Advance C/C++
南一中高一資訊科教材
Table of Contents

1. Sort
排序(Sorting)是將一組資料依照特定的順序重新排列的過程,是程式設計中最基礎也最重要的演算法之一。
1.1. Bubble Sort (氣泡排序)
氣泡排序的概念很簡單:反覆比較相鄰的兩個元素,如果順序不對就交換,就像水中的氣泡一樣,較大的元素會逐漸「浮」到陣列的尾端。
1: #include <iostream> 2: using namespace std; 3: 4: int main() { 5: int arr[] = {64, 34, 25, 12, 22, 11, 90}; 6: int n = 7; 7: 8: // Bubble Sort 9: for (int i = 0; i < n - 1; i++) { // 共需 n-1 輪 10: for (int j = 0; j < n - 1 - i; j++) { // 每輪少比一次 11: if (arr[j] > arr[j + 1]) { 12: // 交換 13: int temp = arr[j]; 14: arr[j] = arr[j + 1]; 15: arr[j + 1] = temp; 16: } 17: } 18: } 19: 20: cout << "排序結果: "; 21: for (int i = 0; i < n; i++) 22: cout << arr[i] << " "; 23: cout << endl; 24: return 0; 25: }
- 時間複雜度:O(n²)
- 空間複雜度:O(1)
1.2. Selection Sort (選擇排序)
選擇排序的想法是:每一輪從未排序的部分中找出最小值,放到已排序部分的尾端。
1: #include <iostream> 2: using namespace std; 3: 4: int main() { 5: int arr[] = {64, 25, 12, 22, 11}; 6: int n = 5; 7: 8: for (int i = 0; i < n - 1; i++) { 9: int minIdx = i; // 假設目前位置為最小值 10: for (int j = i + 1; j < n; j++) { 11: if (arr[j] < arr[minIdx]) 12: minIdx = j; // 記錄更小值的位置 13: } 14: // 將最小值交換到正確位置 15: int temp = arr[i]; 16: arr[i] = arr[minIdx]; 17: arr[minIdx] = temp; 18: } 19: 20: cout << "排序結果: "; 21: for (int i = 0; i < n; i++) 22: cout << arr[i] << " "; 23: cout << endl; 24: return 0; 25: }
- 時間複雜度:O(n²)
- 空間複雜度:O(1)
1.3. Insertion Sort (插入排序)
插入排序的概念類似於打撲克牌時整理手牌的方式:從第二張牌開始,將每張牌插入到前面已排序部分的正確位置。
1: #include <iostream> 2: using namespace std; 3: 4: int main() { 5: int arr[] = {12, 11, 13, 5, 6}; 6: int n = 5; 7: 8: for (int i = 1; i < n; i++) { 9: int key = arr[i]; // 要插入的元素 10: int j = i - 1; 11: // 將比 key 大的元素往後移 12: while (j >= 0 && arr[j] > key) { 13: arr[j + 1] = arr[j]; 14: j--; 15: } 16: arr[j + 1] = key; // 插入正確位置 17: } 18: 19: cout << "排序結果: "; 20: for (int i = 0; i < n; i++) 21: cout << arr[i] << " "; 22: cout << endl; 23: return 0; 24: }
- 時間複雜度:O(n²),但對於近乎排序好的資料效率很高
- 空間複雜度:O(1)
1.4. 三種排序法比較
| 排序法 | 最佳 | 平均 | 最差 | 穩定性 |
|---|---|---|---|---|
| Bubble | O(n) | O(n²) | O(n²) | 穩定 |
| Selection | O(n²) | O(n²) | O(n²) | 不穩定 |
| Insertion | O(n) | O(n²) | O(n²) | 穩定 |
2. String
在程式中,我們經常需要處理文字資料,例如姓名、地址、訊息等。在 C++ 中,處理文字有兩種方式:
- char 字元 :儲存單一字元,如 ’A’、’3’、’!’
- string 字串 :儲存一串文字,如 “Hello world”、“TNFSH403”
我們先從最基本的字元開始認識。
2.1. char 字元
- ASCII Code
ASCII(American Standard Code for Information Interchange) 碼是電腦用來表示字母、數字、符號的編碼系統。
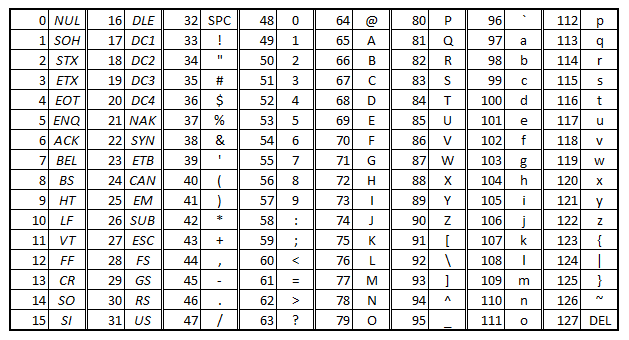
在上圖中,我們可以看到每個字元對應的 ASCII 編號,例如大寫字母 A 的 ASCII 編號為 65,小寫字母 a 的 ASCII 編號為 97,數字 0 的 ASCII 編號為 48,空白字元(space)的 ASCII 編號為 32,換行字元(new line)的 ASCII 編號為 10,NULL 字元的 ASCII 編號為 0。
這個表告訴我們,電腦內部是以數字來表示字元的,而我們在程式中看到的字元只是電腦將這些數字轉換成我們熟悉的符號而已。
在 C++ 中,可以用 char 型態來儲存字元。由於字元本質上就是數字,因此 char 和 int 之間可以互相轉換:
1: #include <iostream> 2: using namespace std; 3: int main() { 4: char ch = 'A'; 5: cout << "字元: " << ch << endl; 6: cout << "ASCII 編號: " << (int)ch << endl; // char 轉 int 7: 8: int code = 66; 9: cout << "編號 66 對應的字元: " << (char)code << endl; // int 轉 char 10: return 0; 11: }
- 字元運算
由於在電腦內部字元是以數字來表示的,所以我們可以對字元進行數學運算,例如:
1: #include <iostream> 2: using namespace std; 3: int main() { 4: char ch = 'A'; 5: ch = ch + 1; // 65 + 1 = 66,對應字元 'B' 6: cout << "A + 1 = " << ch << endl; 7: return 0; 8: }
利用這個特性,我們可以進行大小寫轉換。觀察 ASCII 表可以發現,大寫字母 A~Z 的編號為 65~90,小寫字母 a~z 的編號為 97~122,兩者之間差了 32。因此,我們可以用
'a' - 'A'這個差值來轉換大小寫:
1: #include <iostream> 2: using namespace std; 3: int main() { 4: char lower = 'g'; 5: // 小寫轉大寫:減去大小寫之間的差值 6: char upper = lower - 'a' + 'A'; 7: cout << lower << " 轉大寫: " << upper << endl; 8: 9: // 大寫轉小寫:加上大小寫之間的差值 10: char ch = 'D'; 11: char low = ch - 'A' + 'a'; 12: cout << ch << " 轉小寫: " << low << endl; 13: return 0; 14: }
另外,我們也可以用字元來進行比較運算,因為比較的其實是 ASCII 編號的大小:
1: #include <iostream> 2: using namespace std; 3: int main() { 4: char ch1 = 'A'; // ASCII 65 5: char ch2 = 'B'; // ASCII 66 6: if (ch1 < ch2) { 7: cout << ch1 << " 小於 " << ch2 << endl; 8: } 9: 10: // 判斷某個字元是否為大寫字母 11: char ch = 'G'; 12: if (ch >= 'A' && ch <= 'Z') { 13: cout << ch << " 是大寫字母" << endl; 14: } 15: return 0; 16: }
2.2. string 字串
- 宣告與初始化
字串(string)由一個一個的字元(char)組成。在 C++ 中,有兩種方式可以儲存字串:
char[]字元陣列:C 語言的傳統寫法,需要事先決定陣列大小string型態:C++ 提供的字串型態,使用上更方便,不需要事先決定長度
1: #include <iostream> 2: #include <cstring> 3: using namespace std; 4: int main() { 5: // 方法1: 字元陣列(需指定大小,且結尾必須有 '\0') 6: char name1[6] = {'T', 'N', 'F', 'S', 'H', '\0'}; 7: 8: // 方法2: string(不需指定大小,使用更方便) 9: string name2 = "TNFSH"; 10: 11: cout << name1 << ", 長度: " << strlen(name1) << endl; 12: cout << name2 << ", 長度: " << name2.length() << endl; 13: return 0; 14: }
不管是以字元陣列或是 string 來儲存字串,最後都有一個代表字串結尾的隱藏字元
'\0'來告訴電腦這個字串到此為止。'\0'的 ASCII 編號為 0,代表 NULL。這個'\0'不會被輸出,也不被算在字串長度裡。
要留意的是,對 C++ 來說,char[] 與 string 是兩種不同的資料型態。在 C++ 中,strlen() 需要 include <cstring>,而 length() 則是 string 型態內建的方法。一般而言,在 C++ 中建議優先使用 string,因為它更安全也更方便。
- 字串輸入
- scanf()
scanf 是 C 語言的輸入方式,在 C++ 中也可以使用,但需要 include <cstdio>。scanf 讀取字串時,遇到空白字元便會結束,且只能搭配 char[] 使用,不能搭配 string。
1: #include <stdio.h> 2: int main() { 3: char str[10]; 4: scanf("%s", str); 5: printf("Your name: %s\n", str); 6: }
- cin
C++ 的標準輸入方式,既可以讀字元,又可以讀字串,也可以搭配 string 使用。和 scanf 一樣,遇到空白字元或 Enter 便會結束。
1: #include <iostream> 2: using namespace std; 3: int main() { 4: string name1, name2; 5: cin >> name1 >> name2; 6: cout << "Welcome, " << name1 << ", " << name2 << endl; 7: }
- getline(cin, str)
如果要讀入包含空白的整行文字,可以使用 getline。它會讀到 Enter 為止,中間的空白也會保留。需要 include <string>。
1: #include <iostream> 2: #include <string> 3: using namespace std; 4: int main() { 5: string school; 6: getline(cin, school); 7: cout << school << endl; 8: }
若使用 char[] 字元陣列,則改用 cin.getline(),需要多指定陣列大小作為第二個參數:
1: #include <iostream> 2: using namespace std; 3: int main() { 4: char school[50]; 5: cin.getline(school, 50); 6: cout << school << endl; 7: }
以下整理各種輸入方式的比較:
方式 搭配型態 遇空白停止 語言 scanf() char[] 是 C cin >> 兩者皆可 是 C++ getline(cin, str) string 否 C++ cin.getline() char[] 否 C++
- scanf()
- 常用操作
以下介紹 string 型態最常用的操作,這些在解題時會經常用到。
- 長度
1: #include <iostream> 2: #include <string> 3: using namespace std; 4: int main() { 5: string s = "Hello"; 6: cout << "長度: " << s.length() << endl; // 也可以用 s.size() 7: }
如果是 char[] 字元陣列,則需要 include <cstring>,並使用 strlen() 函式來取得長度:
1: #include <iostream> 2: #include <cstring> 3: using namespace std; 4: int main() { 5: char s[] = "Hello"; 6: cout << "長度: " << strlen(s) << endl; 7: }
- 字串串接
用
+可以將兩個字串接在一起:
1: #include <iostream> 2: #include <string> 3: using namespace std; 4: int main() { 5: string first = "Hello"; 6: string second = "World"; 7: string result = first + " " + second + "!"; 8: cout << result << endl; 9: }
如果是 char[] 字元陣列,則需要 include <cstring>,並使用 strcat() 函式來串接字串:
1: #include <iostream> 2: #include <cstring> 3: using namespace std; 4: int main() { 5: char first[20] = "Hello"; 6: char second[] = "World"; 7: strcat(first, " "); // 先串接空格 8: strcat(first, second); // 再串接 second 9: cout << first << endl; 10: }
- 字串比較
string 可以直接用
==,!,<, =>等運算子來比較,比較的依據是字典順序(lexicographic order):
1: #include <iostream> 2: #include <string> 3: using namespace std; 4: int main() { 5: string a = "apple"; 6: string b = "banana"; 7: if (a < b) { 8: cout << a << " 排在 " << b << " 前面" << endl; 9: } 10: if (a == "apple") { 11: cout << "a 的內容是 apple" << endl; 12: } 13: }
如果是 char[] 字元陣列,則需要 include <cstring>,並使用 strcmp() 函式來比較字串:
1: #include <iostream> 2: #include <cstring> 3: using namespace std; 4: int main() { 5: char a[] = "apple"; 6: char b[] = "banana"; 7: if (strcmp(a, b) < 0) { 8: cout << a << " 排在 " << b << " 前面" << endl; 9: } 10: if (strcmp(a, "apple") == 0) { 11: cout << "a 的內容是 apple" << endl; 12: } 13: }
- 存取個別字元
可以用
[]存取字串中的個別字元,index 從 0 開始,和陣列一樣:
1: #include <iostream> 2: #include <string> 3: using namespace std; 4: int main() { 5: string s = "TNFSH"; 6: cout << "第一個字元: " << s[0] << endl; 7: cout << "第三個字元: " << s[2] << endl; 8: 9: // 也可以修改個別字元 10: s[0] = 'X'; 11: cout << "修改後: " << s << endl; 12: }
如果是 char[] 字元陣列,則同樣可以用
[]存取個別字元:
1: #include <iostream> 2: using namespace std; 3: int main() { 4: char s[] = "TNFSH"; 5: cout << "第一個字元: " << s[0] << endl; 6: cout << "第三個字元: " << s[2] << endl; 7: // 也可以修改個別字元 8: s[0] = 'X'; 9: cout << "修改後: " << s << endl; 10: }
- 取子字串 substr()
substr(起始位置, 長度) 可以從字串中取出一部分:
1: #include <iostream> 2: #include <string> 3: using namespace std; 4: int main() { 5: string s = "Hello World"; 6: cout << s.substr(0, 5) << endl; // 從 index 0 開始取 5 個字元 7: cout << s.substr(6) << endl; // 從 index 6 開始取到結尾 8: }
如果是 char[] 字元陣列,則需要 include <cstring>,並使用 strncpy() 函式來取子字串:
1: #include <iostream> 2: #include <cstring> 3: using namespace std; 4: int main() { 5: char s[] = "Hello World"; 6: char sub[20]; 7: strncpy(sub, s, 5); // 從 s 的開頭複製 8: sub[5] = '\0'; // 記得加上結尾字元 9: cout << sub << endl; 10: strncpy(sub, s + 6, strlen(s) - 6); // 從 s 的 index 6 開始複製 11: sub[strlen(s) - 6] = '\0'; // 記得加上結尾字元 12: cout << sub << endl; 13: }
- 搜尋 find()
find() 可以在字串中搜尋某個字元或子字串,找到則回傳起始位置(index),找不到則回傳
string::npos:
1: #include <iostream> 2: #include <string> 3: using namespace std; 4: int main() { 5: string s = "Hello World"; 6: 7: int pos = s.find("World"); 8: if (pos != string::npos) { 9: cout << "找到 World,位置在 index " << pos << endl; 10: } 11: 12: if (s.find("xyz") == string::npos) { 13: cout << "找不到 xyz" << endl; 14: } 15: }
如果是 char[] 字元陣列,則需要 include <cstring>,並使用 strstr() 函式來搜尋子字串:
1: #include <iostream> 2: #include <cstring> 3: using namespace std; 4: int main() { 5: char s[] = "Hello World"; 6: char* pos = strstr(s, "World"); 7: if (pos != nullptr) { 8: cout << "找到 World,位置在 index " << (pos - s) << endl 9: << "找到的子字串: " << pos << endl; 10: } 11: if (strstr(s, "xyz") == nullptr) { 12: cout << "找不到 xyz" << endl; 13: } 14: return 0; 15: }
- 長度
3. 2D Array
3.1. Array of string
- CPP
- C
1: #include <stdio.h> 2: #include <string.h> 3: #include <stdlib.h> 4: int main(int argc, const char * argv[]) { 5: // insert code here... 6: char poker[53][5]; 7: char m[4] = {'A','B','C','D'}; 8: char tmp[5]; 9: int i, j, k; 10: for (i = 0; i < 4; i++) { 11: for (j = 0; j < 13; j++) { 12: k = 13 * i + j; 13: sprintf(tmp, "%d%c", j+1, m[i]); 14: //printf("%d: %s\n", k, tmp); 15: strcpy(poker[k], tmp); 16: } 17: } 18: for (i = 0; i < 52; i++) { 19: printf("%s\n", poker[i]); 20: } 21: 22: return 0; 23: } 24:
4. Variable
4.1. Global v.s. Local
在 C/C++ 中,變數依照宣告的位置不同,可分為全域變數(Global Variable)和區域變數(Local Variable),兩者的生命週期與可見範圍(scope)截然不同。
- Global Variable (全域變數)
宣告在所有函式之外的變數,程式中任何函式都可以存取。
- Local Variable (區域變數)
宣告在函式或區塊(大括號 {} )內的變數,只在該區塊內有效。
1: #include <iostream> 2: using namespace std; 3: 4: int globalVar = 100; // 全域變數,所有函式都能存取 5: 6: void showValues() { 7: int localVar = 50; // 區域變數,只在此函式內有效 8: cout << "在 showValues() 中:" << endl; 9: cout << " globalVar = " << globalVar << endl; 10: cout << " localVar = " << localVar << endl; 11: } 12: 13: int main() { 14: int localVar = 200; // 此 localVar 與 showValues() 中的不同 15: 16: cout << "在 main() 中:" << endl; 17: cout << " globalVar = " << globalVar << endl; 18: cout << " localVar = " << localVar << endl; 19: 20: showValues(); 21: 22: globalVar = 999; // 修改全域變數 23: cout << "修改後 globalVar = " << globalVar << endl; 24: 25: return 0; 26: }
- 注意事項
- 全域變數若未初始化,預設值為 0;區域變數若未初始化,其值為不確定(garbage value)
- 當全域變數和區域變數同名時,在函式內會優先使用區域變數(區域變數會遮蔽全域變數)
- 過度使用全域變數會讓程式難以維護與除錯,應盡量使用區域變數
- 全域變數若未初始化,預設值為 0;區域變數若未初始化,其值為不確定(garbage value)
5. Function
當一支程式越寫越長,常常會出現「同一段程式碼在不同地方一直重複出現」的情況。為了讓程式更簡潔、更好維護,我們可以把一段有特定功能的程式碼包裝起來,給它取一個名字,之後想用的時候只要呼叫這個名字就好,這就是 function(函式) 。
事實上我們已經用過 function 了,例如 main() 就是一個 function,它是程式的進入點;而 cout 後面接的 endl 、或者像 sqrt() 這些也都是 function。本節要學的是如何「自己寫一個 function」。
5.1. 為什麼要寫 function?
- 避免重複 :相同的程式碼只要寫一次,需要的時候再呼叫
- 讓 main() 更乾淨 :把細節藏起來,main() 只負責「指揮」
- 分工合作 :每個 function 負責一件事,程式比較好讀也比較好除錯
5.2. 最簡單的 function
先從一個沒有參數、也沒有回傳值的 function 開始:
1: #include <iostream> 2: using namespace std; 3: void sayHello() { // 定義一個叫做 sayHello 的 function 4: cout << "Hello!" << endl; 5: cout << "歡迎學 C++" << endl; 6: } 7: int main() { 8: sayHello(); // 呼叫 function 9: sayHello(); // 想用幾次就呼叫幾次 10: sayHello(); 11: }
說明:
void表示這個 function「不會回傳東西」sayHello是 function 的名字,命名規則和變數一樣()裡面放參數,目前是空的表示「不需要外部給資料」main()裡面寫sayHello();就會去執行 function 裡的程式碼
5.3. function 的基本結構
回傳值型態 function名稱(參數列) { // 要做的事 return 回傳值; // 如果回傳值型態是 void,這行可以省略 }
5.4. 加上參數
參數(parameter)讓我們可以把資料「傳進去」給 function 處理。下面這支程式可以畫出任意長度的星號線:
1: #include <iostream> 2: using namespace std; 3: void drawLine(int n) { // n 是參數,由呼叫的人決定 4: for (int i = 0; i < n; i++) { 5: cout << "*"; 6: } 7: cout << endl; 8: } 9: int main() { 10: drawLine(5); // 印出 5 個星號 11: drawLine(10); // 印出 10 個星號 12: drawLine(3); 13: }
也可以傳多個參數:
1: #include <iostream> 2: using namespace std; 3: void printRectangle(int w, int h) { 4: for (int i = 0; i < h; i++) { 5: for (int j = 0; j < w; j++) { 6: cout << "*"; 7: } 8: cout << endl; 9: } 10: } 11: int main() { 12: printRectangle(6, 3); // 寬 6、高 3 的矩形 13: }
5.5. 有回傳值的 function
如果希望 function 「算出一個答案交回來」,就要設定回傳值型態,並用 return 把結果送回去。
1: #include <iostream> 2: using namespace std; 3: int add(int a, int b) { // 回傳值型態是 int 4: return a + b; // 把 a+b 的結果交回去 5: } 6: int main() { 7: int x = add(3, 5); // x 會得到 8 8: cout << "3 + 5 = " << x << endl; 9: cout << "10 + 20 = " << add(10, 20) << endl; // 也可以直接用在 cout 10: }
再看一個例子:判斷一個數是不是偶數
1: #include <iostream> 2: using namespace std; 3: bool isEven(int n) { 4: return n % 2 == 0; 5: } 6: int main() { 7: for (int i = 1; i <= 6; i++) { 8: if (isEven(i)) { 9: cout << i << " 是偶數" << endl; 10: } else { 11: cout << i << " 是奇數" << endl; 12: } 13: } 14: }
5.6. function 呼叫的執行流程
要進入下一節的遞迴之前,先弄清楚 function 「被呼叫」時到底發生了什麼事:
- 程式遇到 function 呼叫時,會「暫停」目前的工作
- 跳到該 function 裡面,從第一行開始執行
- 執行完(或遇到
return)後,把結果帶回原本的呼叫點 - 回到原本的位置繼續往下執行
1: #include <iostream> 2: using namespace std; 3: int square(int n) { 4: cout << " 進入 square,n = " << n << endl; 5: int result = n * n; 6: cout << " 離開 square,回傳 " << result << endl; 7: return result; 8: } 9: int main() { 10: cout << "main 開始" << endl; 11: int a = square(4); 12: cout << "main 拿到 " << a << endl; 13: cout << "main 結束" << endl; 14: }
理解這個「跳進去、做完、回到原處」的流程非常重要。因為如果一個 function 在自己裡面又呼叫了自己,會發生什麼事?這就是後面要談的 遞迴(Recursion) 。
5.8. Recursion
遞迴(Recursion)是指函式在執行過程中呼叫自己本身的技巧。每一個遞迴函式都需要具備兩個要素:
- 終止條件(Base Case) :讓遞迴停止的條件,否則會無窮呼叫導致程式崩潰
- 遞迴呼叫(Recursive Case) :函式呼叫自己,但問題規模必須逐漸縮小
- 階乘 (Factorial)
n! = n × (n-1) × (n-2) × … × 1,例如 5! = 5 × 4 × 3 × 2 × 1 = 120。
1: #include <iostream> 2: using namespace std; 3: 4: int factorial(int n) { 5: if (n <= 1) // Base Case:0! = 1, 1! = 1 6: return 1; 7: return n * factorial(n - 1); // Recursive Case 8: } 9: 10: int main() { 11: for (int i = 0; i <= 10; i++) 12: cout << i << "! = " << factorial(i) << endl; 13: return 0; 14: }
- 費氏數列 (Fibonacci)
費氏數列的定義為:F(0)=0, F(1)=1, F(n)=F(n-1)+F(n-2)。
1: #include <iostream> 2: using namespace std; 3: 4: int fibonacci(int n) { 5: if (n == 0) return 0; // Base Case 6: if (n == 1) return 1; // Base Case 7: return fibonacci(n - 1) + fibonacci(n - 2); // Recursive Case 8: } 9: 10: int main() { 11: cout << "費氏數列前 15 項:" << endl; 12: for (int i = 0; i < 15; i++) 13: cout << "F(" << i << ") = " << fibonacci(i) << endl; 14: return 0; 15: }
- 河內塔 (Tower of Hanoi)
經典的遞迴問題:將 n 個盤子從 A 柱移動到 C 柱,過程中可借助 B 柱,且大盤不可放在小盤上方。
1: #include <iostream> 2: using namespace std; 3: 4: void hanoi(int n, char from, char to, char aux) { 5: if (n == 1) { 6: cout << "將盤子 1 從 " << from << " 移到 " << to << endl; 7: return; 8: } 9: hanoi(n - 1, from, aux, to); // 先將上方 n-1 個盤子移到輔助柱 10: cout << "將盤子 " << n << " 從 " << from << " 移到 " << to << endl; 11: hanoi(n - 1, aux, to, from); // 再將 n-1 個盤子從輔助柱移到目標柱 12: } 13: 14: int main() { 15: int n = 3; 16: cout << n << " 個盤子的河內塔步驟:" << endl; 17: hanoi(n, 'A', 'C', 'B'); 18: return 0; 19: }
- 遞迴 vs. 迴圈
- 遞迴程式碼通常較簡潔易讀,但每次呼叫會佔用 stack 記憶體,層數過深會導致 stack overflow
- 迴圈效率通常較高,不會有 stack overflow 的問題
- 許多遞迴問題都可以改寫為迴圈版本
- 遞迴程式碼通常較簡潔易讀,但每次呼叫會佔用 stack 記憶體,層數過深會導致 stack overflow
6. 資料結構初探:Stack 與 Queue
6.1. 什麼是「資料結構」?
在這份講義裡,我們已經用過陣列(array)、字串(string)、變數來存資料。這些「把資料放在記憶體裡的方式」,再加上「規定能用哪些操作去存取它」,合起來就叫做 資料結構 (Data Structure) 。
換句話說,一個資料結構 = 資料的擺放方式 + 允許的操作 。例如陣列的擺放方式是「一塊連續記憶體」,允許的操作是「用索引隨機存取任一格」。
到目前為止,我們碰到的資料結構幾乎都是「想怎麼讀就怎麼讀、想怎麼寫就怎麼寫」的自由型。但接下來要介紹的 Stack 和 Queue 卻是 刻意限制 操作的資料結構——你只能從特定的一端放入、從特定的一端取出,中間的資料完全碰不到。這聽起來像是自找麻煩,為什麼還要這樣設計?
6.2. 為什麼要有「操作受限」的資料結構?
原因可以從三個角度來看:
- 對應真實世界的流程 :很多問題本身就有先後順序的約束。排隊買票一定是先來先服務(FIFO);瀏覽器按上一頁一定是回到「最近一次」造訪的頁面(LIFO)。直接用一個和問題本質吻合的資料結構,程式碼會非常乾淨;硬用陣列來模擬反而要自己記一堆 index、容易寫錯。
- 限制 = 保證 :當一個資料結構規定「只能從頂端拿」,編譯器、其他工程師、甚至幾個月後的你自己看到 stack 這個型別,就立刻知道資料的流動方向。限制換來的是 程式碼可讀性 與 正確性的保證 ——別人不可能不小心從中間插一筆資料進來把邏輯弄壞。
- 效率上的最佳化 :因為操作受限,底層實作就能針對那幾個操作做最佳化。Stack 的 push/pop、Queue 的 enqueue/dequeue 都是 O(1);如果用普通陣列模擬「從前面拿一個」則是 O(n)。
6.3. 什麼時候會用到 Stack 和 Queue?
- Stack :只要問題出現「最近一個」、「回到上一步」、「巢狀對應」這類字眼,幾乎都是 stack 的場合。例如:
- 括號配對 (
(()())是否合法) - 運算式求值、編譯器的語法分析
- 函式呼叫本身就是用 call stack 管理
- 深度優先搜尋 (DFS)、回溯法(backtracking)
- Undo / Redo、瀏覽器上一頁
- 括號配對 (
- Queue :只要問題出現「先到先處理」、「一層一層擴散」就是 queue 的場合。例如:
- 作業系統的工作排程、印表機列印序列
- 廣度優先搜尋 (BFS)——尤其是「最短步數」類型的題目
- 訊息佇列、生產者-消費者模型
- 模擬排隊系統(銀行、客服)
- 作業系統的工作排程、印表機列印序列
寫競賽題、刷 LeetCode 時,一看到題目敘述就能立刻判斷「這題要用 stack/queue」,是非常基本但關鍵的判斷力。
6.4. 之後還會學到的:大學的「資料結構」課
Stack 和 Queue 只是冰山一角。資訊相關科系(資工、資科、資管、電機等)在大二幾乎都會有一門必修課叫做 資料結構 (Data Structures) ,內容會延伸到:
- Linked List(鏈結串列)
- Tree、Binary Search Tree、Heap、AVL Tree、紅黑樹
- Hash Table(雜湊表)
- Graph(圖)及其各種走訪/最短路徑演算法
這門課之所以是整個資工教育的基石,原因是:
- 它決定你寫的程式跑多快 :同樣是「找一個元素」,用陣列要 O(n)、用雜湊表是 O(1)、用平衡樹是 O(log n)。選對資料結構,效能差距可以是百倍千倍。
- 它是面試的核心考點 :不論是台灣的科技業、外商還是中國的大廠,技術面試幾乎一定會考資料結構與演算法。
- 它訓練的是抽象思考 :把現實問題轉換成「資料怎麼存、操作怎麼定義」的能力,是寫任何規模程式的基本功。
現在先把 Stack 和 Queue 學熟、能用陣列自己刻一份、也會用 STL 提供的版本,對未來銜接這門課會非常有幫助。
6.5. Stack
Stack(堆疊)是一種後進先出(LIFO, Last In First Out)的資料結構,就像疊盤子一樣,最後放上去的盤子會最先被拿走。
Stack 的基本操作:
- push :將元素放入堆疊頂端
- pop :移除堆疊頂端的元素
- top :查看堆疊頂端的元素(不移除)
- empty :檢查堆疊是否為空
- 用陣列實作 Stack
1: #include <iostream> 2: using namespace std; 3: 4: const int MAX_SIZE = 100; 5: int stack[MAX_SIZE]; 6: int topIdx = -1; // -1 表示空堆疊 7: 8: void push(int val) { 9: if (topIdx >= MAX_SIZE - 1) { 10: cout << "Stack Overflow!" << endl; 11: return; 12: } 13: stack[++topIdx] = val; 14: } 15: 16: void pop() { 17: if (topIdx < 0) { 18: cout << "Stack Underflow!" << endl; 19: return; 20: } 21: topIdx--; 22: } 23: 24: int top() { 25: return stack[topIdx]; 26: } 27: 28: bool empty() { 29: return topIdx < 0; 30: } 31: 32: int main() { 33: push(10); 34: push(20); 35: push(30); 36: cout << "頂端元素: " << top() << endl; // 30 37: 38: pop(); 39: cout << "pop 後頂端元素: " << top() << endl; // 20 40: 41: pop(); 42: pop(); 43: cout << "Stack 是否為空: " << (empty() ? "是" : "否") << endl; 44: return 0; 45: }
- 使用 C++ STL 的 stack
1: #include <iostream> 2: #include <stack> 3: using namespace std; 4: 5: int main() { 6: stack<int> s; 7: s.push(10); 8: s.push(20); 9: s.push(30); 10: 11: cout << "頂端: " << s.top() << endl; 12: s.pop(); 13: cout << "pop 後頂端: " << s.top() << endl; 14: cout << "大小: " << s.size() << endl; 15: return 0; 16: }
- Stack 的應用
- 括號配對檢查
- 運算式求值(中序轉後序)
- 函式呼叫的 call stack
- 瀏覽器的上一頁功能(Back)
- 括號配對檢查
6.6. Queue
Queue(佇列)是一種先進先出(FIFO, First In First Out)的資料結構,就像排隊買東西一樣,先排的人先服務。
Queue 的基本操作:
- enqueue(push) :將元素加入佇列尾端
- dequeue(pop) :移除佇列前端的元素
- front :查看佇列前端的元素
- empty :檢查佇列是否為空
- 用陣列實作 Queue
1: #include <iostream> 2: using namespace std; 3: 4: const int MAX_SIZE = 100; 5: int queue[MAX_SIZE]; 6: int frontIdx = 0, rearIdx = 0; 7: 8: void enqueue(int val) { 9: if (rearIdx >= MAX_SIZE) { 10: cout << "Queue 已滿!" << endl; 11: return; 12: } 13: queue[rearIdx++] = val; 14: } 15: 16: void dequeue() { 17: if (frontIdx >= rearIdx) { 18: cout << "Queue 為空!" << endl; 19: return; 20: } 21: frontIdx++; 22: } 23: 24: int front() { 25: return queue[frontIdx]; 26: } 27: 28: bool empty() { 29: return frontIdx >= rearIdx; 30: } 31: 32: int main() { 33: enqueue(10); 34: enqueue(20); 35: enqueue(30); 36: cout << "前端元素: " << front() << endl; // 10 37: 38: dequeue(); 39: cout << "dequeue 後前端元素: " << front() << endl; // 20 40: 41: cout << "Queue 是否為空: " << (empty() ? "是" : "否") << endl; 42: return 0; 43: }
- 使用 C++ STL 的 queue
1: #include <iostream> 2: #include <queue> 3: using namespace std; 4: 5: int main() { 6: queue<int> q; 7: q.push(10); 8: q.push(20); 9: q.push(30); 10: 11: cout << "前端: " << q.front() << endl; 12: cout << "尾端: " << q.back() << endl; 13: q.pop(); 14: cout << "pop 後前端: " << q.front() << endl; 15: cout << "大小: " << q.size() << endl; 16: return 0; 17: }
- Queue 的應用
- 作業系統的工作排程(CPU scheduling)
- 印表機列印佇列
- 廣度優先搜尋(BFS)
- 訊息傳遞系統
- 作業系統的工作排程(CPU scheduling)
7. 指標Pointer
到目前為止,我們處理變數時都直接用「名字」存取它的值,例如 int x = 5; 之後寫 x 就是 5。但每個變數其實都住在記憶體裡的某個位置,這個位置有一個編號,叫做 記憶體位址 (memory address) 。 指標 (pointer) 就是「專門用來存放位址」的變數。
理解指標是 C/C++ 和其他高階語言最大的分水嶺。學會指標之後,才能真正理解:
- 為什麼陣列名稱可以直接傳給函式?
- 為什麼
cin >> x要寫&x?(在 scanf 中) - 為什麼字串可以用
char *存? - 動態配置記憶體 (
new/delete)、Linked List、Tree 等資料結構的底層都在做什麼?
7.1. 取址運算子 & 與間接運算子 *
兩個關鍵符號:
&x:取出變數 x 的「記憶體位址」*p:把指標 p 「解參照(dereference)」,存取它指到的那塊記憶體的內容
1: #include <iostream> 2: using namespace std; 3: int main() { 4: int x = 42; 5: int *p = &x; // p 是指向 int 的指標,存放 x 的位址 6: 7: cout << "x 的值 = " << x << endl; 8: cout << "x 的位址 = " << &x << endl; 9: cout << "p 存的位址 = " << p << endl; // 應該和 &x 一樣 10: cout << "p 指到的內容 = " << *p << endl; // 應該是 42 11: 12: *p = 100; // 透過指標修改 x 13: cout << "修改後 x = " << x << endl; 14: return 0; 15: }
重點:
- 宣告
int *p的星號表示「p 是指標」;之後*p出現在程式裡則表示「解參照」。同一個符號在不同位置代表不同意義,初學者最常搞混的就是這個。 - 一個指標一定要先「指向某個東西」才能解參照,否則會存取到垃圾位址,程式可能直接 crash (Segmentation Fault)。
7.2. nullptr :空指標
還沒指向任何地方的指標,應該明確設成 nullptr (C++11 之後的標準寫法;舊寫法是 NULL 或 0)。
1: #include <iostream> 2: using namespace std; 3: int main() { 4: int *p = nullptr; 5: if (p == nullptr) { 6: cout << "p 還沒指到任何地方,先別用它" << endl; 7: } 8: int x = 7; 9: p = &x; // 現在 p 有效了 10: cout << *p << endl; 11: return 0; 12: }
7.3. 指標與陣列
這是 C/C++ 中最重要的關聯之一: 陣列名稱本身就是一個指向第一個元素的指標 。
1: #include <iostream> 2: using namespace std; 3: int main() { 4: int arr[5] = {10, 20, 30, 40, 50}; 5: 6: cout << "arr = " << arr << endl; // 第一個元素的位址 7: cout << "&arr[0] = " << &arr[0] << endl; // 相同 8: cout << "*arr = " << *arr << endl; // 等於 arr[0] = 10 9: 10: // 用指標走訪陣列 11: int *p = arr; 12: for (int i = 0; i < 5; i++) { 13: cout << "arr[" << i << "] = " << *(p + i) << endl; 14: } 15: return 0; 16: }
p + i 並不是把位址加 i,而是「往後跳 i 個元素」(也就是 i × sizeof(int) 個 byte),這稱為 指標運算 (pointer arithmetic) 。
正因為陣列名稱就是指標,所以下列兩種寫法在函式參數中是等價的:
void f(int arr[], int n); // 看起來是陣列 void f(int *arr, int n); // 本質上是指標
兩者完全相同——這也解釋了為什麼陣列傳進函式後,用 sizeof(arr) 算出來不是整個陣列大小,只是一個指標的大小。
7.4. 用指標讓函式「改到外面的變數」(pass by pointer)
一般的函式參數是 值傳遞 (pass by value) ,函式內部修改不會影響呼叫者:
1: #include <iostream> 2: using namespace std; 3: void addOne(int x) { x = x + 1; } // x 只是個副本 4: int main() { 5: int a = 10; 6: addOne(a); 7: cout << "a = " << a << endl; // 還是 10 8: return 0; 9: }
若希望函式修改到外面真正的變數,可以傳「指標」進去:
1: #include <iostream> 2: using namespace std; 3: void addOne(int *x) { *x = *x + 1; } // 透過指標改原本的變數 4: void swap(int *a, int *b) { 5: int t = *a; 6: *a = *b; 7: *b = t; 8: } 9: int main() { 10: int a = 10; 11: addOne(&a); 12: cout << "a = " << a << endl; // 11 13: 14: int x = 1, y = 9; 15: swap(&x, &y); 16: cout << "x = " << x << ", y = " << y << endl; // 9, 1 17: return 0; 18: }
C 語言只能這樣做。C++ 提供更乾淨的「參考 (reference)」語法 int &x ,效果一樣但呼叫時不用寫 & ,後面進階主題會再介紹。
7.5. 指標陣列
「指標陣列 (array of pointers)」就是一個陣列裡每個元素都是指標。最常見的用途是存放多個字串:
1: #include <iostream> 2: using namespace std; 3: int main() { 4: const char *names[] = {"Alice", "Bob", "Charlie", "David"}; 5: int n = sizeof(names) / sizeof(names[0]); 6: 7: for (int i = 0; i < n; i++) { 8: cout << i << ": " << names[i] << endl; 9: } 10: return 0; 11: }
每個 names[i] 都是一個 const char * ,分別指向 “Alice”、“Bob”… 這些字串字面值。這個技巧在處理「多筆字串資料」時非常常見。
7.6. 動態配置記憶體 new / delete
一般變數的生命週期由編譯器決定 (區域變數離開大括號就消失)。如果想在執行期才決定要多少記憶體、且要自己控制何時釋放,就要用 new 配置、 delete 釋放:
1: #include <iostream> 2: using namespace std; 3: int main() { 4: int n; 5: cout << "要幾個元素?"; 6: n = 5; // 假設輸入 5 7: 8: int *arr = new int[n]; // 執行期才決定大小 9: for (int i = 0; i < n; i++) arr[i] = i * i; 10: for (int i = 0; i < n; i++) cout << arr[i] << " "; 11: cout << endl; 12: 13: delete[] arr; // 用 new[] 配置就要用 delete[] 釋放 14: return 0; 15: }
要點:
new int配單一一個 int,對應delete。new int[n]配 n 個 int 的陣列,對應delete[]。- 配了不 delete 就是 記憶體洩漏 (memory leak) 。
- 在現代 C++ 裡,多數情況直接用
vector或 智慧指標 (smart pointer) (unique_ptr/shared_ptr) 取代手動 new/delete,會更安全。
7.7. 進階閱讀
8. 資料結構
8.1. Array
- Find 2’s complement: https://www.youtube.com/watch?v=cDCWZ-9ugYM
- First Unique Character in a string: https://www.youtube.com/watch?v=vCB_0cFQr5o
8.2. Vector: 強化版的陣列
9. 演算法
9.1. 什麼是演算法?
演算法 (Algorithm) 是「為了解決某個問題,所遵循的一連串有限、明確、可執行的步驟」。換句話說,它是一份「解題的食譜」:給定相同的輸入,照著食譜走一定會得到相同的輸出。
一個演算法通常要滿足下列性質:
- 輸入 (Input) :有 0 個或多個明確定義的輸入。
- 輸出 (Output) :至少產生一個輸出。
- 明確性 (Definiteness) :每一個步驟都必須清楚、不能模稜兩可。
- 有限性 (Finiteness) :演算法一定要在有限步驟內結束。
- 可執行性 (Effectiveness) :每個步驟都可以用基本運算實際完成。
我們之前已經寫過不少演算法了——氣泡排序、選擇排序、插入排序都是;判斷質數、求最大公因數、把一串文字反過來印出來也是。 寫程式 = 用程式語言把演算法表達出來 。
9.2. 為什麼要研究演算法?
同一個問題往往有很多種解法,但效率可能差非常多。以「在 100 萬筆已排序資料中找一個數字」為例:
- 用線性搜尋從頭找到尾:最壞情況要比 100 萬次。
- 用二分搜尋每次砍半:最多只要比 \(\log_2 1{,}000{,}000 \approx 20\) 次。
差距高達 五萬倍 。選對演算法,比把電腦升級還有效得多。這就是為什麼資工系的核心課程「資料結構與演算法」會被當成基本功——它決定你寫的程式跑得有多快。
衡量演算法效率,最常用的工具是 時間複雜度 (Time Complexity) ,用大 O 符號表示,例如 O(n)、O(n²)、O(log n)、O(2ⁿ) 等。前面學排序時已經接觸過這套記號。
接下來介紹兩個最基礎、但威力十足的演算法範例。
9.3. 範例一:二分搜尋 (Binary Search)
- 問題
給一個 已排序 的整數陣列,請判斷某個目標數是否在陣列中。如果在,回傳它的 index;不在則回傳 -1。
- 笨方法:線性搜尋 O(n)
從頭一個一個比對:
1: #include <iostream> 2: using namespace std; 3: 4: int linearSearch(int arr[], int n, int target) { 5: for (int i = 0; i < n; i++) { 6: if (arr[i] == target) return i; 7: } 8: return -1; 9: } 10: 11: int main() { 12: int arr[] = {1, 3, 5, 7, 9, 11, 13, 15, 17, 19}; 13: int n = 10; 14: cout << "找 11: index = " << linearSearch(arr, n, 11) << endl; 15: cout << "找 8: index = " << linearSearch(arr, n, 8) << endl; 16: return 0; 17: }
線性搜尋完全沒有用到「資料已排序」這個寶貴的資訊。
- 聰明的做法:二分搜尋 O(log n)
既然資料已排序,我們可以每次都先看 中間那一個 :
- 若中間元素 = target,找到了。
- 若中間元素 > target,答案一定在左半邊,把右邊全部丟掉。
- 若中間元素 < target,答案一定在右半邊,把左邊全部丟掉。
每比較一次,搜尋範圍就縮小一半,所以最多只需 \(\log_2 n\) 次比較。
1: #include <iostream> 2: using namespace std; 3: 4: int binarySearch(int arr[], int n, int target) { 5: int left = 0, right = n - 1; 6: while (left <= right) { 7: int mid = left + (right - left) / 2; // 避免 (left+right) 溢位 8: if (arr[mid] == target) return mid; 9: else if (arr[mid] < target) left = mid + 1; 10: else right = mid - 1; 11: } 12: return -1; 13: } 14: 15: int main() { 16: int arr[] = {1, 3, 5, 7, 9, 11, 13, 15, 17, 19}; 17: int n = 10; 18: cout << "找 11: index = " << binarySearch(arr, n, 11) << endl; 19: cout << "找 8: index = " << binarySearch(arr, n, 8) << endl; 20: return 0; 21: }
- 若中間元素 = target,找到了。
- 效率比較
n 線性搜尋 (最差) 二分搜尋 (最差) 100 100 次 7 次 10,000 10,000 次 14 次 1,000,000 1,000,000 次 20 次 1,000,000,000 10 億次 30 次 注意:二分搜尋的 前提 是資料已排序。如果只搜尋一次而資料未排序,加一個 O(n log n) 的排序也不一定划算;但如果要反覆搜尋很多次,先排序、再每次用二分搜尋就非常有利。 什麼演算法划算,要看使用情境 。
9.4. 範例二:動態規劃 (Dynamic Programming)
動態規劃 (簡稱 DP) 是一種「把大問題拆成小子問題,並且 把已經算過的子問題答案記下來,避免重複計算 」的策略。
DP 適用的問題通常有兩個特徵:
- 最佳子結構 (optimal substructure) :大問題的答案可以由小問題的答案組合出來。
- 重疊子問題 (overlapping subproblems) :同一個小問題會被反覆問到。
我們先用一個熟悉的例子——計算 n!——感受「記下來」這件事的意義,再用費氏數列看 DP 真正的威力。
- 純遞迴版的 n!
我們在遞迴章節已經寫過:
1: #include <iostream> 2: using namespace std; 3: 4: int factorial(int n) { 5: if (n <= 1) return 1; 6: return n * factorial(n - 1); 7: } 8: 9: int main() { 10: cout << "5! = " << factorial(5) << endl; 11: cout << "10! = " << factorial(10) << endl; 12: return 0; 13: }
對 單次呼叫 來說,這已經是 O(n) 的解法,沒有重複計算。但若我們要算 1! 到 100! 全部印出來,每次都從頭乘一遍,總共會做 \(1+2+\dots+100\) 次乘法。這就有改進空間了。
- DP 版的 n! (Tabulation:用陣列由小到大算)
DP 的核心動作是 用一個表格 (陣列) 記下每個子問題的答案,之後直接查表 :
1: #include <iostream> 2: using namespace std; 3: 4: int main() { 5: const int N = 20; 6: long long dp[N + 1]; 7: dp[0] = 1; 8: for (int i = 1; i <= N; i++) { 9: dp[i] = dp[i - 1] * i; // 直接用「上一格」的答案 10: } 11: 12: for (int i = 0; i <= 10; i++) { 13: cout << i << "! = " << dp[i] << endl; 14: } 15: return 0; 16: }
特色:
- 從最小的
dp[0]開始,由小到大「往上堆」,這叫 bottom-up / tabulation 。 - 算完之後,任何 \(k!\) 都是 O(1) 查表 ,不需要重算。
- 整張表只算一次,總時間是 O(N)。
對 n! 來說 DP 的優勢主要展現在「反覆查詢」的情境。要看到 DP 真正能把指數變線性的威力,得換另一個例子。
- 從最小的
- DP 真正的威力:費氏數列
費氏數列 F(n) = F(n-1) + F(n-2) 的純遞迴版我們也寫過:
int fib(int n) { if (n < 2) return n; return fib(n - 1) + fib(n - 2); }
這版的時間複雜度是 O(2ⁿ) ——算 fib(40) 你會等到天荒地老。為什麼?因為它把同一個子問題算了非常多次:
fib(5) / \ fib(4) fib(3) / \ / \ fib(3) fib(2) fib(2) fib(1) ... ... ...fib(3) 被算了 2 次、fib(2) 被算了 3 次、越往下重複越多。這就是典型的「重疊子問題」。
DP 版只要把算過的答案記下來:
1: #include <iostream> 2: using namespace std; 3: 4: int main() { 5: const int N = 45; 6: long long dp[N + 1]; 7: dp[0] = 0; 8: dp[1] = 1; 9: for (int i = 2; i <= N; i++) { 10: dp[i] = dp[i - 1] + dp[i - 2]; // 每個子問題只算一次 11: } 12: cout << "F(40) = " << dp[40] << endl; 13: cout << "F(45) = " << dp[45] << endl; 14: return 0; 15: }
時間複雜度從 O(2ⁿ) → O(n) ,差距是 指數級 的。在 n=40 時:
- 純遞迴:約 \(2^{40} \approx 10^{12}\) 次運算,現代電腦也要跑數十秒甚至更久。
- DP:40 次運算,瞬間完成。
- 純遞迴:約 \(2^{40} \approx 10^{12}\) 次運算,現代電腦也要跑數十秒甚至更久。
- 兩種 DP 寫法
寫法 走向 實作 Tabulation (表格法) bottom-up for 迴圈 Memoization (記憶化) top-down + 快取 遞迴 + 陣列 兩者本質都是「子問題答案算過就記下來」,差別只在計算順序與寫法。Memoization 版的費氏:
long long memo[50]; // 全部初始化為 -1 long long fib(int n) { if (n < 2) return n; if (memo[n] != -1) return memo[n]; // 查過了直接回 return memo[n] = fib(n - 1) + fib(n - 2); // 算完存起來 }
DP 是後續演算法學習的大魔王之一,從找零錢、背包問題、最長共同子序列 (LCS),到許多競賽題、面試題都會用到。打好基礎後再回來練 LeetCode 上的 DP 題會非常有感。
9.5. 其他常見演算法主題
- 排序 (Sorting) :已在本文件最前面介紹氣泡、選擇、插入;之後還會接觸到 Merge Sort、Quick Sort、堆積排序等 O(n log n) 演算法。
- 分治法 (Divide and Conquer) :把問題切成獨立的小問題分別解決後合併,例如 Merge Sort、二分搜尋本質上也是分治。
- 貪婪法 (Greedy) :每一步都做「當下看起來最好」的選擇。簡單但不一定正確,要小心驗證。
- 回溯法 (Backtracking) :用遞迴窮舉所有可能,配合剪枝避免無效搜尋。例如 N 皇后、數獨。
- 隨機演算法 (Randomized Algorithm) :刻意引入隨機性以獲得期望上的好效能或好答案,例如隨機快排、Majority Element 的隨機解。
10. LeeCode
- 【C 語言的 LeetCode 五月挑戰】第六天 (Majority Element)
- brute force: for-for
- random
- sort
- hashtable
- divide and conquer
- brute force: for-for
- 【C 語言的 LeetCode 五月挑戰】第七天 (Cousins in Binary Tree)
- Binary tree
- coutn tree depth
- Binary tree
- 【C 語言的 LeetCode 五月挑戰】第八天 (Check If It Is a Straight Line)
- 【C 語言的 LeetCode 五月挑戰】第三天 (Ransom Note)
- 1d Array
- 宇元計數與比對
- 1d Array