感知器
Table of Contents

1. 感知器(Perceptron)
1.1. 何謂感知器
Perceptron is a single layer neural network and a multi-layer perceptron is called Neural Networks(神經網路).
收到多個輸入訊號之後,再當作一個訊號輸出,如圖1所示,\(x_1, x_2\)為輸入訊號,\(y\)為輸出訊號,\(w_1, w_2\)代表權重(weight),圖中的圓圈稱為「神經元」或稱作「節點」。神經元\(x_1, x_2\)的訊號是否會觸發神經元\(y\)使其輸出訊號則取決於\(w_1x_1+w_2x_2\)是否會超過某個臨界值\(\theta\)。
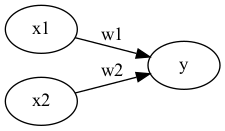
Figure 1: 收到兩組輸入訊號的感知器
若以算式表示此一觸發條件則如公式\eqref{org6540b90}所示。
\begin{equation} \label{org6540b90} y = \begin{cases} 0, & w_1x_1+w_2x_2 \leq 0 \\ 1, & w_1x_1 + w_2x_2 > 0 \end{cases} \end{equation}1.2. 感知器工作原理
1.2.1. Version #1: 使用weight
感知器(perceptron)是人造神經元(artificial neuron)的一種,也是最基本的一種。它接受一些輸入,產生一個輸出。
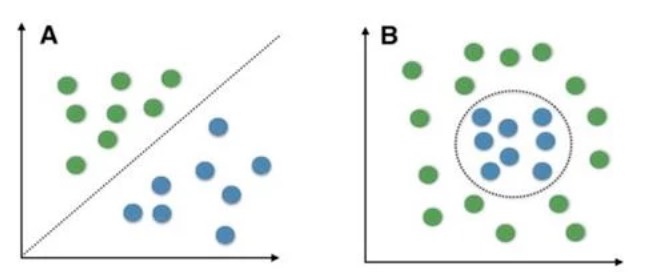
 所謂「線性」,簡單來說就是「用一條直線(在二維平面上)或一個平面(在三維空間中)來切分資料」。如果資料可以被一條直線完美地分成兩群,就稱為「線性可分」。這種架構有以下限制:
所謂「線性」,簡單來說就是「用一條直線(在二維平面上)或一個平面(在三維空間中)來切分資料」。如果資料可以被一條直線完美地分成兩群,就稱為「線性可分」。這種架構有以下限制:
- 這種架構的輸入/輸出關係為線性
- 神經網路中再多的線性perceptron疊加,結果等同於一條線,仍為線性
- 因此無法解決 線性不可分 的問題(也就是無法處理一條直線分不開的資料)
線性可分 v.s. 線性不可分
低維映射至高維
可以透過一個非線性的映射將低維空間線性不可分的樣本轉換至高維空間,使其成為線性可分2,例如:
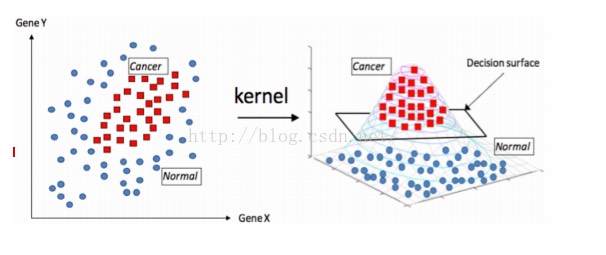
Figure 3: Kernel function mapping
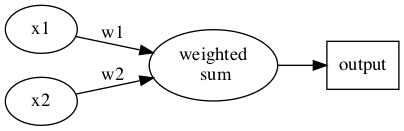
1.2.2. Version #2: 加入bias
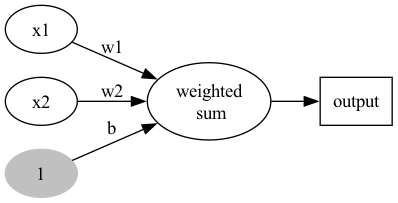
Figure 4: Perceptron version 2
- 不加 bias 你的分類線(面)就必須過原點,這顯然是不靈活的
- 透過bias,可以將NN進行左右調整,以適應(fit)更多情況
- 可以將bias視為一個activate perceptron的threshold
- bias也可以視為當輸入均為0時的輸出值
- 從仿生學的角度,刺激生物神經元使它興奮需要刺激強度超過一定的閾值,同樣神經元模型也仿照這點設置了bias
1.2.3. Version #3: 加入activation function
加入activation function,至於為什麼要加這個,請直接看下一節的Story of gate。
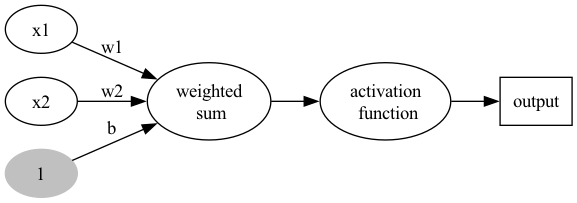
Figure 5: Perceptron version 3
1.3. 能做什麼
目前為止,感知器看起來就是個函數,有輸入、有處理、有輸出,這和AI有什麼關係呢?感知器能解決什麼問題?
感知器可以做最簡單的 二元分類 ——也就是把資料分成兩群。例如,給定輸入後判斷「是」或「否」、「通過」或「不通過」。最經典的例子就是用感知器來實現邏輯閘(AND、OR、NAND),這些邏輯閘的輸出只有 0 和 1,正好就是一種二元分類問題。接下來我們就用邏輯閘來實際體驗感知器的威力!
2. Story of gate: From perceptron to MLP
接下來我們用最簡單的邏輯閘來示範感知器的實際運作——邏輯閘的輸入只有 0 和 1,非常適合驗證感知器是否能正確分類。
2.1. OR gate實作
圖6中有四筆資料,有三個A、一個B,如何進行分類?
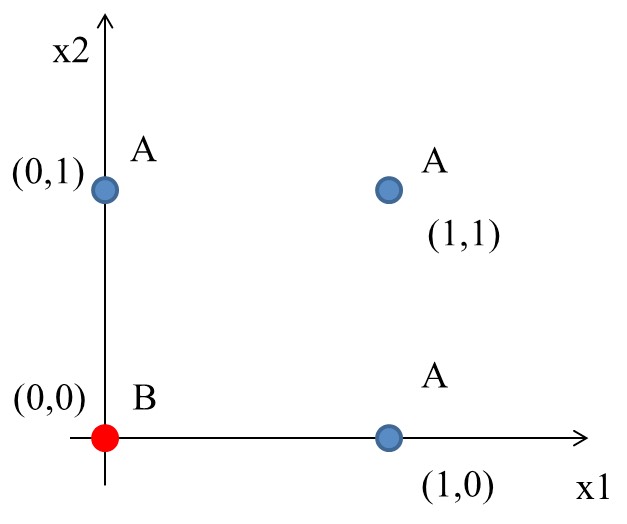
Figure 6: 分類任務:問題
2.1.1. 想法
最簡單的分類方式是在A和B中間直接找條直線(\(w_1x_1+w_2x_2+b=0\))就可以將A和B完整切出兩個區塊,然後再搭配階梯函數(step function)將>0與<=0分別設為1與0,用來代表類別0與1。該直線方程式如下:
\begin{equation} \label{org4e63280} y = \begin{cases} 1, & w_1x_1 + w_2x_2-b>0 \\ 0, & w_1x_1 + w_2x_2-b\leq0 \\ \end{cases} \end{equation}2.1.2. Solution
經過無數的嚐試錯誤,也許我們可以矇到一個如下的方程式
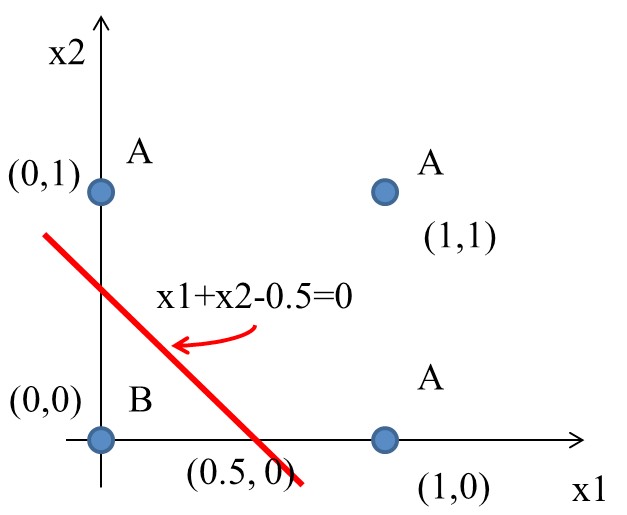
Figure 7: 分類任務:Solution
如果畫成Perceptron(version 3)的圖:
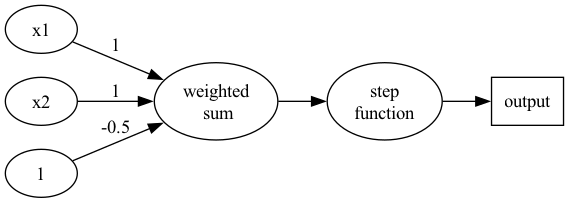
Figure 8: Perceptron presentation
如果將圖7的四個點代入y(方程式\eqref{org4e63280}):
\begin{align*} A(0,1) \rightarrow y &= f(0,1) = f(1\times0+1\times1-0.5) = f(0.5) = 1 \\ A(1,0) \rightarrow y &= f(1,0) = f(1\times1+1\times0-0.5) = f(0.5) = 1\\ A(1,1) \rightarrow y &= f(1,1) = f(1\times1+1\times1-0.5) = f(1.5) = 1\\ B(0,0) \rightarrow y &= f(0,0) = f(1\times0+1\times0-0.5) = f(-0.5) = 0\\ \end{align*}2.1.3. OR gate
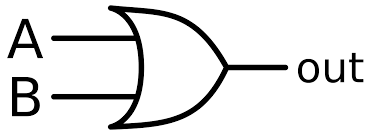
2.1.4. Python實作
上述 OR gate的python實作如下
1: import numpy as np # 匯入 numpy,它是 Python 的數學神器,處理陣列運算超方便 2: 3: # 階梯函數(step function):輸入 >= 0 就回傳 1,否則回傳 0 4: # 就像一個超嚴格的門衛:夠格就放行(1),不夠格就滾(0) 5: def step_function(x): 6: return np.array(x >= 0, dtype=int) 7: 8: # OR 感知器:模擬 OR 邏輯閘 9: # 只要有一個輸入是 1,就輸出 1(像「有沒有帶錢或帶卡?有一個就能買飲料」) 10: def OR(x1, x2): 11: x = np.array([x1, x2]) # 把兩個輸入包成一個陣列 12: w = np.array([1, 1]) # 權重:兩個輸入同等重要,各給 1 13: b = -0.5 # 偏移值(門檻):加權總和要超過 0.5 才算「過關」 14: y = np.sum(w*x) + b # 計算加權總和:w1*x1 + w2*x2 + b 15: return step_function(y) # 丟給階梯函數,決定最終輸出 0 或 1 16: 17: # 測試所有可能的輸入組合,驗證是否符合 OR 真值表 18: print("0 OR 0 -> ", OR(0,0)) # 0+0-0.5 = -0.5 < 0 → 輸出 0 ✓ 19: print("0 OR 1 -> ", OR(0,1)) # 0+1-0.5 = 0.5 > 0 → 輸出 1 ✓ 20: print("1 OR 0 -> ", OR(1,0)) # 1+0-0.5 = 0.5 > 0 → 輸出 1 ✓ 21: print("1 OR 1 -> ", OR(1,1)) # 1+1-0.5 = 1.5 > 0 → 輸出 1 ✓
0 OR 0 -> 0 0 OR 1 -> 1 1 OR 0 -> 1 1 OR 1 -> 1
2.2. [課堂作業]AND、NAND Gate實作 TNFSH
上述範例中,我們以瞎貓精神找出了一組solution解決了OR gate的分類問題,請比照辦理,以Python實作出以下兩個gate: AND, NAND。
2.2.1. AND
已知AND gate真值表如下
| A | B | A AND B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
請仿照上面 OR gate 的程式碼,修改 w 和 b 來實作 AND gate。
提示:AND 要求兩個輸入都是 1 才輸出 1,所以門檻要比 OR 高。
1: import numpy as np # 匯入 numpy 2: 3: # 階梯函數:老朋友了,>= 0 就輸出 1,否則 0 4: def step_function(x): 5: return np.array(x >= 0, dtype=int) 6: 7: # AND 感知器:兩個輸入都是 1 才輸出 1(像「要帶錢而且帶卡才能刷」) 8: def AND(x1, x2): 9: x = np.array([x1, x2]) # 把兩個輸入包成陣列 10: w = np.array([___, ___]) # 請填入權重(提示:跟 OR 一樣各 0.5 就行) 11: b = ___ # 請填入偏移值(提示:門檻要比 OR 高,想想為什麼) 12: y = np.sum(w*x) + b # 加權總和 = w1*x1 + w2*x2 + b 13: return step_function(y) # 過門檻就輸出 1,沒過就 0 14: 15: # 測試四種輸入組合,對照 AND 真值表檢查 16: print("0 AND 0 -> ", AND(0,0)) # 預期 0 17: print("0 AND 1 -> ", AND(0,1)) # 預期 0 18: print("1 AND 0 -> ", AND(1,0)) # 預期 0 19: print("1 AND 1 -> ", AND(1,1)) # 預期 1(唯一輸出 1 的情況)
正確答案(用來驗證):
0 AND 0 -> 0 0 AND 1 -> 0 1 AND 0 -> 0 1 AND 1 -> 1 一組可行的答案:w=[0.5, 0.5], b=-0.7
2.2.2. NAND
已知NAND gate真值表如下
| A | B | A NAND B |
|---|---|---|
| 0 | 0 | 1 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
請把 AND gate 的權重和偏移值「全部反過來」試試看。
1: import numpy as np # 匯入 numpy 2: 3: # 階梯函數:又是你,>= 0 → 1,< 0 → 0 4: def step_function(x): 5: return np.array(x >= 0, dtype=int) 6: 7: # NAND 感知器:AND 的相反!兩個都是 1 才輸出 0,其餘都是 1 8: # (像「兩個人都遲到才扣分,只要有一個準時就沒事」) 9: def NAND(x1, x2): 10: x = np.array([x1, x2]) # 把兩個輸入包成陣列 11: w = np.array([___, ___]) # 請填入權重(提示:把 AND 的權重「反過來」) 12: b = ___ # 偏移值也反過來 13: y = np.sum(w*x) + b # 加權總和 14: return step_function(y) # 階梯函數判定輸出 15: 16: # 測試四種輸入組合,對照 NAND 真值表 17: print("0 NAND 0 -> ", NAND(0,0)) # 預期 1 18: print("0 NAND 1 -> ", NAND(0,1)) # 預期 1 19: print("1 NAND 0 -> ", NAND(1,0)) # 預期 1 20: print("1 NAND 1 -> ", NAND(1,1)) # 預期 0(唯一輸出 0 的情況)
正確答案(用來驗證):
0 NAND 0 -> 1 0 NAND 1 -> 1 1 NAND 0 -> 1 1 NAND 1 -> 0 一組可行的答案:w=[-0.5, -0.5], b=0.7(和 AND 完全相反!)
3. 單層感知器的極限與多層感知器: XOR Gate
3.1. 一場差點殺死 AI 的學術恩怨
在講 XOR 之前,先來聽一個八點檔等級的 AI 歷史故事——因為 XOR 這個看起來人畜無害的小問題,曾經直接把整個 AI 領域打入冷宮長達十幾年。
3.1.1. 第一幕:天才登場(1957)
1957 年,美國心理學家 Frank Rosenblatt 在康乃爾大學發明了感知器,並用硬體實作出一台叫做 Mark I Perceptron 的機器(想看實機照片和內部線路?去人工智慧:Mark I Perceptron瞧瞧)——它可以「學會」辨識簡單的圖形。這在當時簡直是科幻小說成真,媒體瘋狂報導,《紐約時報》甚至寫出了這樣的標題:
「海軍展示一台能像嬰兒一樣學習的機器」——The New York Times, 1958
Rosenblatt 本人也相當樂觀,預言感知器未來能「走路、說話、看東西、寫字、自我複製,甚至意識到自己的存在」。以現在的眼光來看,這大概就像有人拿出一個計算機,然後宣布「它未來會統治世界」一樣。
3.1.2. 第二幕:殺手登場(1969)
好景不長。1969 年,MIT 的兩位大佬——Marvin Minsky 和 Seymour Papert——出版了一本叫做《Perceptrons》的書。這本書用嚴謹的數學證明了一件事:
單層感知器連 XOR 這麼簡單的問題都解不了。
就是我們接下來要看的 XOR。一個只有四筆資料、兩個輸入的問題,感知器居然搞不定。Minsky 和 Papert 的結論很殘酷:感知器只能處理「線性可分」的問題,對於稍微複雜一點的問題就束手無策。
這本書的殺傷力有多大?幾乎所有研究經費都被砍光,整個神經網路領域進入了長達十多年的寒冬(AI Winter)。學者們紛紛轉向其他方向,神經網路變成學術界的髒字眼——提到它就像在說「地球是平的」一樣丟臉。
3.1.3. 第三幕:復仇者歸來(1986)
其實 Minsky 和 Papert 的書裡有一個關鍵的「但是」被大家忽略了——他們證明的是 單層 感知器的極限,並沒有說 多層 感知器不行。
1986 年,Rumelhart、Hinton 和 Williams 提出了 *反向傳播演算法*(Backpropagation),讓多層感知器(MLP)可以有效地學習。XOR?小菜一碟。更複雜的問題?也能搞定。神經網路終於翻身,從此一路進化到今天的深度學習。
3.1.4. 這個故事告訴我們什麼?
- 一個「太簡單」的問題(XOR)可以改變整個領域的命運
- 學術界的結論常被過度簡化——「感知器不行」被誤讀成「神經網路不行」
- 被判死刑不代表真的死了,有時候只是還沒找到對的方法
接下來,就讓我們親眼看看 XOR 到底「難」在哪裡,以及多層感知器是怎麼破解它的。
3.2. XOR 問題
XOR(互斥或,Exclusive OR)是電腦科學中的一種基本邏輯運算:當兩個輸入「不同」時輸出 1,「相同」時輸出 0。看起來很簡單,但它有一個致命的特性——XOR 的四個資料點無法被任何一條直線分開。這正是單層感知器的致命弱點,也是推動多層感知器(MLP)發展的關鍵問題。
XOR真值表如下:
| A | B | A XOR B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
其輸入/輸出分佈圖為
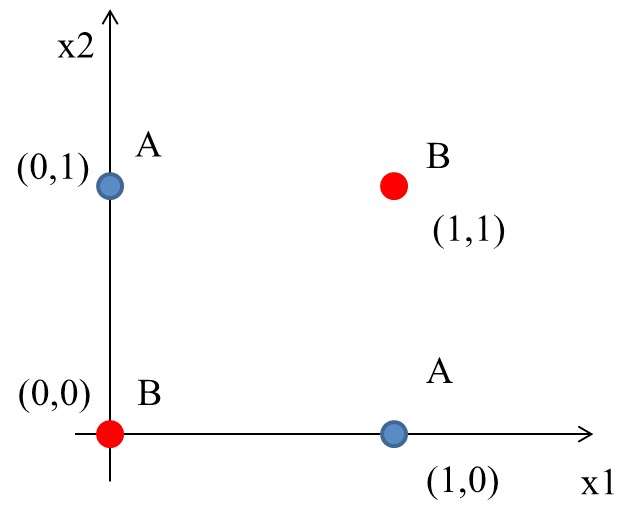
Figure 10: XOR Gate
到目前為止,透過權重及偏權值可以設計 AND、NAND、OR, 但無法完成 XOR。顯然,若要再以感知器來模擬其運作原理,單層感知器已不敷使用。
3.2.1. 想法
這個時候一般線性的分類就沒有辦法很完美分割(如下圖),所以就需要一些變形的方法來達到目的。
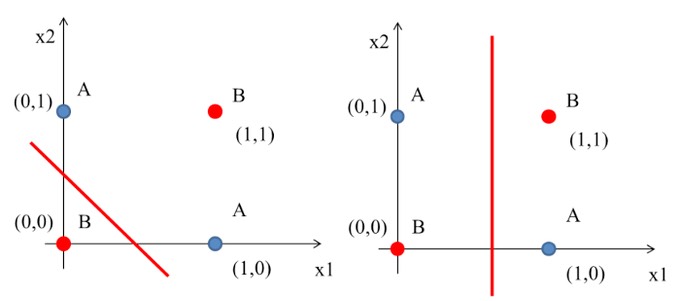
Figure 11: XOR Gate Solution ideas
一條線分不開?那就用兩條!這就是多層感知器的核心概念——當一個感知器(一條線)無法解決問題時,我們可以用多個感知器(多條線)組合起來解決。
由XOR的電路實作(如圖12)我們也可以發現同樣的原理。
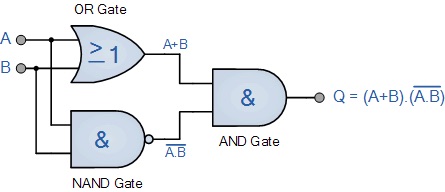
Figure 12: XOR 邏輯閘的組合
3.2.2. 多層感知器(MLP): XOR gate 實作
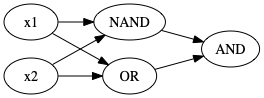
Solution
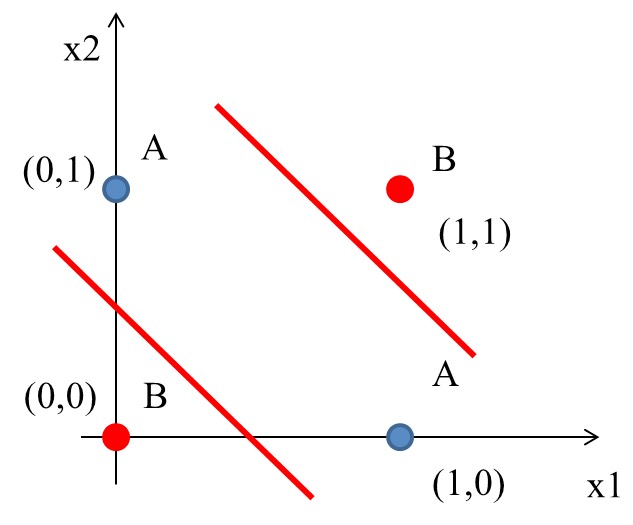
Figure 14: XOR Gate Solution: (1)
如前所述,一條線為一個perceptron,這裡會用到兩個
- \(h_1(x) = x_1 + x_2 - 0.5\)
- \(h_2(x) = x_1 + x_2 - 1.5\)
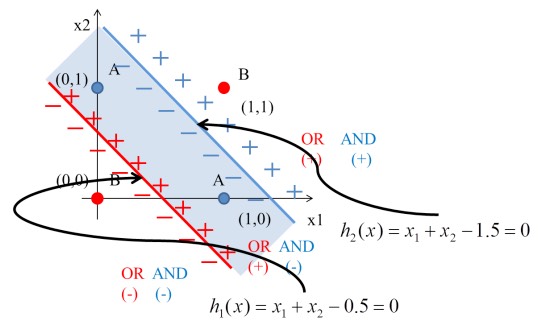
Figure 15: XOR Gate Solution: (2)
將圖11的4個點代入\(h_1\):
\begin{align*} h_1(0,0) &= f(1\times0+1\times0-0.5) = f(-0.5) = 0\\ h_1(0,1) &= f(1\times0+1\times1-0.5) = f(0.5) = 1\\ h_1(1,0) &= f(1\times1+1\times0-0.5) = f(0.5) = 1\\ h_1(1,1) &= f(1\times1+1\times1-0.5) = f(1.5) = 1\\ \end{align*}將圖11的4個點代入\(h_2\):
\begin{align*} h_2(0,0) &= f(1\times0+1\times0-1.5) = f(-1.5) = 0\\ h_2(0,1) &= f(1\times0+1\times1-1.5) = f(-0.5) = 0\\ h_2(1,0) &= f(1\times1+1\times0-1.5) = f(-0.5) = 0\\ h_2(1,1) &= f(1\times1+1\times1-1.5) = f(0.5) = 1\\ \end{align*}由上可知:
- (0, 0)
- (0, 0)帶入第1個perceptron \(h_1(0,0)\)輸出-0.5
- (0, 0)帶入第2個perceptron \(h_2(0,0)\)輸出-1.5
- (-0.5, -1.5)再經由step function轉換輸出(0,0)
- (0, 1)
- (0, 1)帶入第1個perceptron \(h_1(0,1)\)輸出0.5
- (0, 1)帶入第2個perceptron \(h_2(0,1)\)輸出-0.5
- (0.5, -0.5)再經由step function轉換輸出(1,0)
- (1, 0)
- (1, 0)帶入第1個perceptron \(h_1(1,0)\)輸出0.5
- (1, 0)帶入第2個perceptron \(h_2(1,0)\)輸出-0.5
- (0.5, -0.5)再經由step function轉換輸出(1,0)
- (1, 1)
- (1, 1)帶入第1個perceptron \(h_1(1,1)\)輸出1.5
- (1, 1)帶入第2個perceptron \(h_2(1,1)\)輸出0.5
- (1.5, 0.5)再經由step function轉換輸出(1,1)
即
\begin{align*} data(0,0) &= f(h_1,h_2) = (0,0) \\ data(0,1) &= f(h_1,h_2) = (1,0) \\ data(1,0) &= f(h_1,h_2) = (1,0) \\ data(1,1) &= f(h_1,h_2) = (1,1) \\ \end{align*}觀察轉換後的結果:原本在 \((x_1, x_2)\) 空間中,(0,0) 和 (1,1) 輸出為 0、(0,1) 和 (1,0) 輸出為 1,這四個點無法用一條直線分開。但經過隱藏層轉換到 \((h_1, h_2)\) 空間後,(0,0) 映射到 (0,0)、(0,1) 和 (1,0) 都映射到 (1,0)、(1,1) 映射到 (1,1)——此時這些點變成可以用一條直線分開了!這就是多層感知器的威力。
這相當於透過兩個perceptron將原本的輸入做特徵空間轉換,如圖16:
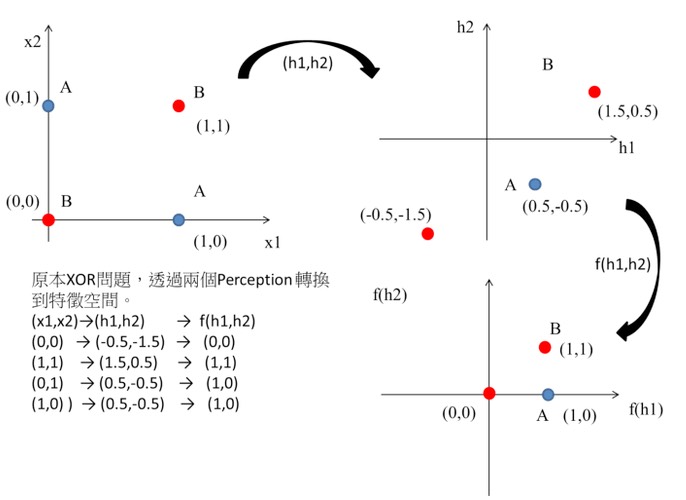
Figure 16: XOR Gate Solution: (3)
這個時候只要設計一個線性分類器就可以完美分割兩類的資料了阿,如圖17:
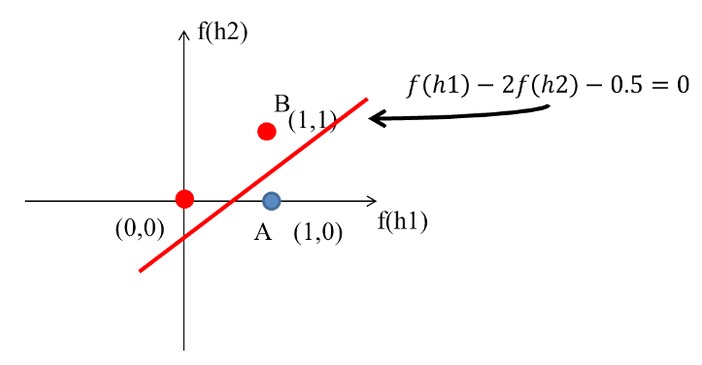
Figure 17: XOR Gate Solution: (4)
XOR問題的神經網路結構如下圖:
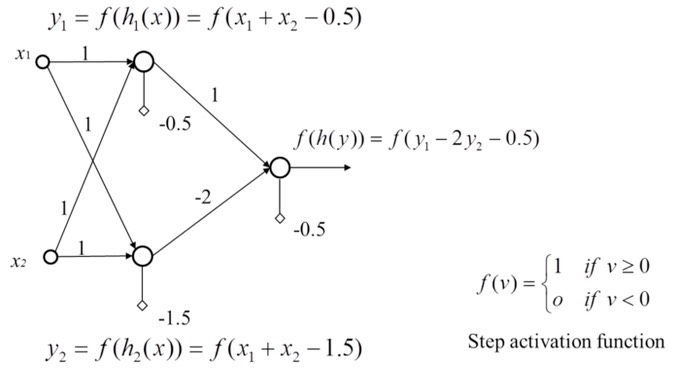
Figure 18: XOR Gate Solution: (5)
至於其實作程式碼則如下。
1: # XOR 邏輯閘模擬——用多層感知器(MLP)組合 NAND、OR、AND 來實現 2: # 這就是「一條線分不開,那就用兩條線」的具體實踐! 3: import numpy as np 4: 5: # 老朋友階梯函數:>= 0 輸出 1,否則 0 6: def step_function(x): 7: return np.array(x >= 0, dtype=int) 8: 9: # AND 感知器:兩個都是 1 才輸出 1 10: def AND(x1, x2): 11: x = np.array([x1, x2]) 12: w = np.array([0.5, 0.5]) # 權重各 0.5 13: b = -0.7 # 門檻 0.7,所以 0.5+0.5=1.0 才過關 14: return step_function(np.sum(w*x) + b) 15: 16: # OR 感知器:有一個是 1 就輸出 1 17: def OR(x1, x2): 18: x = np.array([x1, x2]) 19: w = np.array([0.5, 0.5]) # 權重各 0.5 20: b = -0.2 # 門檻只有 0.2,一個 0.5 就能過 21: return step_function(np.sum(w*x) + b) 22: 23: # NAND 感知器:AND 的相反版(權重和偏移值全部反轉) 24: def NAND(x1, x2): 25: x = np.array([x1, x2]) 26: w = np.array([-0.5, -0.5]) # 負權重:輸入越大,分數反而越低 27: b = 0.7 # 正偏移:預設就偏向輸出 1 28: return step_function(np.sum(w*x) + b) 29: 30: # XOR 感知器:重頭戲來了!組合三個閘來完成單層做不到的事 31: # 結構:x1, x2 → [NAND, OR](第一層)→ AND(第二層)→ 輸出 32: def XOR(x1, x2): 33: s1 = NAND(x1, x2) # 第一層第 1 個神經元:除了 (1,1) 以外都輸出 1 34: s2 = OR(x1, x2) # 第一層第 2 個神經元:除了 (0,0) 以外都輸出 1 35: y = AND(s1, s2) # 第二層:只有 s1 和 s2 都是 1 才輸出 1 36: return y # 最終效果:「不同」才輸出 1,跟 XOR 一模一樣! 37: 38: # 驗證所有組合 39: print("XOR(0,0): ", XOR(0,0)) # NAND=1, OR=0 → AND(1,0)=0 ✓ 40: print("XOR(0,1): ", XOR(0,1)) # NAND=1, OR=1 → AND(1,1)=1 ✓ 41: print("XOR(1,0): ", XOR(1,0)) # NAND=1, OR=1 → AND(1,1)=1 ✓ 42: print("XOR(1,1): ", XOR(1,1)) # NAND=0, OR=1 → AND(0,1)=0 ✓
XOR(0,0): 0 XOR(0,1): 1 XOR(1,0): 1 XOR(1,1): 0
4. 課堂練習 TNFSH
4.1. 練習一:AI 預測你上課會不會睡著
老師受夠了在台上講課看到一片屍體的景象。他決定在每堂課前用感知器預測誰會睡著,然後把那些人叫到第一排坐(或者直接潑水,看老師心情)。
他偷偷蒐集了 8 位同學的資料:
| 同學 | 昨晚睡幾小時 | 今天喝幾杯咖啡 | 上課狀態 |
|---|---|---|---|
| 阿明 | 8 | 2 | 清醒 |
| 小美 | 4 | 0 | 睡著 |
| 大雄 | 7 | 1 | 清醒 |
| 胖虎 | 3 | 1 | 睡著 |
| 靜香 | 6 | 2 | 清醒 |
| 小夫 | 5 | 0 | 睡著 |
| 阿福 | 4 | 2 | 清醒 |
| 魯夫 | 3 | 0 | 睡著 |
4.1.1. 範例:先用最簡單的方法試試
最直覺的做法:只看睡眠時數,忽略咖啡。如果睡超過 5.5 小時就算清醒。
1: import numpy as np # 匯入 numpy 2: 3: # 階梯函數:>= 0 輸出 1(清醒),< 0 輸出 0(睡著) 4: def step_function(x): 5: return np.array(x >= 0, dtype=int) 6: 7: # 同學資料:每列 = [昨晚睡幾小時, 今天咖啡幾杯] 8: # 8 位同學的生活作息,老師偷偷記下來的(隱私什麼的先不管了) 9: X = np.array([[8,2], [4,0], [7,1], [3,1], 10: [6,2], [5,0], [4,2], [3,0]]) 11: # 標籤(正確答案): 清醒=1, 睡著=0 12: y = np.array([1, 0, 1, 0, 1, 0, 1, 0]) 13: names = ['阿明','小美','大雄','胖虎','靜香','小夫','阿福','魯夫'] 14: 15: # 設定感知器的權重和偏移值 16: # w=[1, 0] 表示:只看睡眠時數(權重=1),完全忽略咖啡(權重=0) 17: w = np.array([1, 0]) 18: b = -5.5 # 門檻 5.5 小時(睡超過 5.5hr 才判定為清醒) 19: 20: # 逐一預測每位同學的上課狀態 21: print("預測結果(只看睡眠時數):") 22: for i in range(len(X)): 23: # np.dot(w, X[i]) + b = 1*睡眠 + 0*咖啡 - 5.5 = 睡眠 - 5.5 24: pred = step_function(np.dot(w, X[i]) + b) # 過階梯函數得到 0 或 1 25: label = '清醒' if pred == 1 else '睡著' # 把 0/1 翻譯成人話 26: correct = '○' if pred == y[i] else '×' # 跟正確答案比對 27: print(f" {names[i]}(睡{X[i][0]}hr, 咖啡{X[i][1]}杯)→ {label} {correct}")
範例結果:7/8 正確。唯一被分錯的是阿福——他只睡 4 小時但靠 2 杯咖啡硬撐,你的感知器看不到咖啡的功勞。
4.1.2. 你的任務:讓感知器也看到咖啡
把範例程式碼複製過來,修改 w 和 b ,讓感知器 同時考慮 睡眠和咖啡,把 8 個人全部分對。
提示:
- 每 1 杯咖啡的提神效果大約等於多睡 2 小時,所以 w2(咖啡權重)應該是 w1 的 2 倍
- 決策邊界為 \(w_1 \times 睡眠時數 + w_2 \times 咖啡杯數 + b = 0\)
正確答案(用來驗證):
w=[1, 2], b=-6 可以全部分對(8/8) 阿明(睡8hr, 咖啡2杯)→ 分數=6 → 清醒 ○ 小美(睡4hr, 咖啡0杯)→ 分數=-2 → 睡著 ○ 大雄(睡7hr, 咖啡1杯)→ 分數=3 → 清醒 ○ 胖虎(睡3hr, 咖啡1杯)→ 分數=-1 → 睡著 ○ 靜香(睡6hr, 咖啡2杯)→ 分數=4 → 清醒 ○ 小夫(睡5hr, 咖啡0杯)→ 分數=-1 → 睡著 ○ 阿福(睡4hr, 咖啡2杯)→ 分數=2 → 清醒 ○ ← 咖啡救了他! 魯夫(睡3hr, 咖啡0杯)→ 分數=-3 → 睡著 ○
1: import numpy as np # 數學運算 2: import matplotlib.pyplot as plt # 畫圖用(matplotlib 是 Python 的畫圖神器) 3: 4: # 階梯函數 5: def step_function(x): 6: return np.array(x >= 0, dtype=int) 7: 8: # 同學資料 [昨晚睡幾小時, 今天咖啡幾杯] 9: X = np.array([[8,2], [4,0], [7,1], [3,1], 10: [6,2], [5,0], [4,2], [3,0]]) 11: # 標籤(正確答案): 清醒=1, 睡著=0 12: y = np.array([1, 0, 1, 0, 1, 0, 1, 0]) 13: names = ['阿明','小美','大雄','胖虎','靜香','小夫','阿福','魯夫'] 14: 15: # TODO: 修改 w 和 b,讓感知器同時考慮睡眠和咖啡 16: # 提示:咖啡的提神效果大約是睡眠的 2 倍,所以咖啡權重應該更大 17: w = np.array([___, ___]) # [睡眠權重, 咖啡權重],請填入數字 18: b = ___ # 偏移值(門檻),請填入數字 19: 20: # 逐一測試每位同學 21: print("預測結果:") 22: for i in range(len(X)): 23: # np.dot(w, X[i]) 計算內積 = w1*睡眠 + w2*咖啡 24: pred = step_function(np.dot(w, X[i]) + b) # 加上偏移值後過階梯函數 25: label = '清醒' if pred == 1 else '睡著' 26: correct = '○' if pred == y[i] else '×' 27: print(f" {names[i]}(睡{X[i][0]}hr, 咖啡{X[i][1]}杯)→ {label} {correct}") 28: 29: # ===== 以下是畫圖部分 ===== 30: plt.figure(figsize=(6, 5)) # 建立 6x5 吋的圖 31: awake = y == 1 # 布林陣列:哪些人是清醒的 32: asleep = y == 0 # 布林陣列:哪些人是睡著的 33: # 清醒的同學畫綠色圓點,睡著的畫紅色叉叉 34: plt.scatter(X[awake, 0], X[awake, 1], c='green', marker='o', s=100, label='清醒') 35: plt.scatter(X[asleep, 0], X[asleep, 1], c='red', marker='x', s=100, label='睡著') 36: # 在每個點旁邊標上名字 37: for i, name in enumerate(names): 38: plt.annotate(name, (X[i,0]+0.1, X[i,1]+0.1)) 39: 40: # 畫決策邊界(就是那條把清醒和睡著分開的線) 41: # 數學:w1*x1 + w2*x2 + b = 0,移項得 x2 = -(w1*x1 + b)/w2 42: x1_line = np.linspace(2, 9, 100) # x 軸上取 100 個均勻的點 43: x2_line = -(w[0] * x1_line + b) / w[1] # 對應的 y 值 44: plt.plot(x1_line, x2_line, 'b--', linewidth=2, label='決策邊界') 45: 46: plt.xlabel('昨晚睡幾小時') 47: plt.ylabel('今天咖啡幾杯') 48: plt.title('感知器預測:你會不會睡著?') 49: plt.legend() # 顯示圖例 50: plt.grid(True) # 顯示格線 51: plt.savefig("images/perceptron-sleep.png", dpi=300) # 儲存圖片
4.1.3. 思考題
- 如果你只用睡眠時數(w2 設為 0),能不能把 8 個人全部分對?哪個人會被分錯?為什麼?
- 阿福只睡 4 小時但喝了 2 杯咖啡,居然保持清醒。你的感知器有抓到「咖啡續命」這個規律嗎?
- 你自己昨晚睡幾小時、今天喝了幾杯咖啡?把自己的數值代入你的感知器,它預測你這堂課會不會睡著?
4.2. 練習二:感知器學習演算法
在練習一中,我們靠「猜」來找權重。但感知器其實可以透過 學習演算法 自動找到適合的權重!
4.2.1. 感知器學習規則
感知器的學習過程就像「從錯誤中學習」:每次預測錯了,就稍微調整權重,讓下次更可能答對。具體步驟如下:
- 初始化權重 \(w\) 和偏移值 \(b\) 為 0
- 對每筆訓練資料 \((x, y_{true})\):
- 計算預測值 \(y_{pred} = step(w \cdot x + b)\)
- 若預測錯誤(\(y_{pred} \neq y_{true}\)),更新權重:
- \(w \leftarrow w + \eta \cdot (y_{true} - y_{pred}) \cdot x\)
- \(b \leftarrow b + \eta \cdot (y_{true} - y_{pred})\)
- 若預測正確,不做任何更新
- 重複多次(稱為 epoch)直到全部正確
其中 \(\eta\)(eta)稱為 學習率 ,控制每次調整的幅度。
4.2.2. 故事背景
期中考成績出來了。導師看著成績單,眉頭深鎖。
根據多年「偷窺學生」的經驗,導師發現一個殘酷的規律:學生期末會不會被當,跟他們 每週滑手機的時數 和 每週讀書的時數 高度相關。為了「提早關心」這些同學(翻譯:趁現在通知家長還來得及),導師決定建立一套 AI 預警系統。
以下是導師暗中觀察到的 6 位同學生活數據:
| 代號 | 每週滑手機(hr) | 每週讀書(hr) | 期末結果 |
|---|---|---|---|
| 小明 | 30 | 2 | 被當 |
| 學霸 | 5 | 25 | 存活 |
| 阿宅 | 25 | 5 | 被當 |
| 認真妹 | 10 | 20 | 存活 |
| 社畜 | 20 | 10 | 被當 |
| 覺醒者 | 15 | 15 | 存活 |
「社畜」是因為打工太多才一直滑手機不讀書的,但導師不管原因,只看結果。而「覺醒者」滑手機跟讀書時間一樣多,但因為讀書效率極高,勉強存活——屬於統計上的奇蹟。
4.2.3. 任務 A:執行學習演算法
請執行以下程式碼,觀察感知器如何 自動 找到權重,不用再像練習一那樣猜來猜去。
1: import numpy as np # 匯入 numpy 2: 3: # 階梯函數:感知器的「判官」 4: def step_function(x): 5: return np.array(x >= 0, dtype=int) 6: 7: # 訓練資料:每列 = [每週滑手機hr, 每週讀書hr] 8: # 導師暗中觀察的 6 位同學(這種老師真的存在嗎?) 9: X = np.array([[30,2], [5,25], [25,5], [10,20], [20,10], [15,15]]) 10: y = np.array([0, 1, 0, 1, 0, 1]) # 正確答案:0=被當, 1=存活 11: names = ['小明', '學霸', '阿宅', '認真妹', '社畜', '覺醒者'] 12: 13: # ===== 初始化:一切從零開始 ===== 14: w = np.zeros(2) # 權重初始為 [0, 0](感知器一開始什麼都不知道) 15: b = 0.0 # 偏移值也從 0 開始 16: eta = 0.01 # 學習率:每次犯錯時調整的幅度(太大會暴走,太小會龜速) 17: 18: # ===== 訓練過程:從錯誤中學習 ===== 19: print(f"初始狀態: w=[{w[0]:.3f}, {w[1]:.3f}], b={b:.3f}") 20: for epoch in range(50): # 最多跑 50 輪(epoch = 把所有資料看一遍) 21: w_before, b_before = w.copy(), b # 先記住這輪開始前的權重(等下比較用) 22: errors = 0 # 這輪犯了幾次錯 23: for xi, yi in zip(X, y): # 逐筆看訓練資料 24: y_pred = step_function(np.dot(w, xi) + b) # 用目前的權重做預測 25: error = yi - y_pred # 算誤差:正確答案 - 預測值(0=猜對,非0=猜錯) 26: if error != 0: # 猜錯了!該調整了 27: w = w + eta * error * xi # 更新權重:往正確方向微調 28: b = b + eta * error # 更新偏移值 29: errors += 1 # 錯誤數 +1 30: # 印出前 5 輪或收斂那輪的狀態 31: if epoch < 5 or errors == 0: 32: changed = "(權重已更新)" if (not np.array_equal(w, w_before) or b != b_before) else "(無變化)" 33: print(f"Epoch {epoch+1:2d}: w=[{w[0]:.3f}, {w[1]:.3f}], b={b:.3f}, 錯誤數={errors} {changed}") 34: if errors == 0: # 一整輪都沒犯錯 → 訓練完成! 35: print("訓練完成!導師的 AI 預警系統上線了。") 36: break 37: 38: # ===== 用學到的權重預測每位同學 ===== 39: print("\n=== 預測結果 ===") 40: for i in range(len(X)): 41: pred = step_function(np.dot(w, X[i]) + b) # 內積 + 偏移 → 階梯函數 42: result = '存活' if pred == 1 else '被當' 43: correct = '○' if pred == y[i] else '×' 44: print(f" {names[i]}: 滑手機{X[i][0]}hr 讀書{X[i][1]}hr → {result} {correct}")
執行後觀察:
- =w[0]=(滑手機的權重)是正的還是負的?直覺上合理嗎?
- =w[1]=(讀書的權重)是正的還是負的?為什麼?
- 花了幾個 epoch 才全部答對?
正確答案:
Epoch 6 收斂(6 個 epoch 就全部答對) 最終權重:w=[-0.300, 0.580], b=0.010 w[0] = -0.300(負的)→ 滑手機越多,分數越低,越容易被當 ✓ w[1] = 0.580(正的)→ 讀書越多,分數越高,越容易存活 ✓ 感知器自己學到了「滑手機有害、讀書有益」——跟導師的直覺完全一致
4.2.4. 任務 B:預測新同學的命運
導師又盯上了三位可疑人物。在上方程式碼的 最後面 加入以下程式碼,預測他們期末的下場:
1: # (接續上方程式碼,請貼在最後面一起執行) 2: # 注意:這段需要用到上方已經訓練好的 w 和 b,所以要一起跑 3: 4: # 三位新同學的資料:[每週滑手機hr, 每週讀書hr] 5: new_students = [ 6: ("邊緣人", [18, 12]), # 滑手機略多於讀書,命運未卜 7: ("佛系仔", [15, 16]), # 幾乎一半一半,讀書只多 1 小時 8: ("手遊王", [35, 1]), # 不用預測你也知道結果了吧 9: ] 10: print("\n=== 導師的黑名單預測 ===") 11: for name, data in new_students: 12: x = np.array(data) # 把資料轉成 numpy 陣列 13: score = np.dot(w, x) + b # 算分數 = w1*滑手機 + w2*讀書 + b 14: pred = step_function(score) # 分數 >= 0 → 存活(1),< 0 → 被當(0) 15: status = '存活' if pred == 1 else '被當' 16: emoji = '安全過關' if pred == 1 else '準備叫家長' 17: print(f" {name}: 滑{data[0]}hr 讀{data[1]}hr → 分數={score:.2f} → {status}({emoji})")
觀察結果,回答:
- 「邊緣人」被判存活還是被當?你覺得合理嗎?
- 「佛系仔」讀書只比滑手機多 1 小時,AI 覺得他能活嗎?
- 這三個人的「分數」有正有負——分數越大代表什麼?越小又代表什麼?
正確答案:
邊緣人: 滑18hr 讀12hr → 分數=1.57 → 存活(驚險過關) 佛系仔: 滑15hr 讀16hr → 分數=4.79 → 存活(讀書權重比滑手機高,多讀 1 小時就夠了) 手遊王: 滑35hr 讀1hr → 分數=-9.91 → 被當(毫無懸念,準備叫家長) 分數的意義: > 0 → 存活(越大越安全) < 0 → 被當(越小越危險) ≈ 0 → 命懸一線
4.2.5. 任務 C:調整學習率
把任務 A 程式碼中的 eta = 0.01 分別改成 0.001 和 0.1 ,重新執行,比較:
- 各需要幾個 epoch 才完成訓練?
- 學到的權重
w值一樣嗎? - 是不是學習率越大越好?(提示:如果改成
eta = 1.0會怎樣?)
正確答案:
eta=0.001: 收斂 Epoch 6, w=[-0.030, 0.058], b=0.001 eta=0.010: 收斂 Epoch 6, w=[-0.300, 0.580], b=0.010 eta=0.100: 收斂 Epoch 6, w=[-3.000, 5.800], b=0.100 eta=1.000: 收斂 Epoch 6, w=[-30.00, 58.00], b=1.000 → 四種學習率都在 Epoch 6 收斂(這筆資料太乖了) → 權重「方向」相同(w[0]<0, w[1]>0),「大小」跟 eta 成正比 → 在更複雜的問題中,太大的 eta 可能讓權重來回震盪,反而無法收斂
4.2.6. 任務 D:畫出決策邊界
在任務 A 程式碼的最後面加入以下程式碼,把導師的 AI 預警系統「看得見」:
1: # (接續任務 A 程式碼,請貼在最後面一起執行) 2: # 需要用到上方的 w, b, X, y, names 3: 4: import matplotlib.pyplot as plt # 匯入畫圖工具 5: 6: # 建立一張 7x6 吋的圖 7: plt.figure(figsize=(7, 6)) 8: survived = y == 1 # 布林遮罩:存活的同學 9: failed = y == 0 # 布林遮罩:被當的同學 10: 11: # 畫散佈圖:存活=綠色圓點,被當=紅色叉叉 12: # zorder=5 讓點畫在最上層(不會被線蓋住) 13: plt.scatter(X[survived, 0], X[survived, 1], c='green', marker='o', s=120, label='存活', zorder=5) 14: plt.scatter(X[failed, 0], X[failed, 1], c='red', marker='x', s=120, linewidths=2, label='被當', zorder=5) 15: 16: # 在每個點旁邊標上同學名字 17: for i, name in enumerate(names): 18: plt.annotate(name, (X[i,0]+0.5, X[i,1]+0.5), fontsize=10) 19: 20: # 畫決策邊界(生死線) 21: # 數學推導:w1*x1 + w2*x2 + b = 0 → x2 = -(w1*x1 + b) / w2 22: x1_line = np.linspace(0, 40, 100) # x 軸(滑手機時數)取 100 個點 23: if w[1] != 0: # 確認 w2 不是 0(除以 0 會爆炸) 24: x2_line = -(w[0] * x1_line + b) / w[1] # 算出對應的 y 值(讀書時數) 25: plt.plot(x1_line, x2_line, 'b--', linewidth=2, label='決策邊界(生死線)') 26: 27: plt.xlabel('每週滑手機時數') # x 軸標籤 28: plt.ylabel('每週讀書時數') # y 軸標籤 29: plt.title('導師的 AI 預警系統:期末生死分界線') 30: plt.legend() # 顯示圖例 31: plt.grid(True, alpha=0.3) # 淡淡的格線 32: plt.xlim(0, 40) # x 軸範圍 33: plt.ylim(0, 30) # y 軸範圍 34: plt.savefig("images/perceptron-flunk.png", dpi=300) # 存檔(dpi=300 高畫質) 35: print("決策邊界圖已儲存!") 36: print(f"生死線方程式: {w[0]:.3f} × 滑手機 + {w[1]:.3f} × 讀書 + {b:.3f} = 0")
看看那條「生死線」:線的哪一邊是安全區?哪一邊是危險區?你自己在圖上大概會落在哪裡?
正確答案:
生死線方程式: -0.300 × 滑手機 + 0.580 × 讀書 + 0.010 = 0 → 線的右上方(讀書多、滑手機少)= 安全區 → 線的左下方(讀書少、滑手機多)= 危險區