 3, 4, 5, 6, 7, 8] [2, 4, 6] [1, 10, 3, 20, 5, 30, 7, 8]
9.4.2. copy
1: l = list(range(6)) 2: print(l) 3: cl = l # 指向同一list 4: dl = l[::] # shallow copy 5: l[3] = 10 6: print(cl) 7: print(dl)
[0, 1, 2, 3, 4, 5] [0, 1, 2, 10, 4, 5] [0, 1, 2, 3, 4, 5]
10. Python 套件管理
10.1. pip v.s. conda
10.1.1. pip or conda
- Python 的一大優勢之一便是龐大的第三方函式庫,讓使用 Python 的程式設計師可以方便地進行網路資料下載與解析、資料視覺化,甚至是大數據分析與人工智慧等工作。
- 目前用來管理這些龐大套件的工具主要有二:pip 與 Conda。
10.1.2. pip
- Pip是Python Packaging Authority推薦、用於從Python Package Index安裝套件的工具,提供了對 Python 套件的搜尋、下載、安裝、卸載的功能。
- 若在 python.org 下載最新版本的 python,則已內建 pip 安裝套件。 Python 3.4+ 以上版本均已包括 pip
- 該工具類似 Linux 下的 apt/yum 或 MAC 下的Homebrew。
10.1.3. conda
- Conda 是一個開源的跨平台工具軟體,它被設計作為 Python、R、Lua、Scala、C/C++、FORTRAN/ 與 Java 等任何程式語言的套件、依賴性以及工作環境管理員,特別受到以 Python 作為主要程式語言的資料科學團隊所喜愛。
- 適用平台:Windows, macOS, Linux
- 傳統 Python 使用者以 pip 作為套件管理員(package manager)、以 venv 作為工作環境管理員(environment manager),而 conda 則達成了「兩個願望、一次滿足」既可以管理套件亦能夠管理工作環境。3
10.1.4. 兩者的共同點
- 都以 Python 撰寫
- 都是開源軟體(Conda 採 BSD 授權、pip 採 MIT 授權)
- 五種開源授權規範的比較 (BSD, Apache, GPL, LGPL, MIT)
10.1.5. conda、Anaconda 與 Miniconda 的差異
- conda 既是一個命令列工具,也是一個 Python 套件。4
- Anaconda 發行版會預裝很多套件,而 Miniconda 是最小的 conda 安裝環境, 一個乾淨的 conda 環境。
- pip 只用於安裝 Python 套件,而 conda 可以安裝管理任何語言的套件。
不一定要安裝 Anaconda 或 Miniconda,也可透過 pip 直接安裝 conda
pip install conda
10.2. conda 安裝與使用
10.2.2. 安裝conda
for macOS
1: brew install --cask anaconda 2: export PATH="/usr/local/anaconda3/bin:$PATH"
10.2.3. 移除
- Windows: uninstall
- Linux/macOS:
rm -rf ~/anaconda
10.3. python package 安裝(conda)
安裝 package:
conda install packageName
conda install pandas
移除 package:
conda remove packageName
conda remove pandas
安裝特定版本 python
conda install python=version
conda install python=3.5
了解目前系統可用套件
conda list
10.4. Python 常用函式庫
10.4.1. 爬蟲
Scrapy:

- Scrapy,Python 開發的一個快速、高層次的 web 數據抓取框架,用於抓取 web 站點並從頁面中提取結構化的數據。Scrapy 用途廣泛,可以用於數據挖掘、監測和自動化測試5。
- Scrapy 吸引人的地方在於它是一個框架,任何人都可以根據需求方便的修改。它也提供了多種類型爬蟲的基類,如 BaseSpider、sitemap 爬蟲等。
beautifulsoup4:


10.4.2. 網站
Django

- Django (ˈdʒæŋɡoʊ jang-goh) 可以說是 Python 最著名的 Web Framework,一些知名的網站如 Pinterest, Instagram, Disqus 等等都使用過它來開發。10
- 免費開放原始碼
- 著重快速開發、高效能
- 遵從 DRY ( Don’t Repeat Yourself ) 守則,致力於淺顯易懂和優雅的程式碼
- 使用類似 Model–view–controller (MVC) pattern 的架構
- 10 Popular Websites Built With Django
Flask

- Flask 是一個使用 Python 撰寫的輕量級 Web 應用程式框架,由於其輕量特性,也稱為
micro-framework(微框架)。11 - Flask 和 Django 不同的地方在於 Flask 給予開發者非常大的彈性(當然你也可以說是
需要思考更多事情),可以選用不同的用的 extension 來增加其功能。 - 相比之下,Django 雖然完善但技術選擇相對不彈性,不論是 ORM、表單驗證或是模版引
擎都有自己的作法。 - 沒有最好的框架,只有合適的使用情境。
10.4.3. 資料處理科學計算
Numpy

- Numpy 底層以 C 和 Fortran 語言實作,所以能快速操作多重維度的陣列。12
- 當 Python 處理龐大資料時,其原生 list 效能表現並不理想(但可以動態存異質資料),而 Numpy 具備平行處理的能力,可以將操作動作一次套用在大型陣列上。
- 此外 Python 其餘重量級的資料科學相關套件(例如:Pandas、SciPy、Scikit-learn 等)都幾乎是奠基在 Numpy 的基礎上。
Scipy

- 科學計算神器
- Numpy 是以矩陣基礎做數據的數學運算,SciPy 就是以 Numpy 為基礎做科學、工程的運算處理的 package,包含統計、優化、整合、線性代數、傅立葉轉換圖像等較高階的科學運算。13
Pandas

- 建構在 NumPy 之上,提供資料結構與資料處理工具,讓資料清理與分析更為快速與方便
- 適合處理表格或異質資料 (NumPy 適合處理同質之數值陣列資料)
10.4.4. 視覺化
matplotlib
- Matplotlib 就是 MATLAB+Plot+Library 的簡稱,因為是模仿 MATLAB 建立的繪圖庫,所以繪
圖風格會與 MATLAB 有點類似。14 - 為了提高處理大量資料的性能,Matplotlib 大量使用了 NumPy 和其相關的擴展代碼。 為了方便快速繪圖, Matplotlib 通過 pyplot 模組提供了一套和 MATLAB 類似的繪圖 API,只需要調用 pyplot 模組所提供的函數,就可以實現快速繪圖及設置圖表的各種細節。
- 另一方面 Matplotlib 也適合互動式繪製圖表,可以很方便地處理二維和三維的圖表。
seaborn


ggplot

- R 語言視覺化神器的 Python 版本
- ggplot2 是一個十分強大的 R 語言可視化包。它的核心理念是將繪圖與數據分離,數據相關
的繪圖與數據無關的繪圖分離。1 - 它是按圖層作圖的,一個語句做一個僅包含基礎作圖單元的圖層,然後通過不同圖層的疊
加最後成圖。
plotly

- 這個神器是個 js 庫,不過也有各種流行的語言介面
- plotly 是一個能讓你畫出互動式圖表的一個開源套件,其基本操作是免費的,如果你想要使用網頁的版本,可以使用更多 plotly 的進階功能的話,就必須付費
10.4.5. 機器學習
scikit-learn

- 幾乎所有機器學習演算法都囊括
- scikit-learn,又寫作 sklearn,是一個開源的基於 python 語言的機器學習工具包。它通過 NumPy, SciPy 和 Matplotlib 等 python 數值計算的庫實現高效的算法應用,並且涵蓋了幾乎所有主流機器學習算法。17
- sklearn 中常用的 module 有分類、回歸、聚類、降維、模型選擇、預處理。
NLTK

TensorFlow

- Tensorflow 最初為 Google Brian 所開發。在 2015 時,Google 將之開源,為現今重要的深
度學習框架之一,它支援各式不同的深度學習演算法,並已應用於各大企業服務上,Ex:
Google, Youtube, Airbnb, Paypal … 等。19 - 此外,Tensorflow 也支援在各式不同的
device 上運行深度學習 Ex: Tensorflow Lite 、 Tensorflow.js 等等。 - Tensorflow 為目
前最受歡迎的機器學習、深度學習開源專案。不管是 github fork 的數量、論文的使用次
數以及熱門程度,均比其他的框架來的多20。
深度學習套件
Keras

- 在 2015 年 TensorFlow 推出的同時,美國麻省理工學院(又是它,這學校開門就能賺錢)
也推出一套能很容易被使用者透過 Python 寫 Deep learning 的應用程式介面 API ,叫
做 Keras 。 - Keras 只有介面喔! Keras 本身還是得透過 TensorFlow ,或者其
他像是微軟的 CNTK 這類引擎當作底層,才能執行。21 - Keras 使用上比較接近人類的想法( TensorFlow 設計上沒有錯,只不過比較是針對電腦
系統跟網路通訊的想法),所以透過 Python 呼叫 Keras 能夠很簡單地描述我們人類想
要電腦達到 Deep Learning 要做的事情。目前在教學上, Keras 的普及率相當高 - Keras 可以快速有方便運算的主要原因是,它已經將訓練模型的輸入層、隱藏層、輸出層,做好架構,使用者只需要加入並且填寫正確的參數 ex.神經元個數、activation function 的函式…等。22
PyTorch

- Numpy 的 GPU 版
- PyTorch 為 Facebook 在 2017 年初開源的深度學習框架,其建立在 Torch 之上,且標
榜 Python First ,為量身替 Python 語言所打造,使用起來就跟寫一般 Python 專案沒
兩樣,也能和其他 Python 套件無痛整合。PyTorch 的優勢在於其概念相當直觀且語法簡
潔優雅,因此視為新手入門的一個好選項;再來其輕量架構讓模型得以快速訓練且有效運
用資源。23 - 於 PyTorch 框架中,資料類型定義為張量(Tensor),張量可以是純量、向量或是更高維度的矩陣,而 torch 函式庫負責張量在 CPU/GPU 的運算。
10.5. python 執行環境建立與維護
建立24
conda create -n envName
啟用
conda activate envName
退出
conda deactivate
刪除
conda env remove -n envName
列出目前系統中所有的虛擬環境
conda env list
10.6. 將執行環境匯入 jupyter
- 於終端機(for windows: Anaconda prompt)下建立、啟用所需虛擬環境
- 將環境滙至 jupyter kernel
python -m ipykernel install --user --name 虛擬環境名稱 --display-name "在jupyter中的名稱"
- 啟動 jupyter
10.7. poetry
pip 最主要的缺點在於套件的相依性。pip 在解決套件之間的版本衝突時很容易遇到困難。它不具備先進的依賴解析算法,這可能導致不穩定的環境和不可預知的錯誤。更重要的是,移除套件時,pip 只會移除該套件本身,而不會移除其他相依的套件。也因此發展出針對套件相依性更好的工具,例如 poetry25。
Poetry 是一個現代化的套件管理工具,它不僅可以幫助我們管理套件的依賴,還提供了一個虛擬環境的解決方案。Poetry 使用一個 toml 檔 pyproject.toml 文件來管理專案配置和依賴,這符合 – Specifying Minimum Build System Requirements for Python Projects 所提倡的現代 Python 專案的依賴項管理25。
10.7.1. 安裝
for Python 3.8+
curl -sSL https://install.python-poetry.org | python3 -
10.7.2. 結合虛擬環境與專案
poetry config virtualenvs.in-project true
10.7.3. 建立新專案
假設專案名稱為 tnfshbot
poetry new tnfshbot
cd tnfshbot
poetry init
10.7.4. 修改pyproject.toml
1: [tool.poetry.dependencies] 2: python = "^3.12"
10.7.5. 安裝
當你手動添加了新的套件後(poetry add XXX),使用 poetry install 將會:
- 安裝 pyproject.toml 中列出的所有套件,包括新添加的與其依賴項。
- 如果 poetry.lock 文件存在,它將依照該文件中固定的版本來安裝依賴項。
- 如果 poetry.lock 文件不存在,它將創建一個新的,其中固定了依賴的版本。
1: poetry install
會生成一個.venv資料夾
1: poetry run python --version
10.7.6. 新增tnfshbot/main.py
安裝新套件
1: poetry add pendulum
執行python
1: import pendulum 2: import sys 3: 4: print("Hello World!") 5: print(sys.version) 6: print(pendulum.now())
執行方式為
1: poetry run python tnfshbot/main.py
10.7.7. 整個資料夾架構如下
.
├── README.md
├── poetry.lock
├── pyproject.toml
├── tests
│ └── __init__.py
└── tnfshbot
├── __init__.py
└── main.py
10.7.8. pyproject.toml
精確版本
指定一個精確的版本,意味著只有該特定版本會被接受。例如:
1: [tool.poetry.dependencies] 2: numpy = "1.21.0"
版本範圍
可以使用比較運算符來指定一個版本範圍:
1: [tool.poetry.dependencies] 2: numpy = ">=1.21.0, <2.0.0"
在上面的範例中,任何版本從 1.21.0 (含) 到 2.0.0 (不含) 都是可以接受的。
星字號
使用星號(*)是允許任何兼容的版本:
1: [tool.poetry.dependencies] 2: numpy = "1.21.*"
在上面的範例中,任何 1.21 系列的版本都是可以接受的。如
Caret
使用Caret(^)可以指定一個允許任何相容的版本,但不會改變最左邊的非零數字:
1: [tool.poetry.dependencies] 2: numpy = "^1.21.0"
這將允許 1.21.0 以及任何更高但低於 2.0.0 的版本。
波浪號版本
使用波浪號(~)可以指定一個允許在特定範圍內的版本:
1: [tool.poetry.dependencies] numpy = "~1.21.0"
這會允許 1.21.0 以及任何更高但低於 1.22.0 的版本。
多版本指定
你也可以指定多個版本,並且只要符合其中一個條件就可以:
1: [tool.poetry.dependencies] 2: numpy = [ ">=1.20.0, <1.21.0", ">=1.22.0, <1.23.0" ]
10.7.9. poetry update
在添加新的依賴後使用 poetry update 將會26:
- 更新所有依賴到最新可用版本,並更新 poetry.lock 文件。
- 它會安裝新添加的套件和更新所有其他依賴。
- 這個指令超級強大,更新套件版本時也解析並更新依賴。有更新過 Python 套件的人常常都會受到依賴項衝突所困,用這個指令就能簡單解決了。
- 可以指定要更新什麼套件,例如說 poetry update pendulum
10.7.10. poetry to jupyter kernel
1: poetry run ipython kernel install --name=tnfshbot --user
11. Multiprocessing
11.1. 執行緒 vs. 程序
程序(process)是系統資源分配的最小單位,而一個程序可以有很多個執行緒(thread)。
我們每次開啟一個python檔案,都是在開啟一個新的程序,而每個程序都有自己的記憶體空間,這些記憶體空間是獨立的,互不影響。那為什麼還需要去探討執行緒呢?因為執行緒是程序中最小的執行單位,當我們在一個程序中開啟多個執行緒時,這些執行緒會共享這個程序的記憶體空間,這樣就可以讓我們在同一個程序中同時執行多個任務。
11.2. 非執行緒的程式
為了對照執行緒的程式,我們先來看一個非執行緒的程式,這個程式會依序執行三個函式,並且計算總共花了多少時間來執行這三個函式。
1: from time import sleep, perf_counter 2: 3: def print_hello(): # 此func所需執行時間應為1秒 4: for i in range(10): 5: sleep(0.1) 6: print('Says HELLO!') 7: 8: def print_message(message): # 此func所需執行時間應為1秒 9: for i in range(10): 10: sleep(0.1) 11: print(f'Print {message}!') 12: 13: start = perf_counter() 14: 15: print_hello() 16: print_hello() 17: print_message('FUNCTION 3') 18: 19: end = perf_counter() 20: print(f'Time taken: {end - start:.2f} seconds') 21: print(f'All done!') 22:
Says HELLO! Says HELLO! Says HELLO! Says HELLO! Says HELLO! Says HELLO! Says HELLO! Says HELLO! Says HELLO! Says HELLO! Says HELLO! Says HELLO! Says HELLO! Says HELLO! Says HELLO! Says HELLO! Says HELLO! Says HELLO! Says HELLO! Says HELLO! Print FUNCTION 3! Print FUNCTION 3! Print FUNCTION 3! Print FUNCTION 3! Print FUNCTION 3! Print FUNCTION 3! Print FUNCTION 3! Print FUNCTION 3! Print FUNCTION 3! Print FUNCTION 3! Time taken: 3.11 seconds All done!
11.3. 建立及執行執行緒
threading.Thread 的常用參數:
| 參數 | 說明 |
|---|---|
target |
執行緒要執行的函式(注意:傳的是函式本身,不加 () ) |
args |
傳給 target 的位置引數,要用 tuple(單一引數記得加逗號:=(x,)=) |
kwargs |
傳給 target 的關鍵字引數(dict) |
name |
執行緒名稱,方便 debug 用 |
daemon=True |
主程式結束時自動終止此執行緒 |
建立後呼叫 .start() 啟動執行緒,呼叫 .join() 會讓主程式等待該執行緒跑完才繼續。
1: from threading import current_thread, Thread as Thread 2: from time import sleep, perf_counter 3: 4: def print_hello(): # 此func所需執行時間應為1秒 5: for i in range(10): 6: sleep(0.1) 7: print(f'{current_thread().name} says HELLO!') 8: 9: def print_message(message): # 此func所需執行時間應為1秒 10: for i in range(10): 11: sleep(0.1) 12: print(f'{current_thread().name} says {message}!') 13: 14: start = perf_counter() 15: 16: thread1 = Thread(target=print_hello, name='Thread 1') 17: thread2 = Thread(target=print_hello, name='Thread 2') 18: thread3 = Thread(target=print_message, args=('This is Thread 3',), name='Thread 3') 19: 20: thread1.start() 21: thread2.start() 22: thread3.start() 23: 24: thread1.join() 25: thread2.join() 26: thread3.join() 27: 28: end = perf_counter() 29: print(f'Time taken: {end - start:.2f} seconds') 30: print(f'Current thread: {current_thread().name}') 31: print(f'All done!') 32:
Thread 1 says HELLO! Thread 2 says HELLO! Thread 3 says This is Thread 3! Thread 3 says This is Thread 3! Thread 1 says HELLO! Thread 2 says HELLO! Thread 3 says This is Thread 3! Thread 2 says HELLO! Thread 1 says HELLO! Thread 3 says This is Thread 3! Thread 2 says HELLO! Thread 1 says HELLO! Thread 2 says HELLO! Thread 3 says This is Thread 3! Thread 1 says HELLO! Thread 2 says HELLO! Thread 3 says This is Thread 3! Thread 1 says HELLO! Thread 2 says HELLO! Thread 3 says This is Thread 3! Thread 1 says HELLO! Thread 2 says HELLO! Thread 3 says This is Thread 3! Thread 1 says HELLO! Thread 2 says HELLO! Thread 3 says This is Thread 3! Thread 1 says HELLO! Thread 2 says HELLO! Thread 3 says This is Thread 3! Thread 1 says HELLO! Time taken: 1.05 seconds Current thread: MainThread All done!
上述程式中,我們建立了三個執行緒:
- thread1 和 thread2,這兩個執行緒都會執行 print_hello 函式,
- 第三個執行緒 thread3 則會執行 print_message 函式。
仔細觀察執行輸出,我們可以發現兩項重要的事項:
- 這三個執行緒都是 同時 執行的,所以我們可以看到它們的輸出是交錯在一起的
- 照理說這三個執行緒都需要 1 秒的時間來執行,但實際上卻只花了 1.05 秒,這是因為這三個執行緒是同時執行的,所以它們的執行時間是重疊的。
這就是為什麼我們需要使用執行緒的原因,因為它可以讓我們在同一個程序中同時執行多個任務,這樣就可以提高我們的程式效率。
11.4. 延伸閱讀
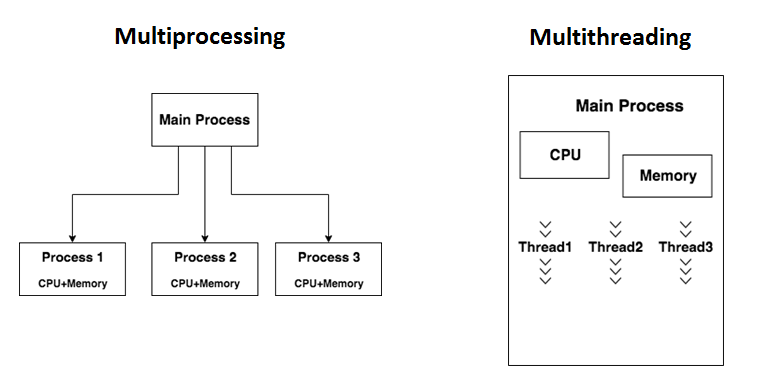
Figure 2: Multiprocessing v.s. Multithreading