Crawler: 網路資料解析與爬蟲
Table of Contents

1. JSON
1.1. 網路資料分析的兩種類型
- 可直接下載的靜態結構化資料,如 CSV、JSON、XML
- 直接分析網站的線上內容(HTML): 爬蟲(Web Crawler)
1.2. JSON
1.2.1. JSON 是什麼?
- JSON(JavaScript Object Notation,JavaScript 物件表示法)是個以純文字來描述資料的簡單結構,在 JSON 中可以透過特定的格式去儲存任何資料(字串,數字,陣列,物件),也可以透過物件或陣列來傳送較複雜的資料。1
- JSON 常用於網站上的資料呈現、傳輸 (例如將資料從伺服器送至用戶端,以利顯示網頁)。
- 一旦建立了 JSON 資料,就可以非常簡單的跟其他程式溝通或交換資料,因為 JSON 就只是純文字格式。
1.2.2. JSON 的優點
- 相容性高
- 格式容易瞭解,閱讀及修改方便
- 支援許多資料格式 (number,string,booleans,nulls,array,associative array)
- 許多程式都支援函式庫讀取或修改 JSON 資料
- NoSQL Database
1.2.3. JSON 結構
- 物件: {}
- 陣列: []
1.2.4. JSON 支援的資料格式
- 字串 (string),要以雙引號括起來:
- {“name”: “Mike”}
- {“name”: “Mike”}
- 數值 (number)
- {“age”: 25}
- {“age”: 25}
- 布林值 (boolean)
- {“pass”: true}
- {“pass”: true}
- 空值 (null)
- {“middlename”: null}
- {“middlename”: null}
- 物件 (object)
- 陣列 (array)
1.2.5. JSON 物件
- 格式
- key 只能是字串,也一定要加上雙引號
1: { 2: "key1": value1, 3: "key2": value2, 4: ...... 5: "keyN": valueN 6: }
- 範例 1
1: { 2: "id": 1, 3: "name": "Jamees, Yen", 4: "age": 19, 5: "gender": "M", 6: "hobby": ["music", "programming"] 7: }
- 範例 2
1: { 2: "id": 382192, 3: "name": "Jamees, Yen", 4: "age": 19, 5: "gender": "M", 6: "exams": [ 7: { "title": "期中考", 8: "chinese": 85, 9: "math": 98, 10: "english": 92 11: }, 12: { "title": "期末考", 13: "chinese": 81, 14: "math": 92, 15: "english": 97 16: } 17: ], 18: "hobby": ["music", "programming"] 19: }
1.2.6. JSON 轉 PANDAS dataFrame
1: import pandas as pd 2: 3: df = pd.json_normalize( list of dict ) 4: print(df.head(3))
1.3. JSON 實作範例
1.3.1. 實作 1: 國際主要國家貨幣每月匯率概況
1.3.1.1. 下載 JSON
1: # -*- coding: utf-8 -*- 2: import requests 3: 4: json_url = 'http://quality.data.gov.tw/dq_download_json.php?nid=31897&md5_url=bf1f3b3e4a09f5c75ec9af665afbf7b3' 5: response = requests.get(json_url) 6: print(response) 7: jsonRes = response.json() 8: print(type(jsonRes)) 9: 10: import json 11: print(jsonRes[:1]) 12: print(json.dumps(jsonRes[:2], indent = 4, ensure_ascii=False))
上面這段程式碼用到了幾個重要的東西,我們先來認識一下:
- requests.get() 常用參數
requests.get()是用來發送 HTTP GET 請求的函式,完整寫法長這樣:
1: requests.get(url, params=None, headers=None, timeout=None, verify=True)
參數 說明 params查詢字串參數(dict),會自動附加到 URL headers自訂 HTTP 標頭(dict),常用來設定 User-Agent timeout等待回應的秒數,避免程式卡住 verifySSL 憑證驗證,設為 False可跳過驗證(不建議,但有時不得已QQ) - response 物件常用屬性
requests.get()回傳的是一個Response物件,常用的屬性如下:
屬性 / 方法 說明 response.status_codeHTTP 狀態碼(200 表示成功) response.text回應內容(字串) response.json()將 JSON 回應解析為 dict/list(等同 json.loads(response.text))response.encoding回應的編碼 實務上,發送請求後建議加上狀態碼檢查,確保請求成功:
1: r = requests.get(url, timeout=10) 2: r.raise_for_status() # 如果狀態碼不是 2xx,會拋出 HTTPError
- json.dumps() 常用參數
json.dumps()可以把 Python 物件轉成 JSON 格式的字串,完整寫法:
1: json.dumps(obj, indent=None, ensure_ascii=True, sort_keys=False)
參數 說明 indent縮排空格數,讓輸出更易讀 ensure_ascii設為 False才能輸出中文(不然會變 =\uXXXX=)sort_keys設為 True會按 key 排序如果你以上述程式碼執行,結果看到如下的錯誤訊息(請略過不重要的中間部分)留意「CERTIFICATE_VERIFY_FAILED]」,表示你的 Python 環境無法驗證該網站的 SSL 憑證….QQ
Traceback (most recent call last): ...... 中間省略...... increment raise MaxRetryError(_pool, url, reason) from reason # type: ignore[arg-type] ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='quality.data.gov.tw', port=443): Max retries exceeded with url: /dq_download_json.php?nid=31897&md5_url=bf1f3b3e4a09f5c75ec9af665afbf7b3 (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: Missing Subject Key Identifier (_ssl.c:1032)'))) During handling of the above exception, another exception occurred: Traceback (most recent call last): File "<stdin>", line 5, in <module> ...... 中間省略...... raise SSLError(e, request=request) requests.exceptions.SSLError: HTTPSConnectionPool(host='quality.data.gov.tw', port=443): Max retries exceeded with url: /dq_download_json.php?nid=31897&md5_url=bf1f3b3e4a09f5c75ec9af665afbf7b3 (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: Missing Subject Key Identifier (_ssl.c:1032)'))) [ Babel evaluation exited with code 1 ]解決方法(注意:=verify=False= 只是暫時方案,正式環境中應該修復憑證問題而非跳過驗證):
1: import requests 2: import urllib3 3: urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) 4: ## 暫時關閉 SSL 驗證(僅供練習使用,不建議用於正式環境) 5: json_url = "https://quality.data.gov.tw/dq_download_json.php?nid=31897&md5_url=bf1f3b3e4a09f5c75ec9af665afbf7b3" 6: 7: r = requests.get(json_url, verify=False, timeout=30) 8: print(r.status_code) 9: 10: jsonRes = r.json() 11: print(type(jsonRes)) 12: print(jsonRes[:1]) #顯示第一筆資料 13: 14: import json 15: print(json.dumps(jsonRes[:2], indent=4, ensure_ascii=False)) #顯示前兩筆資料 16:
200 <class 'list'> [{'月別': '2024-03', '新台幣(匯率)': '31.990', '人民幣(匯率)': '7.2232', '日圓(匯率)': '151.34', '韓元(匯率)': '1347.2', '新加坡元(匯率)': '1.3494', '歐元(匯率)': '1.0769', '英鎊(匯率)': '1.2619', '澳幣(匯率)': '0.6509'}] [ { "月別": "2024-03", "新台幣(匯率)": "31.990", "人民幣(匯率)": "7.2232", "日圓(匯率)": "151.34", "韓元(匯率)": "1347.2", "新加坡元(匯率)": "1.3494", "歐元(匯率)": "1.0769", "英鎊(匯率)": "1.2619", "澳幣(匯率)": "0.6509" }, { "月別": "2024-04", "新台幣(匯率)": "32.542", "人民幣(匯率)": "7.2416", "日圓(匯率)": "156.86", "韓元(匯率)": "1382.0", "新加坡元(匯率)": "1.3614", "歐元(匯率)": "1.0705", "英鎊(匯率)": "1.2542", "澳幣(匯率)": "0.6528" } ]由以上輸出可知,這是一個包含多筆資料的 JSON 陣列,而每筆資料都是一個包含多個鍵值對的 JSON 物件。每個物件代表某個月份的匯率資訊,包括新台幣、人民幣、日圓、韓元、新加坡元、歐元、英鎊和澳幣的匯率。
那,我們來看看如何從這些資料中提取出我們需要的資訊,例如「日期」和「美元/新台幣」的匯率。
1.3.1.2. 輸出日期與匯率
我們可以使用一個簡單的迴圈來遍歷 JSON 陣列,並從每個物件中提取出「月別」和「新台幣(匯率)」這兩個欄位,然後將它們格式化輸出。
1: print('日 期', "\t", '美元/新台幣') 2: print('=======', "\t", '===========') 3: for item in jsonRes[:10]: 4: print(item['月別'], "\t", item['新台幣(匯率)'])
日 期 美元/新台幣 ======= =========== 2024-03 31.990 2024-04 32.542 2024-05 32.420 2024-06 32.450 2024-07 32.836 2024-08 31.940 2024-09 31.651 2024-10 32.031 2024-11 32.457 2024-12 32.781
1.3.1.3. 製圖
有了日期和匯率的資料後,我們可以使用 Matplotlib 來繪製折線圖,展示美元/新台幣匯率的走勢。
1: import matplotlib.pyplot as plt 2: 3: plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] 4: plt.rcParams['axes.unicode_minus'] = False 5: 6: # 提取日期和美元/新台幣的數據 7: dates = [item['月別'] for item in jsonRes] 8: # 上面是一段精簡的寫法,等同於下面的寫法 9: # dates = [] 10: # for item in jsonRes: 11: # dates.append(item['月別']) 12: # 意思就是把每一筆資料的「月別」欄位取出來,放到一個新的列表(dates)中 13: exchange_rates = [float(item['新台幣(匯率)']) for item in jsonRes] 14: # 這裡也一樣,請自行領悟 15: 16: # 繪製折線圖 17: plt.figure(figsize=(10, 6)) 18: plt.plot(dates, exchange_rates, marker='o', linestyle='-') 19: 20: # 設置圖形標籤和標題 21: plt.xlabel('日期') 22: plt.ylabel('美元/新台幣') 23: plt.title('美元/新台幣匯率走勢') 24: 25: # 旋轉x軸上的日期標籤,以避免重疊 26: plt.xticks(rotation=45, ha='right') 27: 28: # 顯示圖形 29: plt.tight_layout() 30: plt.savefig('images/json-plot.png', dpi=300)
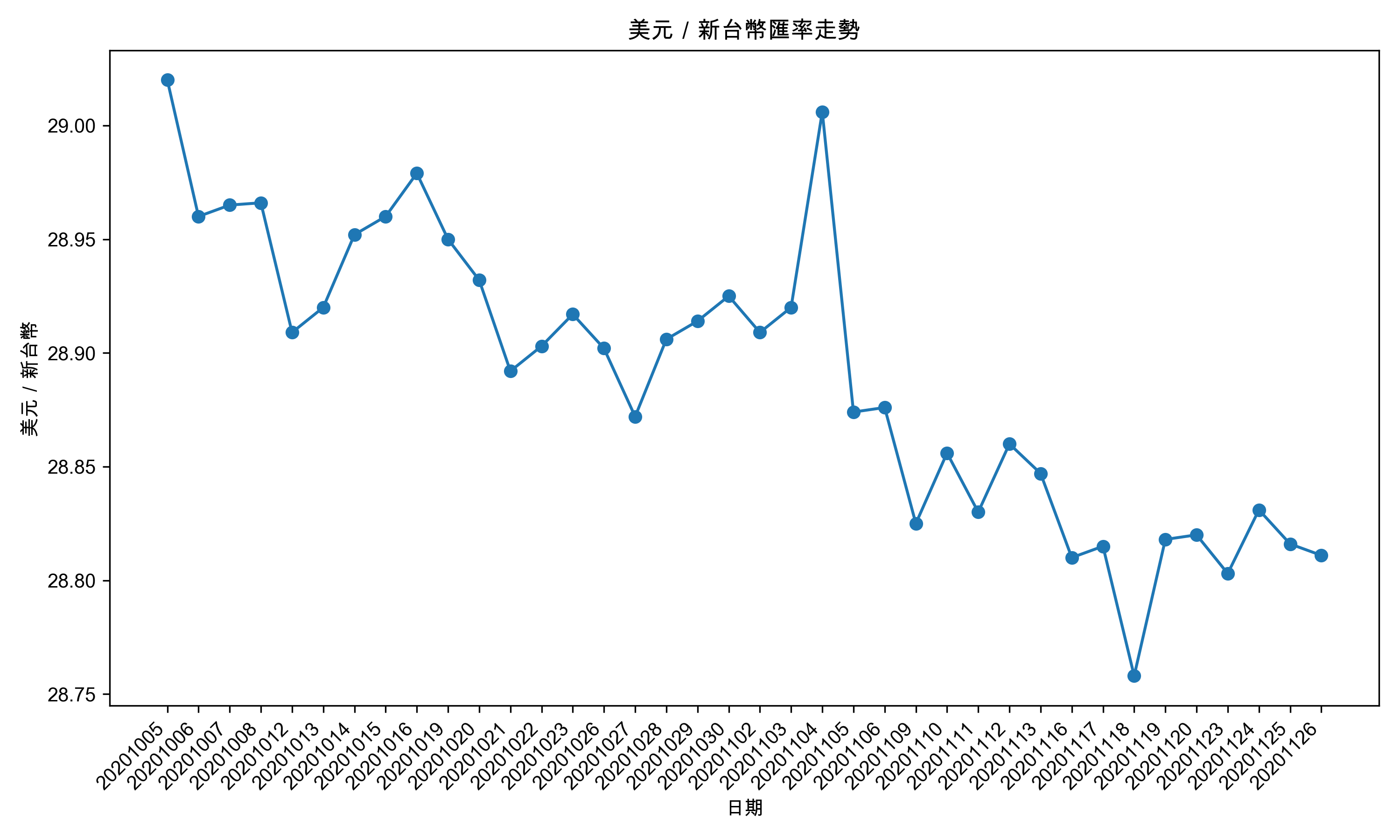
Figure 1: 美元/新台幣匯率走勢
現在,你應該已經具備了從網路上下載 JSON 資料、解析資料、提取所需資訊,並使用 Matplotlib 繪製圖表的基本能力。接下來,你可以嘗試應用這些技巧來分析其他類型的 JSON 資料,並創建更多有趣的視覺化圖表!
1.3.2. 實作 2: 澎湖生活博物館每月參觀人次統計資料
1: import requests 2: import matplotlib.pyplot as plt 3: from datetime import datetime 4: 5: # 解決中文問題 6: plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] 7: plt.rcParams['axes.unicode_minus'] = False 8: 9: json_url = 'http://opendataap2.penghu.gov.tw/resource/files/2020-01-12/eaa641fc3af66277e60b13201ca11232.json' 10: 11: response = requests.get(json_url) 12: jsonRes = response.json() 13: 14: year = [str(int(i['年度'])+1911) for i in jsonRes] 15: month = [i['月份'] for i in jsonRes] 16: visitor = [int(i['人數']) for i in jsonRes] 17: 18: dates = [x+'/'+y for x, y in zip(year, month)] 19: dates = [datetime.strptime(x, '%Y/%m').date() for x in dates] 20: 21: plt.clf() 22: plt.barh(dates, visitor, height=0.5) 23: plt.xticks(rotation=0, fontsize=10) 24: plt.yticks(rotation=0, fontsize=10) 25: plt.xlabel('人數') 26: plt.ylabel('日期') 27: plt.title('澎湖生活博物館每月參觀人次') 28: plt.savefig('images/jsonBar.png', dpi=300, bbox_inches='tight')
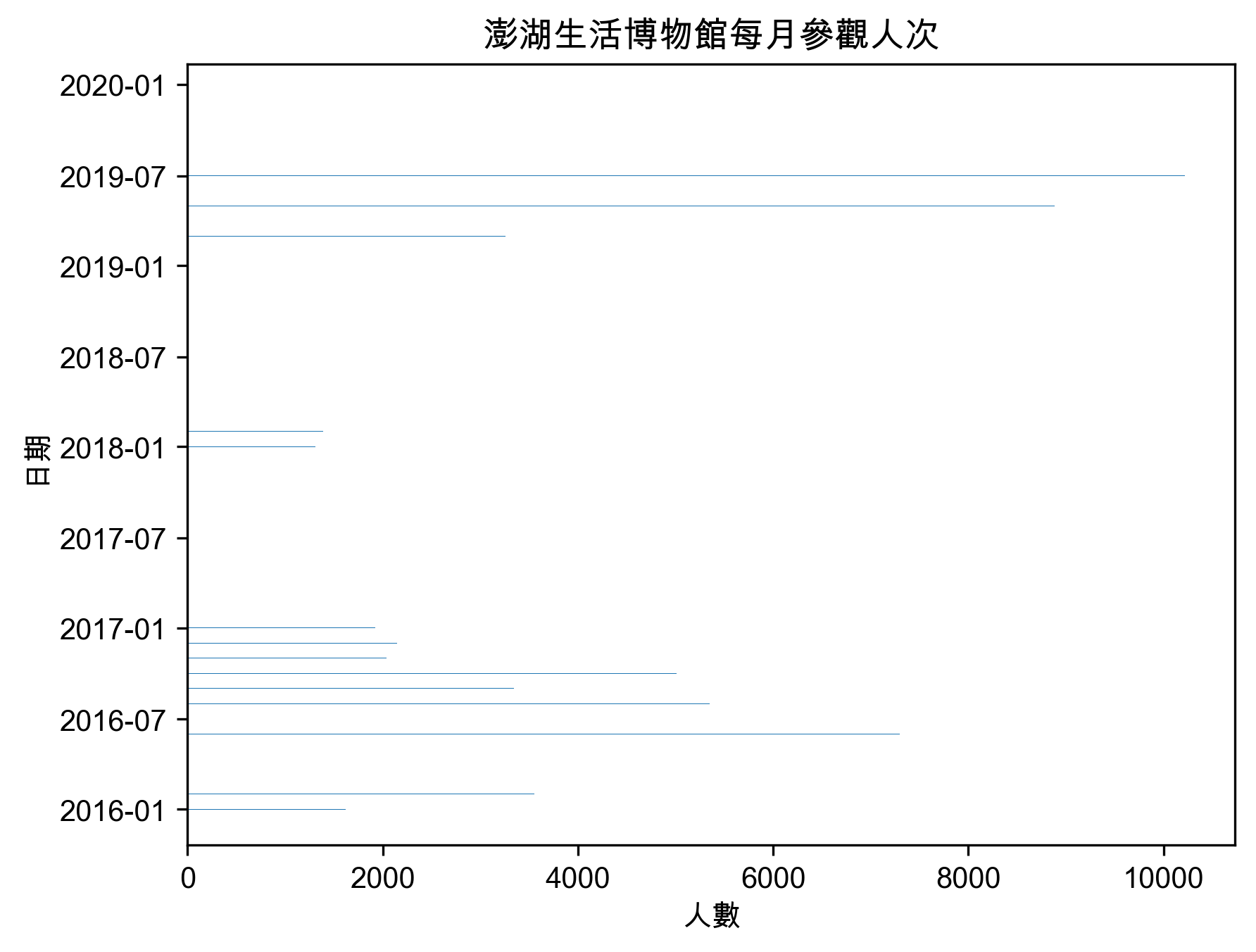
Figure 2: 參觀人數
1.4. [課堂練習]線上 JSON 讀取 TNFSH
- [注意]如果 JSON 的資料下載發生錯誤,可以試著將 URL 由’https://’改為’http://’
請上網查詢台南市各區 WIFI 熱點數量,依行政區統計,繪製類似以下圖形,儘可能加上統計圖表所需元素並加以美化
Figure 3: 台南市各區熱點分佈
1.5. JSON 進階閱讀
1.6. [課堂練習]社團 JSON 資料處理 TNFSH
以下是某校社團的 JSON 資料,請使用 Python 的 json 模組完成以下任務:
- 列出所有社團名稱與人數
- 找出人數最多的社團
- 按類別(學術/音樂/體育/休閒)統計社團數量
- 找出 2019 年之後成立的社團
1: import json 2: 3: club_data = ''' 4: { 5: "school": "台南一中", 6: "clubs": [ 7: {"name": "程式設計社", "members": 25, "category": "學術", "year": 2020}, 8: {"name": "吉他社", "members": 40, "category": "音樂", "year": 2015}, 9: {"name": "籃球社", "members": 30, "category": "體育", "year": 2018}, 10: {"name": "動漫社", "members": 35, "category": "休閒", "year": 2019}, 11: {"name": "管樂社", "members": 45, "category": "音樂", "year": 2010}, 12: {"name": "桌遊社", "members": 20, "category": "休閒", "year": 2021}, 13: {"name": "排球社", "members": 28, "category": "體育", "year": 2016}, 14: {"name": "英語辯論社", "members": 15, "category": "學術", "year": 2017} 15: ] 16: } 17: ''' 18: data = json.loads(club_data)
結果範例
=== 台南一中社團資訊 === 社團總數: 8 個 1. 各社團人數: 程式設計社: 25 人 吉他社: 40 人 籃球社: 30 人 動漫社: 35 人 管樂社: 45 人 桌遊社: 20 人 排球社: 28 人 英語辯論社: 15 人 2. 人數最多的社團: 管樂社 (45 人) 3. 各類別社團數: 學術: 2 個 音樂: 2 個 體育: 2 個 休閒: 2 個 4. 2019年之後成立的社團: 程式設計社 (2020年成立) 動漫社 (2019年成立) 桌遊社 (2021年成立)
2. HTML
2.1. HTML 是什麼
- 政府資料開放平台
- 超文本標記語言(HyperText Markup Language)是一種用於建立網頁的標準標記語言。HTML 是一種基礎技術,常與 CSS、JavaScript 一起被眾多網站用於設計網頁、網頁應用程式以及行動應用程式的使用者介面。2
- HTML 元素是構建網站的基石。HTML 允許嵌入圖像與物件,並且可以用於建立互動式表單,它被用來結構化資訊——例如標題、段落和列表等等,也可用來在一定程度上描述文件的外觀和語意。2
- HTML 的語言形式為<>包圍的 HTML 元素(如<html>),瀏覽器使用 HTML 標籤和指
令碼來詮釋網頁內容,但不會將它們顯示在頁面上。 2 - 網頁就是由各式標籤 (tag) 所組成的階層式文件,例如:
- <title>我是網頁標題</title>
- <h1 class=“large”>我是變色且置中的抬頭</h1>
- <p id=“p1”>我是段落一</p>
- <title>我是網頁標題</title>
2.2. HTML 範例
2.2.1. HTML 程式碼
1: <html> 2: <head> 3: <title>我是網頁標題</title> 4: <style> 5: .large { 6: color:blue; 7: text-align: center; 8: } 9: </style> 10: </head> 11: <body> 12: <h1 class="large">我是變色且置中的抬頭</h1> 13: <p id="p1">我是段落一</p> 14: <p id="p2" style="">我是段落二</p> 15: <div><a href='http://blog.castman.net' style="font-size:200%;">我是放大的超連結</a></div> 16: </body> 17: </html>
2.2.1.1. 執行結果
2.2.2. HTML tree
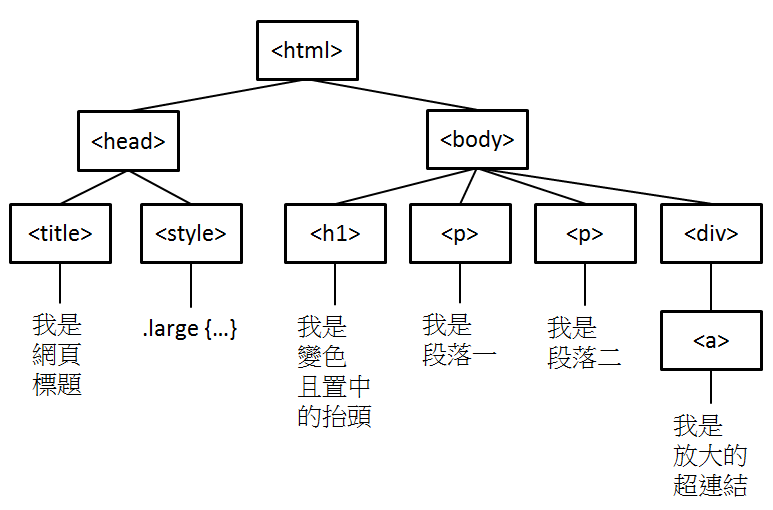
Figure 4: HTML tree
- HTML 文件內不同的標籤 (例如 <title>, <h1>, <p>, <a>, <div>)
- 不同的標籤有著不同的語義,表示建構網頁用的不同元件,且標籤可以有各種屬性 (例如 id, class, style 等通用屬性, 或 href 等專屬屬性),
- <div>是 division 這個單字取前面三個字母來表示,division 是區分的意思,div 標籤主要的功能就是在形成一個個的區塊,方便網頁排版美化3。例如:
1: <div style="background-color:grey;"> 2: <p>今天是第7天的介紹,div範例程式</p> 3: <p>今天是第7天的介紹,div範例程式</p> 4: </div>
其結果為:
今天是第7天的介紹,div範例程式
今天是第7天的介紹,div範例程式
- 我們可以用標籤 + 屬性去定位資料所在的區塊並取得資料。4
3. 網路爬蟲
上述的 html 程式碼只能透過瀏覽器來解析並呈現結果,如果我們想跳過瀏覽器,直接以程式來抓取網頁上的資訊,就要透過爬蟲程式。
3.1. 先說我們最後到底想完成什麼
目標: 讓 Python 自己去抓取批踢踢 Japan_Travel 看板中所有文章的標題,並列出來。
目前的這個網頁長的像這樣:

Figure 5: 2025-12-19的Japan_Travel看板
我們想要的結果是像這樣:
第1則貼文::Fw: [食記] 喜一 福島喜多方 鮮味軟嫩叉燒喜多方拉麵 第2則貼文::[資訊] JCB日本消費滿10萬回饋1萬 第3則貼文::[遊記] 三保松原、富士山五湖、昇仙峽(前篇) 第4則貼文::[資訊] JR四國松山-宇和島指定日期部分路段停駛 第5則貼文::Re: [新聞] 獨/基隆-石垣島渡輪「延至10月開航 ...(以下省略)
現在,我們就一步一步來完成這個目標吧!首先我們需要觀察 HTML 程式碼,發現每一篇文章的標題都在 <div class“title”>= 這個 tag 裡面。要從 HTML 字串中精準地取出這些標籤內容,就需要用到 BeautifulSoup 這個工具。但在此之前,我們先來學習如何用程式取得網頁的 HTML 原始碼。
3.2. 爬蟲精神:將程式模仿成一般 user
3.2.1. 原則
- 要抓網路資料,就要先仔細觀察網頁內容
- 要儘量欺騙網站自己是 browser
3.2.2. 實作範例: 取得 HTML 資料
3.2.2.1. 第一版: 以 urllib 模組來抓取 HTML 資料
urllib.request 是一個用來從 URLs (Uniform Resource Locators)取得資料的 Python 模組。它提供了一個非常簡單的介面能接受多種不同的協議(protocol, 如 http, ftp), urlopen 函數。
1: # 抓取PTT電影版header 2: import urllib.request as req 3: url = "https://www.ptt.cc/bbs/Movie/index.html" 4: 5: with req.urlopen(url) as response: 6: data = response.read().decode("utf-8") 7: print(data)
結果得到如下錯誤訊息:
1: urllib.error.HTTPError: HTTP Error 403: Forbidden
被拒絕原因:這隻程式的行為不像一般使用者,被網站伺服器拒絕。403 Forbidden 是 HTTP 協議中的一個 HTTP 狀態碼(Status Code)。可以簡單的理解為沒有權限訪問此站,服務器收到請求但拒絕提供服務5。
3.2.2.2. 第二版:加入 headers(純文字)
1: import urllib.request as req 2: url = "https://www.ptt.cc/bbs/Movie/index.html" 3: # 幫request加上一個header 4: request = req.Request(url, headers = { 5: "User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:72.0) Gecko/20100101 Firefox/72.0" 6: }) 7: 8: with req.urlopen(request) as response: 9: data = response.read().decode("utf-8") 10: print('所取得的資料型態:',type(data)) 11: print('===得到的部份HTML內容===\n', data[2651:3500])
所取得的資料型態: <class 'str'> ===得到的部份HTML內容=== </div> <div class="date">12/19</div> <div class="mark"></div> </div> </div> <div class="r-ent"> <div class="nrec"><span class="hl f2">3</span></div> <div class="title"> <a href="/bbs/movie/M.1766116859.A.6F8.html">[問片] 某部非常久遠的二戰片 (有雷)</a> </div> <div class="meta"> <div class="author">Maserati</div> <div class="article-menu"> <div class="trigger">⋯</div> <div class="dropdown"> <div class="item"><a href="/bbs/movie/search?q=thread%3A%5B%E5%95%8F%E7%89%87%5D+%E6%9F%90%E9%83%A8%E9%9D%9E%E5%B8%B8%E4%B9%85%E9%81%A0%E7%9A%84%E4%BA%8C%E6%88%B0%E7%89%87+%28%E6%9C%89%E9%9B%B7%29">搜尋同標題文章</a></div> <div class="item"><a href="/bbs/movie/search?q=author%3AMaserati">搜尋看板內 Maserati 的文章</a></div> </div>
可以發現抓取下來的結果都是字串型態,不太容易進一步擷取所需資訊。例如,當我們想抓取所有看板中的標題,只使用字串所提供的一些函式就很難完成工作。
3.3. BeautifulSoup
BeautifulSoup 是一個可以從 HTML 或 XML 檔案中擷取資料的 Python 套件。它可以自動將不完整或格式錯誤的標記修正,並以 Python 物件的形式呈現文件結構,讓使用者能夠輕鬆地導航、搜尋和修改文件內容。
建立 BeautifulSoup 物件的基本語法:
1: soup = BeautifulSoup(markup, parser)
其中 parser 是用來解析 HTML 的解析器,常用的有:
| 解析器 | 說明 |
|---|---|
'html.parser' |
Python 內建,不需額外安裝,夠用了 |
'lxml' |
速度快,需 pip install lxml |
'html5lib' |
最寬容,能處理嚴重損壞的 HTML,需另外安裝 |
一般來說用 html.parser 就可以了,除非你遇到什麼奇怪的網頁解析不了再考慮換別的。
3.3.1. 實作:解析 HTML 資料內容
3.3.1.1. 安裝解析 HTML 所需套件(安裝套件名稱後面有 4)
如果尚未安裝 BeautifulSoup4,可以使用 pip 來安裝,在PyCharm裡你可以打開 Terminal 視窗,輸入以下指令安裝
1: pip install beautifulsoup4
如果你是使用Colab,可以在程式碼區塊輸入以下指令安裝
1: !pip install beautifulsoup4
3.3.1.2. 第三版: 以 BS4 解析 HTML
1: import urllib.request as req 2: url = "https://www.ptt.cc/bbs/Japan_Travel/index.html" 3: # 幫request加上一個header 4: request = req.Request(url, headers = { 5: "User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:72.0) Gecko/20100101 Firefox/72.0" 6: }) 7: 8: with req.urlopen(request) as response: 9: data = response.read() 10: 11: import bs4 12: doc = bs4.BeautifulSoup(data,"html.parser") 13: print(type(doc)) 14: print(doc.prettify()[:4000]) 15:
<class 'bs4.BeautifulSoup'>
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8"/>
<meta content="width=device-width, initial-scale=1" name="viewport"/>
<title>
看板 Japan_Travel 文章列表 - 批踢踢實業坊
</title>
<link href="//images.ptt.cc/bbs/v2.27/bbs-common.css" rel="stylesheet" type="text/css"/>
<link href="//images.ptt.cc/bbs/v2.27/bbs-base.css" media="screen" rel="stylesheet" type="text/css"/>
<link href="//images.ptt.cc/bbs/v2.27/bbs-custom.css" rel="stylesheet" type="text/css"/>
<link href="//images.ptt.cc/bbs/v2.27/pushstream.css" media="screen" rel="stylesheet" type="text/css"/>
<link href="//images.ptt.cc/bbs/v2.27/bbs-print.css" media="print" rel="stylesheet" type="text/css"/>
</head>
<body>
<div id="topbar-container">
<div class="bbs-content" id="topbar">
<a href="/bbs/" id="logo">
批踢踢實業坊
</a>
<span>
›
</span>
<a class="board" href="/bbs/Japan_Travel/index.html">
<span class="board-label">
看板
</span>
Japan_Travel
</a>
<a class="right small" href="/about.html">
關於我們
</a>
<a class="right small" href="/contact.html">
聯絡資訊
</a>
</div>
</div>
<div id="main-container">
<div id="action-bar-container">
<div class="action-bar">
<div class="btn-group btn-group-dir">
<a class="btn selected" href="/bbs/Japan_Travel/index.html">
看板
</a>
<a class="btn" href="/man/Japan_Travel/index.html">
精華區
</a>
</div>
<div class="btn-group btn-group-paging">
<a class="btn wide" href="/bbs/Japan_Travel/index1.html">
最舊
</a>
<a class="btn wide" href="/bbs/Japan_Travel/index8564.html">
‹ 上頁
</a>
<a class="btn wide disabled">
下頁 ›
</a>
<a class="btn wide" href="/bbs/Japan_Travel/index.html">
最新
</a>
</div>
</div>
</div>
<div class="r-list-container action-bar-margin bbs-screen">
<div class="search-bar">
<form action="search" id="search-bar" type="get">
<input class="query" name="q" placeholder="搜尋文章⋯" type="text" value=""/>
</form>
</div>
<div class="r-ent">
<div class="nrec">
</div>
<div class="title">
<a href="/bbs/Japan_Travel/M.1766056069.A.809.html">
Fw: [食記] 喜一 福島喜多方 鮮味軟嫩叉燒喜多方拉麵
</a>
</div>
<div class="meta">
<div class="author">
Geiwoyujie
</div>
<div class="article-menu">
<div class="trigger">
⋯
</div>
<div class="dropdown">
<div class="item">
<a href="/bbs/Japan_Travel/search?q=thread%3A%5B%E9%A3%9F%E8%A8%98%5D+%E5%96%9C%E4%B8%80+%E7%A6%8F%E5%B3%B6%E5%96%9C%E5%A4%9A%E6%96%B9+%E9%AE%AE%E5%91%B3%E8%BB%9F%E5%AB%A9%E5%8F%89%E7%87%92%E5%96%9C%E5%A4%9A%E6%96%B9%E6%8B%89%E9%BA%B5">
搜尋同標題文章
</a>
</div>
<div class="item">
<a href="/bbs/Japan_Travel/search?q=author%3AGeiwoyujie">
搜尋看板內 Geiwoyujie 的文章
</a>
</div>
</div>
</div>
<div class="date">
12/18
</div>
<div class="mark">
</div>
</div>
</div>
<div class="r-ent">
<div class="nrec">
<span class="hl f3">
63
</span>
</div>
<div class="title">
<a href="/bbs/Japan_Travel/M.1766058399.A.C20.html">
[資訊] JCB日本消費滿10萬回饋1萬
</a>
</div>
<div class="meta">
<div class="author">
medama
</div>
<div class="article-menu">
<div class="trigger">
⋯
</div>
<div class="dropdown">
<div class="item">
<a href="/bbs/Japan_Travel/search?q=thread%3A%5B%E8%B3%87%E8%A8%8A%5D+JCB%E6%97%A5%E6%9C%AC%E6%B6%88%E8%B2%BB%E6%BB%BF10%E8%90%AC%E5%9B%9E%E9%A5%8B1%E8%90%AC">
搜尋同標題文章
</a>
</div>
<div class="item">
<a href="/bbs/Japan_Travel/search?q=author%3Amedama">
搜尋看板內 medama 的文章
</a>
</div>
</div>
</div>
<div class="date">
看到這裡,我們成功地將 HTML 解析成 BeautifulSoup 物件,接下來我們就可以利用 BeautifulSoup 所提供的方法來擷取我們想要的資料了。
3.4. BeautifulSoup 的方法6
當我們把原本亂七八糟的 HTML 程式從「字串」解析成 「BeautifulSoup 物件」後,接下來就可以利用 BeautifulSoup 所提供的方法來擷取我們想要的資料了。以下是常用的方法說明:
| 方法 | 說明 |
|---|---|
| select() | 以 CSS 選擇器的方式尋找指定的 tag。 |
| find_all() | 以所在的 tag 位置,尋找內容裡所有指定的 tag。 |
| find() | 以所在的 tag 位置,尋找第一個找到的 tag。 |
| find_parents() | 以所在的 tag 位置,尋找父層所有指定的 tag 或第一個找到的 tag。 |
| find_parent() | |
| find_next_siblings() | 以所在的 tag 位置,尋找同一層後方所有指定的 tag 或第一個找到的 tag。 |
| find_next_sibling() | |
| find_previous_siblings() | 以所在的 tag 位置,尋找同一層前方所有指定的 tag 或第一個找到的 tag。 |
| find_previous_sibling() | |
| find_all_next() | 以所在的 tag 位置,尋找後方內容裡所有指定的 tag 或第一個找到的 tag。 |
| find_next() | |
| find_all_previous() | 所在的 tag 位置,尋找前方內容裡所有指定的 tag 或第一個找到的 tag。 |
| find_previous() |
看起來有點複雜,其實一點也不簡單。
啊不是,我是要說,沒關係,在這裡我只打算介紹其中兩個最常用的方法:find()、find_all(),其他方法就留給有興趣的同學自行研究囉!
先看一下這兩個方法的完整參數:
1: soup.find(name, attrs, string, **kwargs) # 回傳第一個符合的 Tag 2: soup.find_all(name, attrs, string, limit, **kwargs) # 回傳所有符合的 Tag(list)
| 參數 | 說明 |
|---|---|
name |
標籤名稱,如 'div', 'a' |
attrs |
屬性 dict,如 attrs={'class': 'title'} |
string |
搜尋標籤內的文字 |
limit |
(僅 find_all )限制回傳的最大數量 |
有個方便的簡寫:可以直接用 class_ 當參數名稱來篩選 class(因為 class 是 Python 保留字,所以要加底線),例如:
1: # 以下兩種寫法效果一樣 2: soup.find('a', class_='link') 3: soup.find('a', attrs={'class': 'link'})
4. BS4:開始爬
在前面的「第三版」中,我們已經用 bs4.BeautifulSoup() 把下載的 HTML 字串解析成 BS4 物件 =doc=:
doc = bs4.BeautifulSoup(data,"html.parser")
接下來的目標很明確:*從 doc 中把每一篇文章的標題文字抓出來*。
4.1. Step 1:觀察目標在 HTML 中的位置
回頭看看第三版輸出的 HTML,可以發現每篇文章都包在一個 <div class“r-ent”>= 裡面,而我們要的標題就藏在裡面的 <div class“title”>= 中:
1: <div class="r-ent"> 2: <div class="nrec"><span class="hl f2">9</span></div> 3: <div class="title"> 4: <a href="/bbs/Japan_Travel/M.xxxxx.html">[問題] 京都住宿請益</a> 5: </div> 6: <div class="meta"> 7: <div class="author">poi9430</div> 8: <div class="date"> 3/06</div> 9: </div> 10: </div>
所以策略很簡單:找到 <div class“title”>=,再從裡面的 <a> 取出文字就好。
4.2. Step 2:用 find() 找出「一個」標題
BS4 的 find() 會回傳第一個符合條件的 tag。我們用它來找第一個 class 為 "title" 的 =<div>=:
1: first_title = doc.find("div", class_="title") 2: print(first_title)
<div class="title"> <a href="/bbs/Japan_Travel/M.1709715202.A.9ED.html">[問題] 京都住宿請益</a> </div>
找到了!但我們要的是裡面的純文字,不是整坨 HTML。
4.3. Step 3:從 tag 中取出文字和屬性
找到的 <div> 裡面還有一個 <a> tag,我們可以用 .a 取得它,再用 .text 取出純文字:
1: print(first_title.a) # 取出 <a> tag 2: print(first_title.a.text) # 取出 <a> 裡的純文字 3: print(first_title.a['href']) # 取出 <a> 的 href 屬性
<a href="/bbs/Japan_Travel/M.1709715202.A.9ED.html">[問題] 京都住宿請益</a> [問題] 京都住宿請益 /bbs/Japan_Travel/M.1709715202.A.9ED.html
成功拿到一篇文章的標題了!接下來,怎麼一次拿全部的?
4.4. Step 4:用 find_all() 找出「所有」標題
find_all() 的用法和 find() 一模一樣,差別只在於它會回傳一個 *list*,包含所有符合條件的 tag:
1: all_titles = doc.find_all("div", class_="title") 2: print(f"共找到 {len(all_titles)} 個標題") 3: 4: for t in all_titles: 5: print(t.a.text)
共找到 10 個標題 [問題] 京都住宿請益 [問題] 沖繩親子遊首衝安排請益 Re: [問題] 請問最近札幌帝王蟹價格? [問題] IT216飛羽田的疑問 [問題] 小豆島高松-土庄3/10-24航班時間變更 [住宿] 佐賀太良町・有明海旁美食海鮮滿滿平浜荘 [資訊] 台灣虎航 tigerclub會員限定優惠活動 Traceback (most recent call last): File "<string>", line 5, in <module> AttributeError: ‘NoneType’ object has no attribute ‘text’
出錯了!因為有些文章已經被刪除,該 <div class“title”>= 裡面沒有 <a> tag,所以 t.a 會是 None=,呼叫 =.text 就爆炸了。
4.5. Step 5:用 try/except 處理被刪除的文章
我們可以用 try...except 來跳過這些被刪除的文章:
1: all_titles = doc.find_all("div", class_="title") 2: for t in all_titles: 3: try: 4: print(t.a.text) 5: except AttributeError: 6: pass # 已被刪除的文章沒有 <a> 標籤,跳過
[問題] 京都住宿請益 [問題] 沖繩親子遊首衝安排請益 Re: [問題] 請問最近札幌帝王蟹價格? [問題] IT216飛羽田的疑問 [問題] 小豆島高松-土庄3/10-24航班時間變更 [住宿] 佐賀太良町・有明海旁美食海鮮滿滿平浜荘 [資訊] 台灣虎航 tigerclub會員限定優惠活動 [公告] 日本旅遊板板規 112.09.17 [公告] 113.03 實況回報 (含天氣/物候/穿著詢問)
到這裡,我們已經掌握了用 BS4 爬取網頁資料的核心技巧。接下來把上面學到的所有步驟整合成一支完整的程式。
4.6. 補充:find() 的其他搜尋方式
上面我們只用了 find("div", class_“title”)= 這種最常見的寫法,其實 find() 還支援其他搜尋方式,整理如下供日後參考:
4.6.1. 用 tag 名稱搜尋
1: # 找第一個 <a> tag(等同 doc.a) 2: print(doc.find(‘a’))
<a href="/bbs/" id="logo">批踢踢實業坊</a>
4.6.2. 用 id 搜尋
1: print(doc.find(id=’topbar’))
<div class="bbs-content" id="topbar"> <a href="/bbs/" id="logo">批踢踢實業坊</a> <span>›</span> <a class="board" href="/bbs/Japan_Travel/index.html"><span class="board-label">看板 </span>Japan_Travel</a> <a class="right small" href="/about.html">關於我們</a> <a class="right small" href="/contact.html">聯絡資訊</a> </div>
4.6.3. dot notation(點記法)
BS4 也支援直接用 doc.標籤名稱 來取得第一個符合的 tag,但彈性較低,只能抓到第一個:
1: print(doc.title.text) # 取得網頁標題 2: print(doc.div.a.text) # 取得第一個 div 裡的第一個 a 的文字 3: print(doc.div.a[‘href’]) # 取得該 a 的 href 屬性
看板 Japan_Travel 文章列表 - 批踢踢實業坊 批踢踢實業坊 /bbs/
4.7. 第四版:擷取所有主題
1: import urllib.request as req 2: url = "https://www.ptt.cc/bbs/Japan_Travel/index.html" 3: # 幫request加上一個header 4: request = req.Request(url, headers = { 5: "User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:72.0) Gecko/20100101 Firefox/72.0" 6: }) 7: 8: with req.urlopen(request) as response: 9: data = response.read().decode("utf-8") 10: 11: import bs4 12: doc = bs4.BeautifulSoup(data,"html.parser") 13: 14: # 直接找到所有class為title的div 15: titles = doc.find_all("div", class_="title") 16: no = 1 17: for i in titles: 18: try: 19: t = i.a 20: print(f'第{no}則貼文::{t.text}') 21: no += 1 22: except AttributeError: 23: pass # 已被刪除的文章沒有 <a> 標籤,跳過
第1則貼文::Fw: [食記] 喜一 福島喜多方 鮮味軟嫩叉燒喜多方拉麵 第2則貼文::[資訊] JCB日本消費滿10萬回饋1萬 第3則貼文::[遊記] 三保松原、富士山五湖、昇仙峽(前篇) 第4則貼文::[資訊] JR四國松山-宇和島指定日期部分路段停駛 第5則貼文::Re: [新聞] 獨/基隆-石垣島渡輪「延至10月開航 第6則貼文::[遊記] 宮崎五天四夜(非自駕獨旅)-2 第7則貼文::Re: [問題] 請教熊本熊港八代交通 第8則貼文::[資訊] 20251219匯率 第9則貼文::[問題] skyliner 成田往日暮里有需要提前買票嗎 第10則貼文::[問題] 御朱印帳的尺寸 第11則貼文::[資訊] 台灣虎航 26夏增班開賣 第12則貼文::[資訊] 長榮航空台北=青森航線增班 第13則貼文::[遊記] SL磐越物語與只見線攝影紀行 第14則貼文::[公告] 日本旅遊板板規 114.02.02 第15則貼文::Fw: [公告] 請避免與登入1次之帳號進行交易 第16則貼文::Fw: [公告] 違反菸害防制法本站將依使用者條款處分 第17則貼文::[公告] 114.12 實況回報 (含天氣/物候/穿著詢問)
4.8. [課堂練習]爬蟲實作 TNFSH
Google 美食達人「壽司羊」,以爬蟲程式列出其網站最近五篇文章的標題以及文章發表日期。
2024.03.10 / 台北美食【SEASON Artisan Pâtissier 敦南旗艦店】超好吃的法式草莓千層酥/精緻歐式早午餐 黃教練/大安區甜點店/下午茶/SEASON Cuisine Pâtissiartism((附菜單 2024.03.07 / 高雄美食【津筵燒肉酒館】一個人的深夜,也可以好好享受的平價燒肉/好吃又不貴的日式燒肉/美麗島捷運站/高 CP 值((附菜單 2024.03.06 / 高雄美食【光井咖啡 Wellight Coffee】岡山國小後面/簡約風的咖啡外帶小店/肯亞 Tegu 處理廠 AA 水洗((附菜單 2024.03.03 / 台北美食【NOBUO】絕美的羊里肌 羊五花 小羊胸腺/一點都不遜於肉類主餐的鹽漬風乾鰆魚/溫暖又好喝的香菇茶湯((附菜單 2024.03.02 / 台北食記【ä couple coffee】小巷弄裏頭的三角窗咖啡小店/楓糖核桃司康/限量的肉桂捲/美式咖啡/聽說商業午餐不錯吃((附菜單