理財達人競賽
Table of Contents

1. 理財達人競賽#1:回到過去
1.1. 背景
正所謂「你不理財、財不離開你」,啊不是,是「你不理財、財不理你」。很多提早實現財富自由的人都是以定期定額的方式達成目標的。有沒有想過,如果你從小六開始,連續六年每個月固定投入一筆金額到某個項目中,到現在的損益狀況會是如何呢?
為了提高各組同學的參與興趣,我打算提供每組以下資源:
- 時光機一部
- 虛擬貨幣 144,000: 6 年*12 個月*每個月 2000
現在,你和你的組員可以乘坐時光機回到六年前,將每個月的 2000 元分成兩筆(每筆 1000 元),各自選擇兩種投資商品,然後以試算表來計算貴組六年來的損益情形。也許你會發現,即使這六年中歷經了武漢肺炎+俄烏戰爭,只要選擇夠好的投資標的,你仍然能從這種定期定額的懶人投資法中獲取龐大的利潤。
如果你們在初賽結束後對這種作弊投資成果還滿意,不妨從現在開始,六年後你概碩班畢業正要進入職場,那時就有一筆不小財富囉。
1.2. 競賽目標
- 成為賺最多的人: 這表示貴組獨具慧眼,能挑選出最能賺錢的投資產品
- 成為賠最多的人: 這表示貴組具有放空潛力,以後大家要投資跟貴組反著做就對了
1.3. 競賽規則
1.3.1. 投資期限
2018 年 1 月 1 日 至 2023 年 12 月 31 日
1.3.2. 投資規則說明
- 分兩種投資項目,每個項目每月投入 1000 元
- 兩種投資項目中需包含至少一檔台股
- 股票若有配股配息一律併入下月購買資金,只要基於真實數據均可列入計算(各股配息資訊需自行搜尋)
- 假設所有股票均提供零股買賣,且零股可以小數點買進(現實中股票最低買賣單位為 1 股)
- 假設零股交易價格與一般交易相同(現實中零股買賣價格不同於市價)
- 選擇其他投資商品如基金、期貨、選擇權、政府公債者需請自行研究獲利計算規則
- 為了符合懶人定期定額投資法則,六年中只能於每月 第一個交易日 買進投資商品(不可短進短出)
- 六年中只定期買進,不進行賣出
- 不考慮手續費、證交稅等額外因素
- 只能選擇可持續交易六年之投資商品(即六年內未下市的投資產品)
1.4. 小組任務
1.4.1. 研究投資標的:
- 小組討論投資項目
- 上傳投資計劃至 Padlet,格式不拘,可以是一個 Padlet mind map、一張圖表、一個完整的 PDF/word 檔、或是兩三段文字說明
1.4.2. 搜尋資料: Google
- 收集六年中計算每月累計資金所需資訊
1.4.3. 計算投報率:Excel / Google sheet
- 計算每項獲利
製表(範例如下)
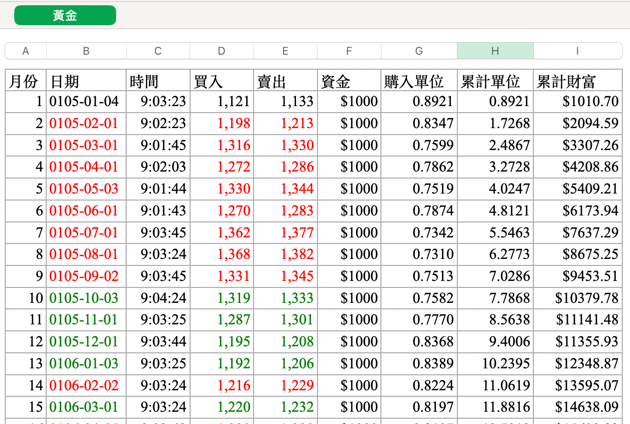
Figure 1: 黃金投資記錄
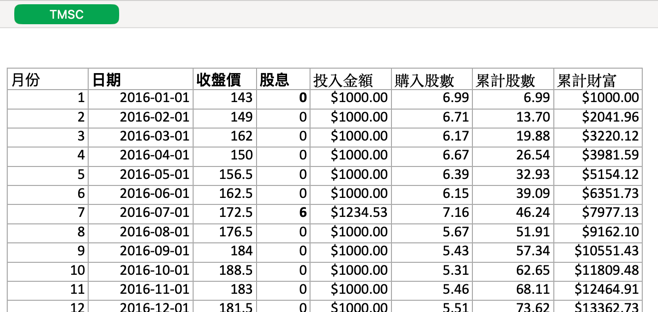
Figure 2: 股票投資記錄
1.4.4. 資料視覺化: Google Colab + Python / Excel
- 合併組員數據計算全部獲利
繪圖
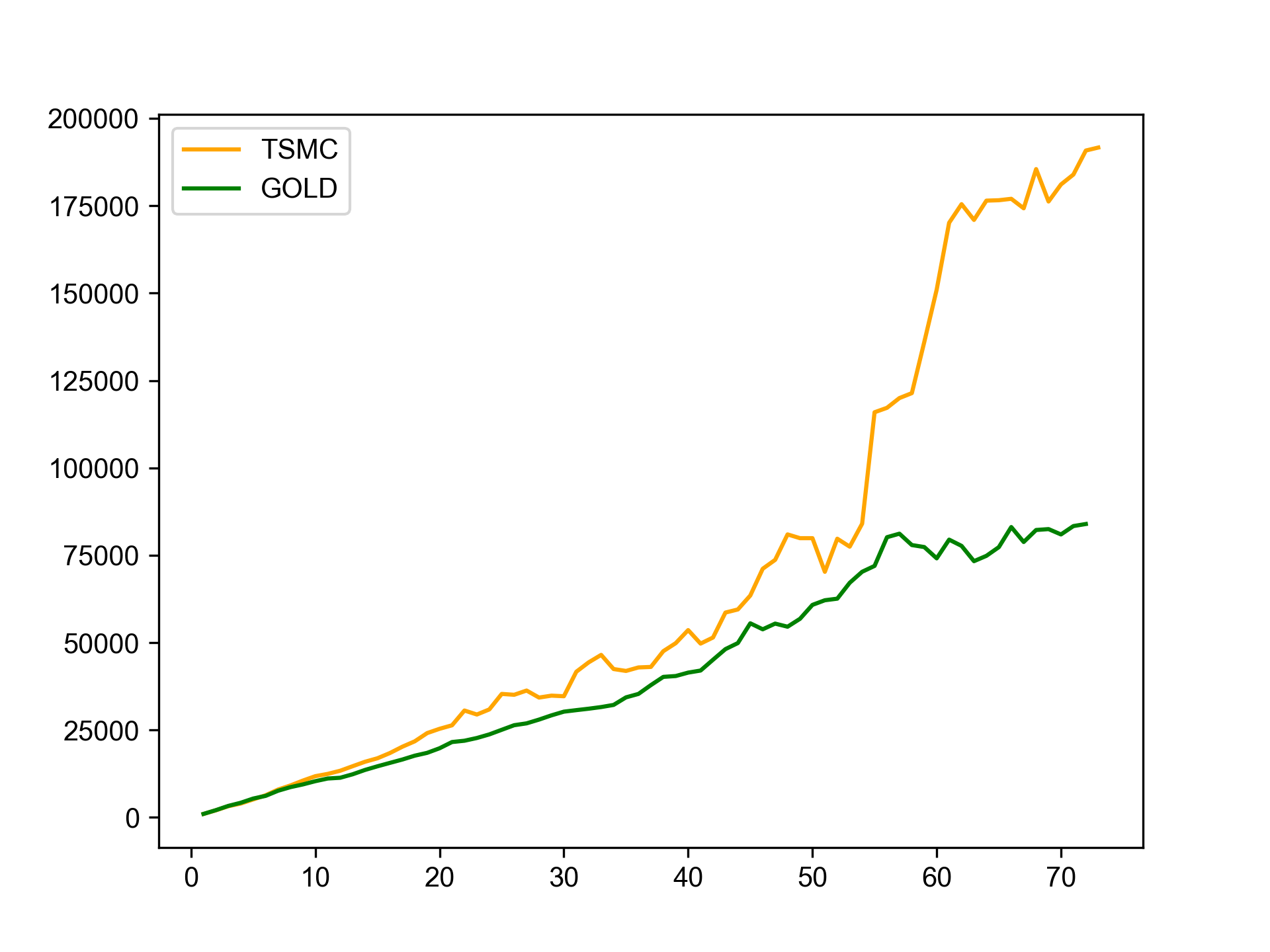
Figure 3: 投報率分析
1.6. 奬品
1.6.1. 正投報率冠軍小組:
- 期末成績+5
SNIKERS*2

1.6.2. 負投報率冠軍小組:
- 組員期末成績+3
SNIKERS*1
1.7. 關於分組
好像還有很多同學是自己一組,為了降低你的負擔,建議還是找好合作組員,後續許多作業或競賽仍是以組為單位,沒作業就沒有學期成績哦….
2. 理財達人競賽#2:卷積出你的財富(CNN)
2.1. 背景
回到過去的競賽雖然讓人很有成就感,但畢竟不現實,預測未來還是比較有利可圖,那麼,理財達人競賽 PART 2 正式開始。
2.2. 小組任務
在上週的課程中,我們示範了如何利用卷積神經網路來進行股價預測實作,雖然成效有限,但至少是個開始,現在,要請貴組動手打造你們的預測模型。
探究預測失準的原因,也許可能大概的因素有
- 參考資料不夠: 就是特徵值太少,畢竟我們只拿每日收盤價價來當成唯一的特徵值
- 預測天數: 是拿 5 天或 10 天或 50 天當成基礎來預測下一天會更合理?
- 訓練集與測試集的比例: 如何調整?
- epoch: 多訓練幾回效回會好一點嗎?
- 模型架構: 如何調整,有哪些 layer 可以玩
- 資料標準化
請貴小組開個會討論一下,然後利用 90 分鐘(包含資料蒐集、模型建置、模型訓練) 建好你們的模型,為節省訓練時間,你們可以每個組員分頭訓練不同的模型架構,比較一下不同模型的預測能力。
最終,你的模型要能做到這件事:
- 輸入某支股票代號(教師等一下會公佈)
- 輸出這支股票未來五天的股價預測結果(各組要實際 DEMO 執行預測回報股價)
2.3. 競賽規則
2.3.1. 預測對象
待公佈
2.3.2. 預測日期
2024 年 5 月 13 日 至 2024 年 5 月 17 日
2.3.3. 評分準則
- 計算五天中每組預測股價與當日收盤價之差異
- 逐日統計各組 RMSE
- 逐日公佈即時競賽狀況
2.3.4. 各組得分計算
- 以各組 RMSE 值反向排名
- 第 1 組 100 分
- 第 2 組 95 分
- 第 3 組 90 分
- 第 4 組 85 分
- 第 5 組 80 分
- 其餘各組得分依此類推
2.4. 小組成果
各組成績以下列簡陃程式計算並以圖表呈現,每日台股收盤後由教師手動更新
1: import numpy as np 2: import math 3: import matplotlib.pyplot as plt 4: # 資料設定 5: x = ['5/13', '5/14', '5/15', '5/16', '5/17'] 6: targ = [107.50, 107.50, 108.50, 110, 108] 7: groups = { 8: '第1組': [105.1712, 108.3763, 101.7562, 105.2869, 108.5946], 9: '第3組': [114.5000, 120.0000, 113.5000, 118.0000, 110.0148], 10: '第4組': [105.07, 104.30, 103.73, 103.17, 102.61], 11: '第5組': [109, 114, 120, 113, 118], 12: '第7組': [93.9930, 93.9738, 93.6052, 93.6210, 93.3136], 13: '第9組': [112.55,116.03,118.13,121.25,123.14], 14: # '第10組': [3207, 3207, 3207, 3207, 3207], 這組差太多,圖畫出來各組會失真 15: '第12組': [101.9411, 101.5433, 101.5148, 101.7162, 101.3434] 16: 17: } 18: 19: # 中文字型 20: plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] 21: plt.rcParams['axes.unicode_minus'] = False 22: 23: # 繪製折線圖 24: plt.figure(figsize=(8, 6)) 25: for group, data in groups.items(): 26: plt.plot(x, data, linestyle='--', linewidth=2, label=group) 27: plt.plot(x, targ, color='black', linestyle='-', linewidth=3, label='實際股價') 28: plt.xlabel('日期', fontsize=16) 29: plt.ylabel('股價', fontsize=16) 30: plt.legend() 31: 32: plt.xticks(rotation=45) 33: plt.savefig('images/2024-pred-result1.png', dpi=300) 34: 35: # RMSE 36: diffs = {group: math.sqrt(sum((x - y) ** 2 for x, y in zip(targ, data)) / 5) for group, data in groups.items()} 37: 38: # 排多 39: sorted_groups = dict(sorted(diffs.items(), key=lambda item: item[1])) 40: 41: colors = plt.cm.viridis(np.linspace(0, 1, len(groups))) 42: # bar chart 43: plt.figure(figsize=(8, 6)) 44: bars = plt.barh(list(sorted_groups.keys()), list(sorted_groups.values()), align='center', alpha=0.7, color=colors) 45: plt.xlabel('RMSE') 46: 47: # 加名次 48: for bar, rank in zip(bars, range(1, len(groups)+1)): 49: plt.text(bar.get_width(), bar.get_y() + bar.get_height()/2, f'第{rank}名', va='center') 50: 51: plt.savefig('images/2024-pred-result-2.png', dpi=300)
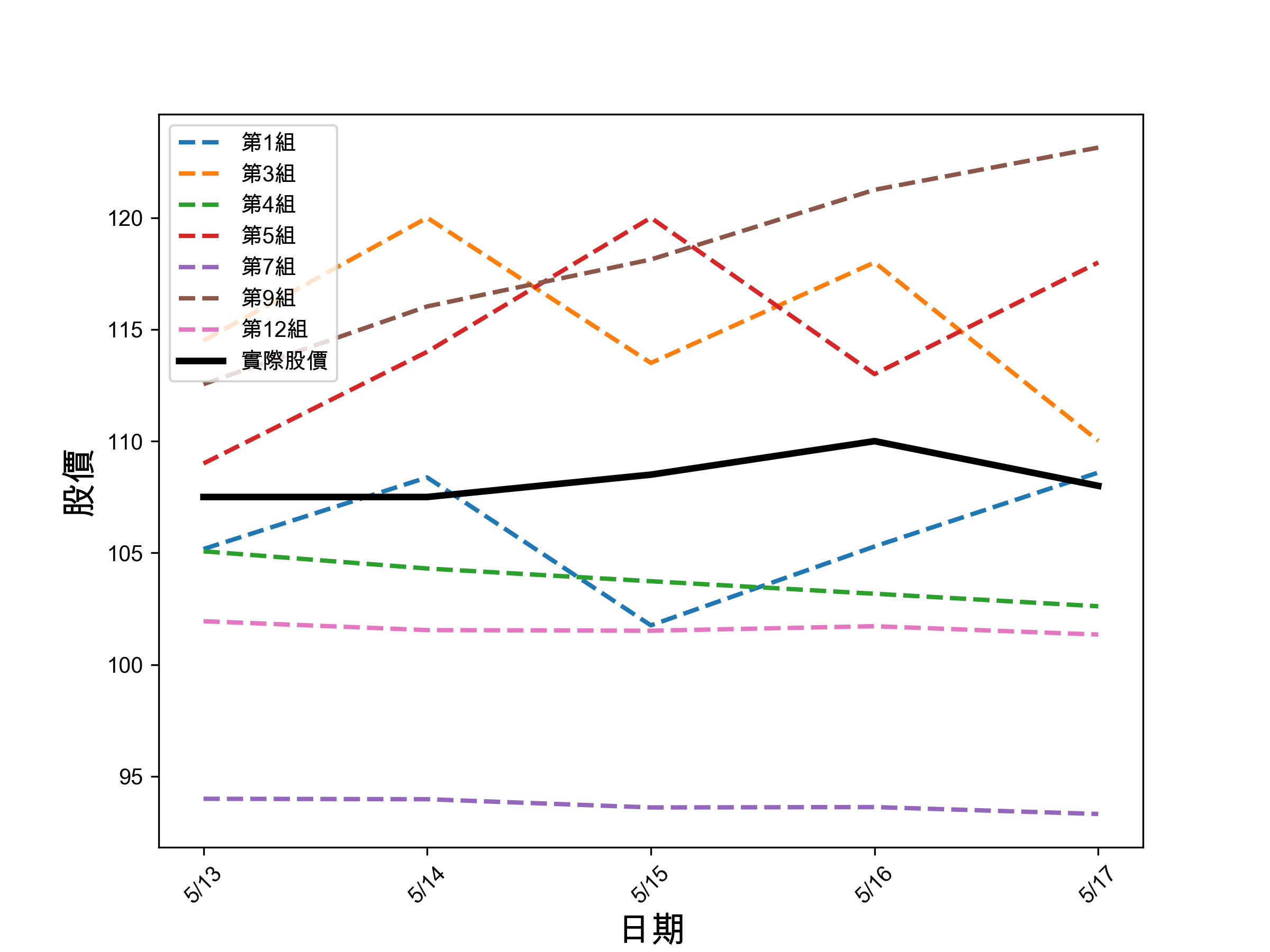
Figure 4: CNN 各組股價預測
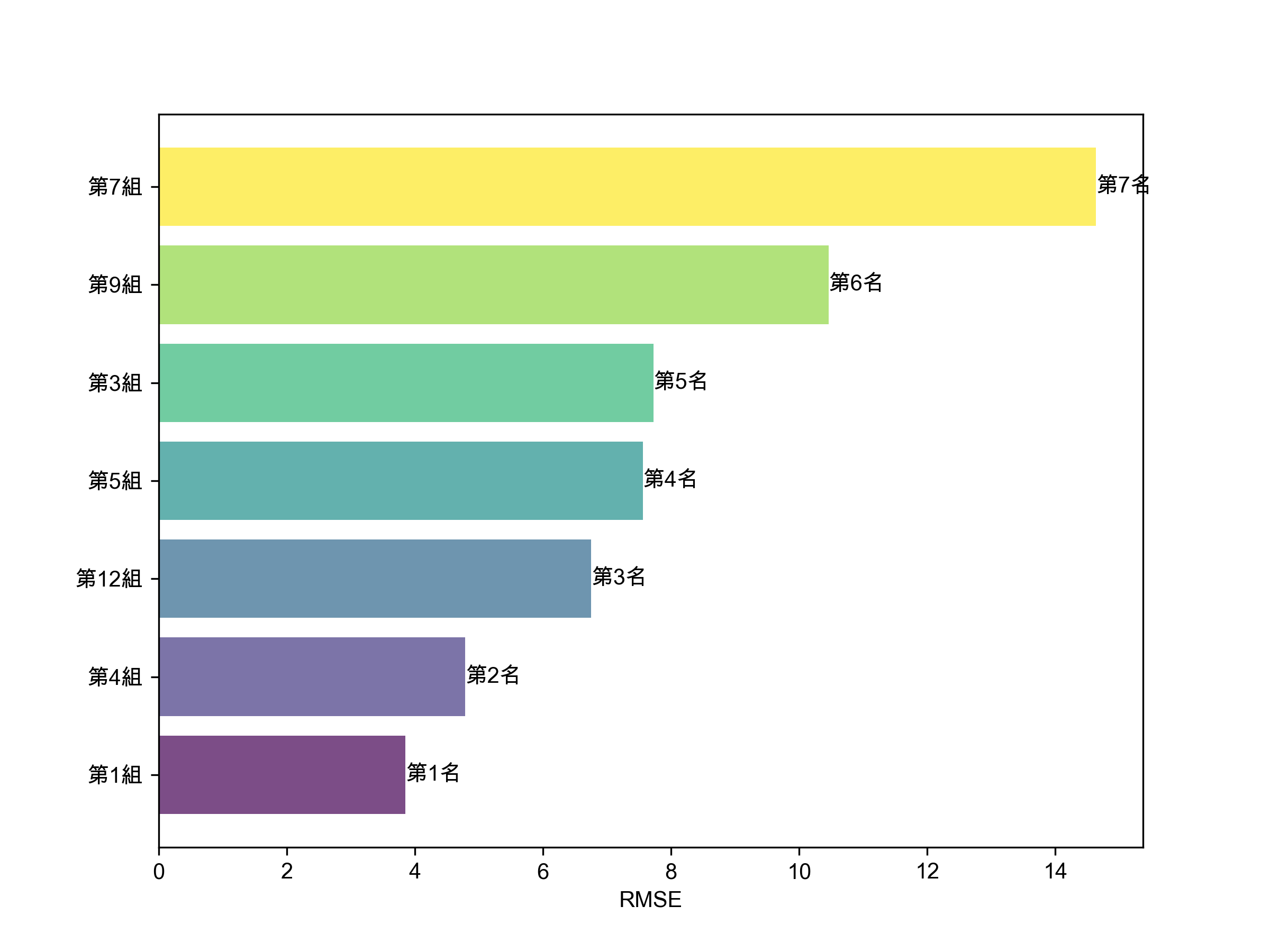
Figure 5: CNN 各組預測精確程度排名
3. 理財達人競賽#3:記憶出你的財富(LSTM)
一切背景規則同理財達人競賽#2,這次使用時間序列相關的模型,你們可以用 RNN、LSTM 或是自己去研究一下 GRU 怎麼玩
3.1. 小組成果
各組成績以下列簡陃程式計算並以圖表呈現,每日台股收盤後由教師手動更新
1: import matplotlib.pyplot as plt 2: import numpy as np 3: import math 4: 5: # 資料設定 6: x = ['5/13', '5/14', '5/15', '5/16', '5/17'] 7: targ = [107.50, 107.50, 108.50, 110, 108] 8: groups = { 9: '曾冠瑋': [116.6510, 115.4949, 114.1296, 112.8014, 111.5725], 10: '第1組': [100.4786, 100.2301, 100.4846, 99.9666, 100.1632], 11: '第3組': [102.7566, 103.1368, 101.1603, 96.9089, 96.2285], 12: '第7組': [99.7970, 99.5915, 99.4426, 99.3627, 99.2382], 13: '第9組': [60.2819, 61.4160, 61.5905, 62.8991, 63.8587], 14: '第13組': [63.98398 ,63.7081 ,63.010 ,62.5587, 62.6470] 15: } 16: 17: # 中文字型 18: plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] 19: plt.rcParams['axes.unicode_minus'] = False 20: 21: # 繪製折線圖 22: plt.figure(figsize=(8, 6)) 23: for group, data in groups.items(): 24: plt.plot(x, data, linestyle='--', linewidth=2, label=group) 25: plt.plot(x, targ, color='black', linestyle='-', linewidth=3, label='實際股價') 26: plt.xlabel('日期', fontsize=16) 27: plt.ylabel('股價', fontsize=16) 28: plt.legend() 29: plt.xticks(rotation=45) 30: plt.savefig('images/2024-pred-result-LSTM.png', dpi=300) 31: 32: # RMSE 33: diffs = {group: math.sqrt(sum((x - y) ** 2 for x, y in zip(targ, data)) / 5) for group, data in groups.items()} 34: 35: # 排多 36: sorted_groups = dict(sorted(diffs.items(), key=lambda item: item[1])) 37: 38: colors = plt.cm.viridis(np.linspace(0, 1, len(groups))) 39: # bar chart 40: plt.figure(figsize=(8, 6)) 41: bars = plt.barh(list(sorted_groups.keys()), list(sorted_groups.values()), align='center', alpha=0.7, color=colors) 42: plt.xlabel('RMSE') 43: 44: # 加名次 45: for bar, rank in zip(bars, range(1, len(groups)+1)): 46: plt.text(bar.get_width(), bar.get_y() + bar.get_height()/2, f'第{rank}名', va='center') 47: 48: plt.savefig('images/2024-pred-result-LSTM-2.png', dpi=300)
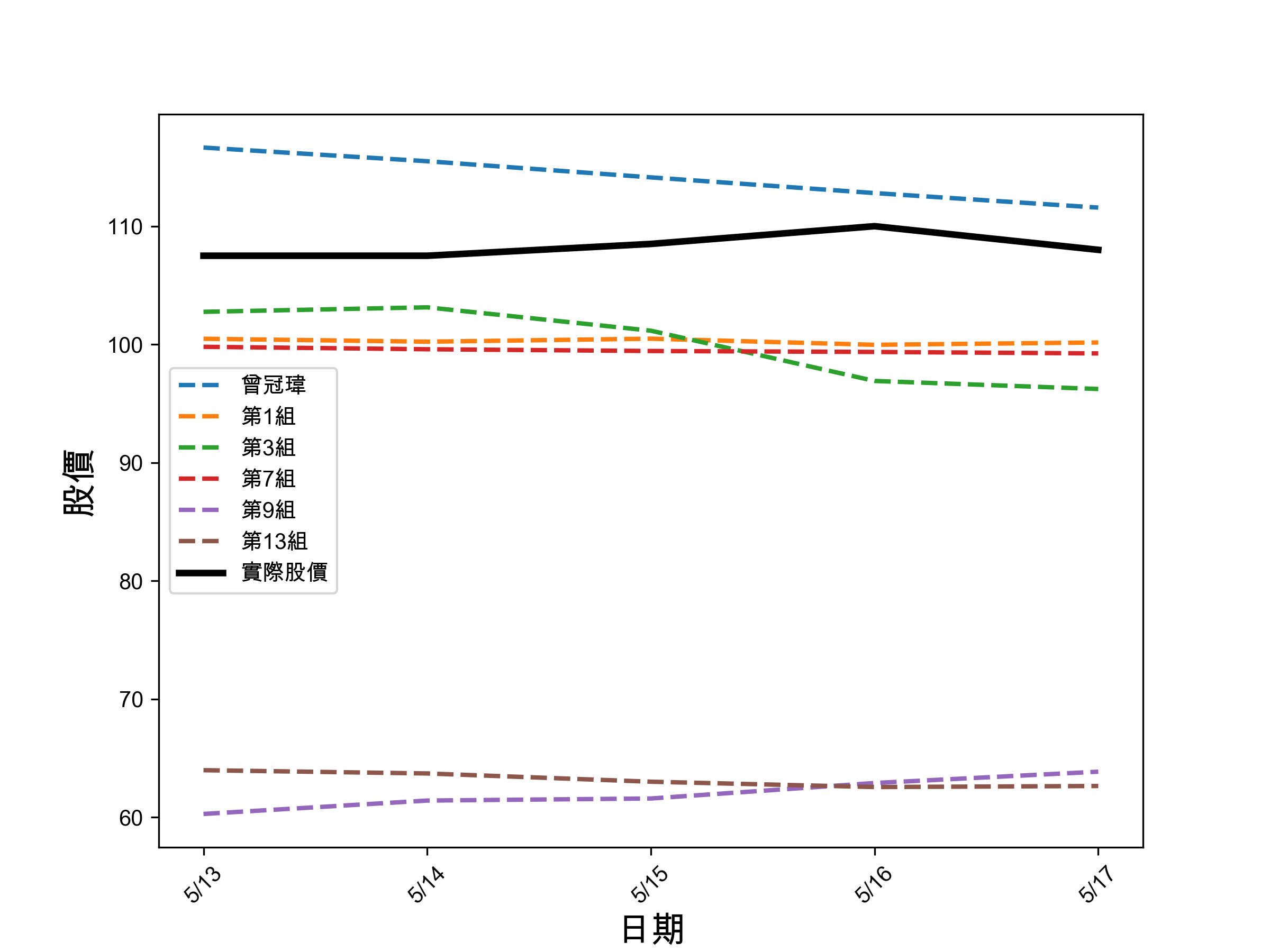
Figure 6: LSTM 各組股價預測
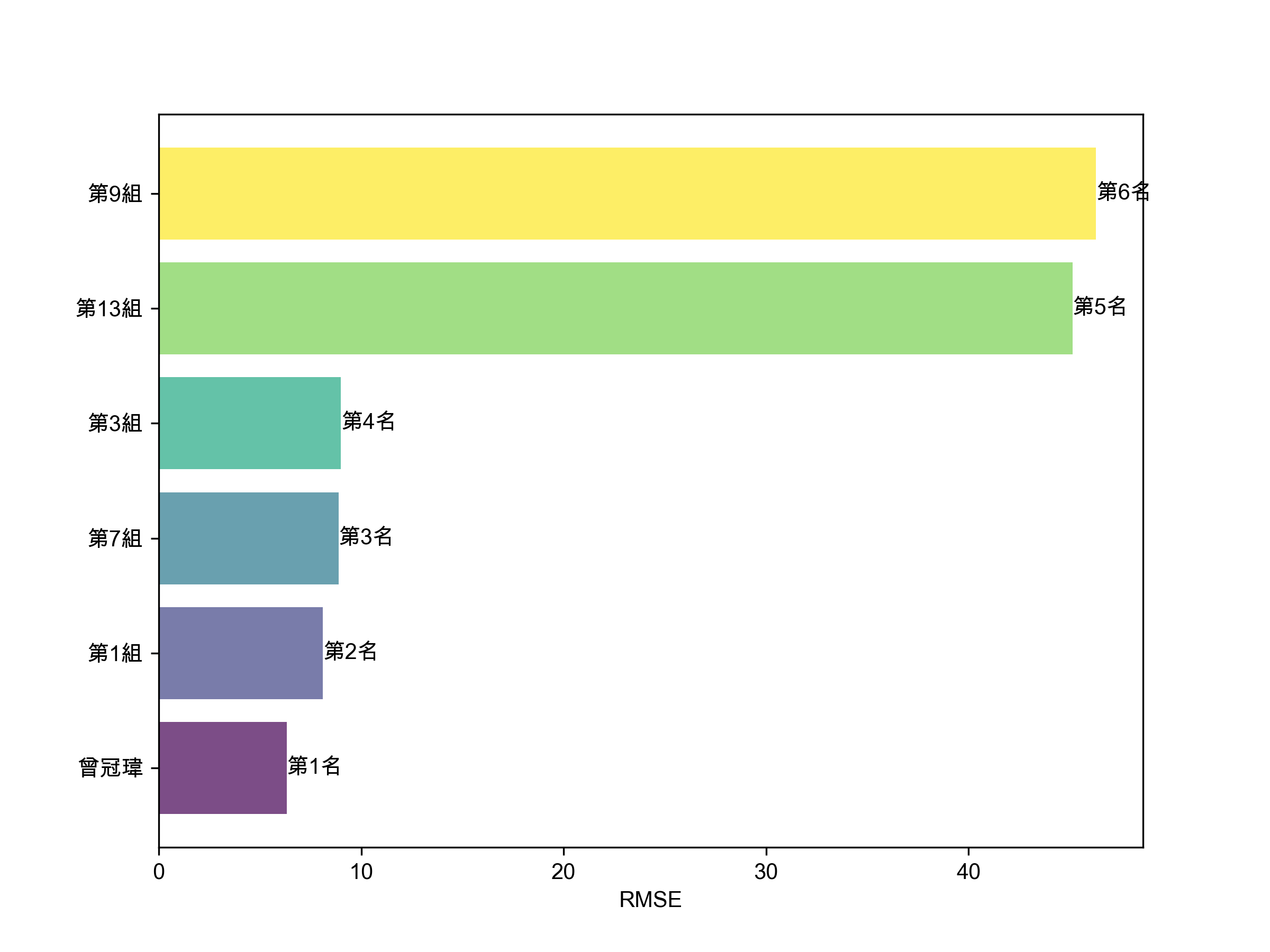
Figure 7: LSTM 各組預測精確程度排名