自然語言處理
Table of Contents
1. Wathch this
2. NLP Introduction
NLP,全名 Natural Language Processing(自然語言處理),是一門集電腦科學,人工智慧,語言學三者於一身的交叉性學科。其終極研究目標是讓電腦能夠處理甚至是“理解”人類的自然語言,進而説明人類解決一些現實生活中遇到的實際問題。這裡的語言“理解”是一個很抽象也很哲學的概念1。
在 NLP 中,我們將對語言的“理解”定義為是學習一個能夠解決具體問題的複雜函數的過程。
對 NLP 的研究通常在 5 個 Level 上進行1:
- 語音/文本分析:包括語言識別技術、OCR 技術、分詞技術等
- 詞形分析:例如分析一個 word 的前尾碼、詞根等
- 語法分析:從語法結構上分析一個句子的構成
- 語義分析:理解一個句子或單詞的語義
- 篇章分析:理解一段篇章的含義
注意,雖然這 5 個 Level 在研究的物件和難度上是一種遞進的關係,但對這 5 個 Level 的研究並不一定是連續的——例如:我們可以跳過對一個句子語法結構的分析而直接去理解句子的語義。
簡介影片: Natural Language Processing In 5 Minutes | What Is NLP And How Does It Work? | Simplilearn
DEMO: 雅婷文字轉語音
2.1. 自然語言處理有哪些技術
大致包括如下技術2:
- 分詞(Word Segmentation或Word Breaker,WB)
在英文文本當中每個詞之間都有間隔好分,但在中文文本當中一句話之間每個詞是沒有間隔的,所以需要對一個句子當中每個字進行切分,句子的基本語義單元就變成了詞,這就是分詞任務。 - 句法分析(Parsing)
句法分析指的是將句子中每個部分的組塊(也就是每個詞、字的歸屬類)標註出來。
- 組塊分析:標出句子的短語塊,如“This is a dog(NP)” 超級標籤分析:給每個句子加上超級標籤,超級標籤是一個樹形結構圖
- 成分句法分析:分析句子成分,給出一顆由終結符和非終結符構成的成分句法樹
- 依存句法分析:分析句中詞的依存關係,給出一顆由詞語依存關係構成的依存句法樹。
- 組塊分析:標出句子的短語塊,如“This is a dog(NP)” 超級標籤分析:給每個句子加上超級標籤,超級標籤是一個樹形結構圖
- 信息抽取(Information Extraction,IE):命名實體識別和關係抽取(Named Entity Recognition & Relation Extraction,NER):我們從一段文本中抽取關鍵信息即從無結構的文本中抽取結構化的信息,
- 詞性標註(Part Of Speech Tagging,POS):對詞語的詞性進行標註
- 指代消解(Coreference Resolution):消除一些對文本處理沒有意義的指代名詞,減輕程序對語言的處理。
- 詞義消歧(Word Sense Disambiguation,WSD):一個詞他可能會有歧義,該任務是用來消除歧義的。
- 機器翻譯(Machine Translation,MT):要實現文本的自動翻譯
- 自動文摘(Automatic Summarization):摘要是一大段文字,我們需要將裏面的梗提取出來然後縮短方便閱讀或方便提取信息。
- 問答系統(Question Answering):你提出一個問題機器給予你準確的答案
- OCR:也屬於視覺模塊內容,將圖片當中的文字通過機器識別圖像翻譯成文本形式
- 信息檢索(Information Retrieval,IR):用戶進行信息查詢和獲取的主要方式,是查找信息的方法和手段。
2.2. 自然語言處理核心問題是什麼2
- 文本分類
- 關鍵詞提取
- 情感分析
- 語義消歧
- 主題模型
- 機器翻譯
- 問題問答
- 漢語分詞
- 垂直領域的對話機器人
2.3. 自然語言處理有哪些應用方向2
- 搜索引擎
- 文本主題/標籤分類
- 文本創作與生成
- 機器翻譯
- 情感分析
- 輿情監控
- 語音識別系統
- 對話機器人
3. NLP 資料預處理
情緒分析 (sentiment analysis) 又稱為意見探勘 (opinion mining). 是使用 “自然語言處理”, 文字分析等方法, 找出作者某些話題上的態度, 情感, 評價或情緒.
情緒分析的商業價值, 可以提早得知顧客對公司或產品觀感, 以調整銷售策略方向.
IMDb 網路資料庫 (Internet Movie Database), 是一個電影相關的線上資料庫. IMDb 開始於 1990 年, 自 1998 年起成為亞馬遜旗下的網站, 至今已經累積大量的電影資訊. IMDb 共收錄了四百多萬作品資料.
IMDb 資料集共有 50,000 筆 “影評文字”, 分為訓練資料與測試資料各 25,000 筆,
每一筆 “影評文字” 都被標記成 “正面評價” 或 “負面評價”.
我們希望能建立一個模型, 經過大量 “影評文字” 訓練後, 此模型能用於預測 “影評文字” 是 “正面評價” 或 “負面評價”.
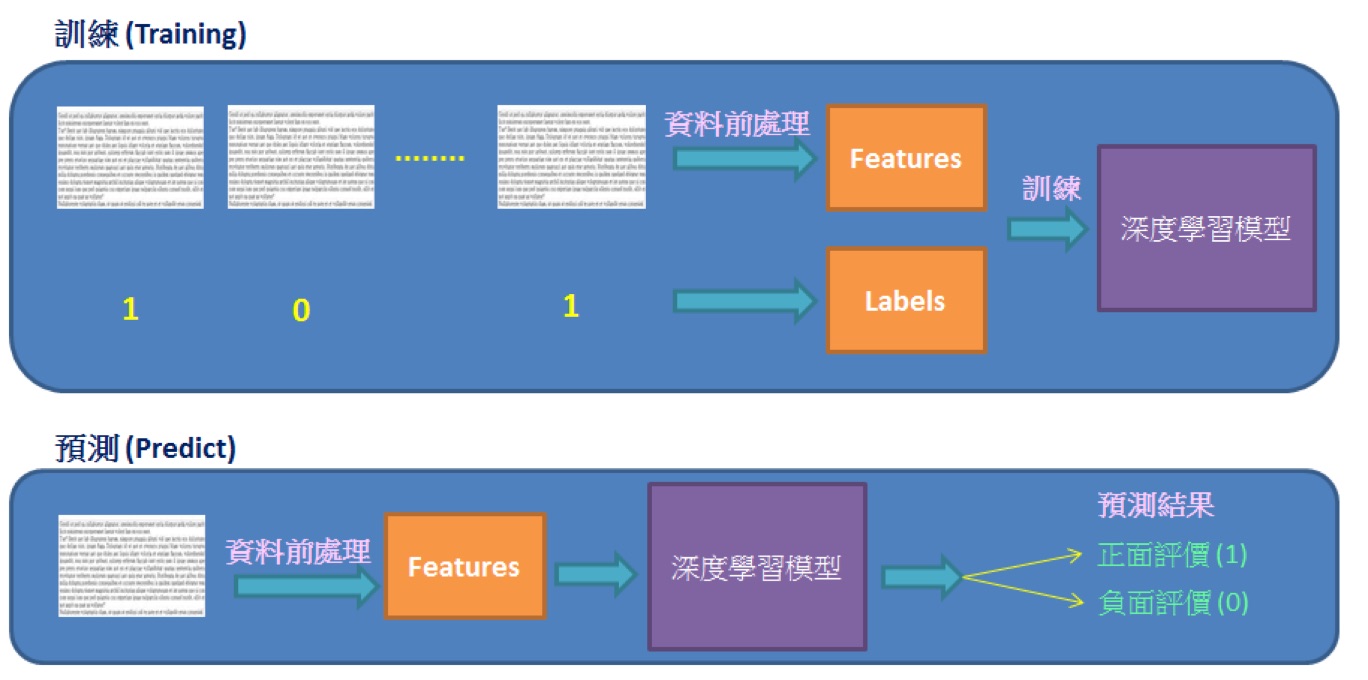
Figure 1: 資料前處理
3.1. IMDB
- num_words=10000 意味著只保留訓練集中最常出現的前 10000 個詞,不經常出現的單詞被拋棄—最終所有評論的維度保持相同。
- 變數 train_data,test_data 是電影評論的列表,每條評論由數字(對應單詞在詞典中出現的位置下標)列表組成。
- train_labels,test_labels 是 0,1 列表,0負面評論,1表示正面評論。
1: from keras.datasets import imdb 2: 3: (train_data,train_labels),(test_data,test_labels) = imdb.load_data(num_words=10000)
3.2. Tokenization
Token 法就是將所有會用到的 Token 做成一個詞彙對照表(或稱為詞彙字典),並用它來記錄每一個詞彙和其對應的數值,這樣我們就能照著這個對照表來將詞轉成數值。
- fit_on_text(texts): 使用一系列文檔來生成 token 詞典,texts 為 list 類,每個元素為一個文檔。
- texts_to_sequences(texts): 將多個文檔轉換為 word 下標的向量形式,shape 為[len(texts),len(text)] – (文檔數,每條文檔的長度)
- Tokenizer 對象.word_counts: 獲取字典{單詞:單詞出現次數},將單詞(字符串)映射為它們在訓練期間出現的次數。僅在調用 fit_on_texts 之後設置。
- Tokenizer 對象.word_docs: 獲取字典{單詞:單詞出現次數},將單詞(字符串)映射為它們在訓練期間所出現的文檔或文本的數量。僅在調用 fit_on_texts 之後設置。
- Tokenizer 對象.word_index: 獲取字典{單詞:單詞在字典中的索引值},將單詞(字符串)映射為它們的排名或者索引。僅在調用 fit_on_texts 之後設置。
- Tokenizer 對象.index_word[index]: 獲取單詞(字符串),根據傳入單詞所在字典中的索引值來獲取該單詞。
- Tokenizer 對象.word_index[word]: 獲取單詞在字典中的索引值,根據傳入單詞,獲取單詞所在字典中的索引值。
- Tokenizer 對象.document_count: 獲取整數。分詞器被訓練的文檔(文本或者序列)數量。僅在調用 fit_on_texts 或 fit_on_sequences 之後設置。
1: from tensorflow.keras.preprocessing.text import Tokenizer 2: 3: samples = ['吃什麼?', '咖哩飯 還是 牛排 還是 麵包 還是 都 吃'] 4: tokenizer = Tokenizer() 5: tokenizer.fit_on_texts(samples) 6: print('word_counts:', tokenizer.word_counts) 7: print('index_word:', tokenizer.index_word) 8: print('word_index:', tokenizer.word_index) 9: 10: seq = tokenizer.texts_to_sequences(['吃 咖哩飯','牛排 和 麵包']) 11: print('texts_to_sequences: ',seq) 12: seq2 = tokenizer.texts_to_sequences([['吃','咖哩飯'],['牛排', '和','麵包']]) 13: print('texts_to_sequences: ', seq2) 14: text = tokenizer.sequences_to_texts(seq) 15: print(text)
word_counts: OrderedDict([('吃什麼', 1), ('咖哩飯', 1), ('還是', 3), ('牛排', 1), ('麵包', 1), ('都', 1), ('吃', 1)])
index_word: {1: '還是', 2: '吃什麼', 3: '咖哩飯', 4: '牛排', 5: '麵包', 6: '都', 7: '吃'}
word_index: {'還是': 1, '吃什麼': 2, '咖哩飯': 3, '牛排': 4, '麵包': 5, '都': 6, '吃': 7}
texts_to_sequences: [[7, 3], []]
texts_to_sequences: [[7, 3], [4, 5]]
['吃 咖哩飯', '']
- num_words
何時要設定?當字數太多時(例如,拿 wiki 的文章來分析…)
- num_words: None 或整數,個人理解就是對統計單詞出現數量後選擇次數多的前 n 個單詞,後面的單詞都不做處理。
- tokenizer.texts_to_sequences(texts): 使用字典將對應詞轉成 index。shape 為 (文檔數,每條文檔的長度)
- tokenizer.texts_to_matrix(texts): 轉成 one-hot,與前面的不同。shape 為[len(texts),num_words]
- tokenizer.word_counts: 單詞在所有文檔中的總數量,如果 num_words=4,應該選擇 some thing to
- tokenizer.word_docs: 單詞出現在文檔中的數量
- tokenizer.word_index: 單詞對應的 index
- tokenizer.index_docs: index 對應單詞出現在文檔中的數量
1: from tensorflow.keras.preprocessing.text import Tokenizer 2: 3: samples =['吃 什麼?','咖哩飯 還是 牛排 還是 麵包 還是 都 吃'] 4: tokenizer = Tokenizer(num_words=3) 5: tokenizer.fit_on_texts(samples) 6: print(tokenizer.index_word) 7: 8: seq= tokenizer.texts_to_sequences(['吃 咖哩飯 和 麵包']) 9: print(seq)
{1: '還是', 2: '吃', 3: '什麼?', 4: '咖哩飯', 5: '牛排', 6: '麵包', 7: '都'} [[2]] - num_words: None 或整數,個人理解就是對統計單詞出現數量後選擇次數多的前 n 個單詞,後面的單詞都不做處理。
3.3. Sequence padding
在 NLP 中,文本一般是不定長的,所以在進行 batch 訓練之前,要先進行長度的統一,過長的句子可以通過 truncating 截斷到固定的長度,過短的句子可以通過 padding 增加到固定的長度,但是 padding 對應的字符只是為了統一長度,並沒有實際的價值,因此希望在之後的計算中屏蔽它們,這時候就需要 Mask3。
1: from tensorflow.keras.preprocessing.sequence import pad_sequences 2: 3: seq= [[5,1], [2], [3, 5, 4, 7, 8]] 4: 5: pad_seq = pad_sequences(seq, maxlen=4, dtype= 'int32', padding='pre', truncating='post', value=0) 6: print('pad_sequences:\n',pad_seq) 7: 8: pad_seq = pad_sequences(seq, maxlen=4, dtype= 'int32', padding='post', truncating='post', value=-1) 9: print('pad_sequences:\n', pad_seq)
pad_sequences: [[0 0 5 1] [0 0 0 2] [3 5 4 7]] pad_sequences: [[ 5 1 -1 -1] [ 2 -1 -1 -1] [ 3 5 4 7]]
3.4. one-hot encoding
1: from tensorflow.keras.preprocessing.text import Tokenizer 2: from tensorflow.keras.preprocessing.sequence import pad_sequences 3: from tensorflow.keras.utils import to_categorical 4: 5: num_classes = 10 6: convsat =['你好 哈囉', '什麼 怎麼', '你是誰 不告訴 你', '你 會做 什麼 都不會 會做', '什麼是 雞蛋 不知道 怎麼'] 7: 8: tokenizer = Tokenizer(num_words = num_classes, oov_token='N') 9: tokenizer.fit_on_texts(convsat) 10: print('tokenizer: ', tokenizer) 11: 12: convsat_seq = tokenizer.texts_to_sequences(convsat) 13: print('texts_to_sequences(受限num_classes,未列入class者sequence為1):\n', convsat_seq) 14: convsat_seq = pad_sequences(convsat_seq) 15: print('pad_sequences:\n', convsat_seq) 16: 17: convsat_one_hot = to_categorical(convsat_seq, num_classes=num_classes) 18: print('to_categorical:\n', convsat_one_hot)
tokenizer: <keras_preprocessing.text.Tokenizer object at 0x103ba3160> texts_to_sequences(受限num_classes,未列入class者sequence為1): [[6, 7], [2, 3], [8, 9, 4], [4, 5, 2, 1, 5], [1, 1, 1, 3]] pad_sequences: [[0 0 0 6 7] [0 0 0 2 3] [0 0 8 9 4] [4 5 2 1 5] [0 1 1 1 3]] to_categorical: [[[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 1. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 1. 0. 0.]] [[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 1. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]] [[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 1. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 1.] [0. 0. 0. 0. 1. 0. 0. 0. 0. 0.]] [[0. 0. 0. 0. 1. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.] [0. 0. 1. 0. 0. 0. 0. 0. 0. 0.] [0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 1. 0. 0. 0. 0.]] [[1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]]]
3.5. Multi-hot encoding
1: from tensorflow.keras.preprocessing.text import Tokenizer 2: 3: comment= ['真 好看 我 喜歡', '還好 缺乏 一點 劇情', '有 一點 雷 個人 不 喜歡', '我 喜歡 但 我 朋友 都 不 愛'] 4: 5: tokenizer = Tokenizer(num_words=10) 6: 7: tokenizer.fit_on_texts(comment) 8: 9: comment_multi_hot= tokenizer.texts_to_matrix(comment, mode='binary') 10: print('texts_to_matrix\n', comment_multi_hot) 11: 12: comment_multi_hot2= tokenizer.texts_to_matrix(comment, mode= 'count' ) 13: print('texts_to_matrix\n', comment_multi_hot2)
texts_to_matrix [[0. 1. 1. 0. 0. 1. 1. 0. 0. 0.] [0. 0. 0. 1. 0. 0. 0. 1. 1. 1.] [0. 0. 1. 1. 1. 0. 0. 0. 0. 0.] [0. 1. 1. 0. 1. 0. 0. 0. 0. 0.]] texts_to_matrix [[0. 1. 1. 0. 0. 1. 1. 0. 0. 0.] [0. 0. 0. 1. 0. 0. 0. 1. 1. 1.] [0. 0. 1. 1. 1. 0. 0. 0. 0. 0.] [0. 2. 1. 0. 1. 0. 0. 0. 0. 0.]]
3.6. 資料預處理
不能直接將 list 型別的資料送到神經網路中訓練,必須將 list 型別轉換為 tensor 張量型別。
- 有兩種轉換方式:
- 填充列表使每個列表長度都相同,然後轉換為整數型別的張量,形狀為(samples, word_indices),使用張量作為神經網路的第一層(Embedding 層,能處理這樣的整數型別張量);
- 將列表進行 one-hot 編碼,轉換成 0、 1 向量。然後用 Dense 網路層作為神經網路的第一層,處理浮點型別向量資料。
1: import numpy as np 2: 3: def vectorize_sequences(sequences, dimension=10000): 4: results = np.zeros((len(sequences), dimension)) #資料集長度,每個評論維度10000 5: for i, sequence in enumerate(sequences): 6: results[i, sequence] = 1 # one-hot 7: return results 8: 9: x_train = vectorize_sequences(train_data) 10: x_test = vectorize_sequences(test_data) 11: y_train = np.asarray(train_labels).astype('float32') # 向量化標籤資料 12: y_test = np.asarray(test_labels).astype('float32')
- 填充列表使每個列表長度都相同,然後轉換為整數型別的張量,形狀為(samples, word_indices),使用張量作為神經網路的第一層(Embedding 層,能處理這樣的整數型別張量);
3.7. 共同部分
1: import random 2: import pandas as pd 3: 4: ## Read-in the reviews and print some basic descriptions of them 5: 6: !wget -q "http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz" 7: !tar xzf aclImdb_v1.tar.gz
3.8. Define Tokenization, Stop-word and Punctuation Removal Functions
1: Nsamp = 1000 # number of samples to generate in each class - 2: maxtokens = 200 # the maximum number of tokens per document 3: maxtokenlen = 100 # the maximum length of each token
3.9. Tokenization
1: def tokenize(row): 2: if row is None or row is '': 3: tokens = "" 4: else: 5: tokens = row.split(" ")[:maxtokens] 6: return tokens
p** Use regular expressions to remove unnecessary characters
1: import re 2: 3: def reg_expressions(row): 4: tokens = [] 5: try: 6: for token in row: 7: token = token.lower() # make all characters lower case 8: token = re.sub(r'[\W\d]', "", token) 9: token = token[:maxtokenlen] # truncate token 10: tokens.append(token) 11: except: 12: token = "" 13: tokens.append(token) 14: return tokens 15:
3.10. Stop-word removal
Stop-words are words that are very common in text but offer no useful information that can be used to classify the text.
Words such as is, and, the, are are examples of stop-words.
The NLTK library contains a list of 127 English stop-words and can be used to filter our tokenized strings.
1: import nltk 2: 3: nltk.download('stopwords') 4: from nltk.corpus import stopwords 5: stopwords = stopwords.words('english') 6: 7: # print(stopwords) # see default stopwords 8: # it may be beneficial to drop negation words from the removal list, 9: # as they can change the positive/negative meaning 10: # of a sentence 11: # stopwords.remove("no") 12: # stopwords.remove("nor") 13: # stopwords.remove("not")
1: def stop_word_removal(row): 2: token = [token for token in row if token not in stopwords] 3: token = filter(None, token) 4: return token
4. 資料預處理實務
- 情緒分析 (sentiment analysis) 又稱為意見探勘 (opinion mining). 是使用 “自然語言處理”, 文字分析等方法, 找出作者某些話題上的態度, 情感, 評價或情緒.
- 情緒分析的商業價值, 可以提早得知顧客對公司或產品觀感, 以調整銷售策略方向.
4.1. IMDB 介簡
- IMDB 網路資料庫 (Internet Movie Database), 是一個電影相關的線上資料庫. IMDB 開始於 1990 年, 自 1998 年起成為亞馬遜旗下的網站, 至今已經累積大量的電影資訊. IMDb 共收錄了四百多萬作品資料.
- IMDB 資料集共有 50,000 筆 “影評文字”, 分為訓練資料與測試資料各 25,000 筆,每一筆 “影評文字” 都被標記成 “正面評價” 或 “負面評價”.
- 我們希望能建立一個模型, 經過大量 “影評文字” 訓練後, 此模型能用於預測 “影評文字” 是 “正面評價” 或 “負面評價”4。
Figure 2: 資料前處理
4.2. 查看 IMDB 資料
- num_words=10000 意味著只保留訓練集中最常出現的前 10000 個詞,不經常出現的單詞被拋棄—最終所有評論的維度保持相同。
- 變數 train_data,test_data 是電影評論的列表,每條評論由數字(對應單詞在詞典中出現的位置下標)列表組成。
- train_labels,test_labels 是 0,1 列表,0負面評論,1表示正面評論。
1: from keras.datasets import imdb 2: 3: (train_data,train_labels),(test_data,test_labels) = imdb.load_data(num_words=10000) 4: 5: print(train_data[0]) #查看第 0 筆 "影評文字" 6: print(train_labels[0]) #第 0 筆的評價 label 為 1, 也就是 正面評價
[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32] 1
4.3. 資料預處理
不能直接將 list 型別的資料送到神經網路中訓練,必須將 list 型別轉換為 tensor 張量型別。有兩種轉換方式:
- 填充列表使每個列表長度都相同,然後轉換為整數型別的張量,形狀為(samples, word_indices),使用張量作為神經網路的第一層(Embedding 層,能處理這樣的整數型別張量);
- 將列表進行 one-hot 編碼,轉換成 0、 1 向量。然後用 Dense 網路層作為神經網路的第一層,處理浮點型別向量資料。
1: import numpy as np 2: from keras.datasets import imdb 3: 4: (train_data,train_labels),(test_data,test_labels) = imdb.load_data(num_words=10000) 5: 6: def vectorize_sequences(sequences, dimension=10000): 7: # 資料集長度,每個評論維度10000 8: results = np.zeros((len(sequences), dimension)) #資料集長度,每個評論維度10000 9: for i, sequence in enumerate(sequences): 10: results[i, sequence] = 1 # one-hot 11: return results 12: 13: x_train = vectorize_sequences(train_data) 14: x_test = vectorize_sequences(test_data) 15: print('vectorize_sequences: train_data') 16: print(x_train) 17: 18: # 向量化標籤資料 19: y_train = np.asarray(train_labels).astype('float32') 20: y_test = np.asarray(test_labels).astype('float32') 21: print('np.asarray: train_labels') 22: print(y_train)
vectorize_sequences: train_data [[0. 1. 1. ... 0. 0. 0.] [0. 1. 1. ... 0. 0. 0.] [0. 1. 1. ... 0. 0. 0.] ... [0. 1. 1. ... 0. 0. 0.] [0. 1. 1. ... 0. 0. 0.] [0. 1. 1. ... 0. 0. 0.]] np.asarray: train_labels [1. 0. 0. ... 0. 1. 0.]
4.4. Define Tokenization, Stop-word and Punctuation Removal Functions
Before proceeding, we must decide how many samples to draw from each class. We must also decide the maximum number of tokens per email, and the maximum length of each token. This is done by setting the following overarching hyperparameters
1: Nsamp = 1000 # number of samples to generate in each class - 'spam', 'not spam' 2: maxtokens = 200 # the maximum number of tokens per document 3: maxtokenlen = 100 # the maximum length of each token
- Tokenization
1: def tokenize(row): 2: if row is None or row is '': 3: tokens = "" 4: else: 5: tokens = row.split(" ")[:maxtokens] 6: return tokens
#+end_src
- Use regular expressions to remove unnecessary characters
Next, we define a function to remove punctuation marks and other nonword characters (using regular expressions) from the emails with the help of the ubiquitous python regex library. In the same step, we truncate all tokens to hyperparameter maxtokenlen defined above.
1: import re 2: 3: def reg_expressions(row): 4: tokens = [] 5: try: 6: for token in row: 7: token = token.lower() # make all characters lower case 8: token = re.sub(r'[\W\d]', "", token) 9: token = token[:maxtokenlen] # truncate token 10: tokens.append(token) 11: except: 12: token = "" 13: tokens.append(token) 14: return tokens
4.5. Stop-word removal
Stop-words are also removed. Stop-words are words that are very common in text but offer no useful information that can be used to classify the text. Words such as is, and, the, are are examples of stop-words. The NLTK library contains a list of 127 English stop-words and can be used to filter our tokenized strings.
1: import nltk 2: 3: nltk.download('stopwords') 4: from nltk.corpus import stopwords 5: stopwords = stopwords.words('english') 6: 7: # print(stopwords) # see default stopwords 8: # it may be beneficial to drop negation words from the removal list, 9: # as they can change the positive/negative meaning 10: # of a sentence 11: # stopwords.remove("no") 12: # stopwords.remove("nor") 13: # stopwords.remove("not")
1: def stop_word_removal(row): 2: token = [token for token in row if token not in stopwords] 3: token = filter(None, token) 4: return token
4.6. Bag-of-words model
- For the computer to make inferences of the e-mails, it has to be able to interpret the text by making a numerical representation of it. One way to do this is by using something called a “bag-of-words” model. This model simply counts the frequency of word tokens for each email and thereby represents it as a vector of these counts.
- 詞袋模型(英語:Bag-of-words model)是個在自然語言處理和信息檢索(IR)下被簡化的表達模型。此模型下,一段文本(比如一個句子或是一個文檔)可以用一個裝著這些詞的袋子來表示,這種表示方式不考慮文法以及詞的順序。
- 詞袋模型被廣泛應用在文件分類,詞出現的頻率可以用來當作訓練分類器的特徵
- Example implementation
The following models a text document using bag-of-words. Here are two simple text documents:
1) John likes to watch movies. Mary likes movies too. 2) Mary also likes to watch football games.
Based on these two text documents, a list is constructed as follows for each document:
1) "John","likes","to","watch","movies","Mary","likes","movies","too" 2) "Mary","also","likes","to","watch","football","games"
Representing each bag-of-words as a JSON object, and attributing to the respective JavaScript variable:
1) BoW1 = {"John":1,"likes":2,"to":1,"watch":1,"movies":2,"Mary":1,"too":1}; 2) BoW2 = {"Mary":1,"also":1,"likes":1,"to":1,"watch":1,"football":1,"games":1};Each key is the word, and each value is the number of occurrences of that word in the given text document.
The order of elements is free, so, for example
{“too”:1,“Mary”:1,“movies”:2,“John”:1,“watch”:1,“likes”:2,“to”:1} is also equivalent to BoW1. It is also what we expect from a strict JSON object representation.
Note: if another document is like a union of these two,
(3) John likes to watch movies. Mary likes movies too. Mary also likes to watch football games.
its JavaScript representation will be:
BoW3 = {"John":1,"likes":3,"to":2,"watch":2,"movies":2,"Mary":2,"too":1,"also":1,"football":1,"games":1}; 若只有上述單字,且以BoW3 的順序為基準來表示BoW1和BoW2: #+BEGIN_EXAMPLE BoW1 = [1, 2, 1, 1, 2, 1, 1, 0, 0, 0] BoW2 = [0, 1, 1, 1, 0, 1, 0, 1, 1, 1]So, as we see in the bag algebra, the “union” of two documents in the bags-of-words representation is, formally, the disjoint union, summing the multiplicities of each element.
\(Bow3=Bow1 \uplus Bow2\)
- Assemble matrices function
The assemble_bag() function assembles a new dataframe containing all the unique words found in the text documents. It counts the word frequency and then returns the new dataframe.
1: def assemble_bag(data): 2: used_tokens = [] 3: all_tokens = [] 4: 5: for item in data: 6: for token in item: 7: if token in all_tokens: 8: if token not in used_tokens: 9: used_tokens.append(token) 10: else: 11: all_tokens.append(token) 12: 13: df = pd.DataFrame(0, index = np.arange(len(data)), columns = used_tokens) 14: 15: for i, item in enumerate(data): 16: for token in item: 17: if token in used_tokens: 18: df.iloc[i][token] += 1 19: return df
4.7. Putting It All Together To Assemble Dataset
Now, putting all the preprocessing steps together we assemble our dataset…
- shuffle raw data and load data
1: import os 2: import numpy as np 3: 4: # shuffle raw data first 5: def unison_shuffle_data(data, header): 6: p = np.random.permutation(len(header)) 7: data = data[p] 8: header = np.asarray(header)[p] 9: return data, header 10: 11: # load data in appropriate form 12: def load_data(path): 13: data, sentiments = [], [] 14: for folder, sentiment in (('neg', 0), ('pos', 1)): 15: folder = os.path.join(path, folder) 16: for name in os.listdir(folder): 17: with open(os.path.join(folder, name), 'r') as reader: 18: text = reader.read() 19: text = tokenize(text) 20: text = stop_word_removal(text) 21: text = reg_expressions(text) 22: data.append(text) 23: sentiments.append(sentiment) 24: data_np = np.array(data) 25: data, sentiments = unison_shuffle_data(data_np, sentiments) 26: 27: return data, sentiments 28: 29: train_path = os.path.join('aclImdb', 'train') 30: test_path = os.path.join('aclImdb', 'test') 31: raw_data, raw_header = load_data(train_path) 32: 33: print(raw_data.shape) 34: print(len(raw_header))
Subsample required number of samples
1: # Subsample required number of samples 2: random_indices = np.random.choice(range(len(raw_header)),size=(Nsamp*2,),replace=False) 3: data_train = raw_data[random_indices] 4: header = raw_header[random_indices] 5: 6: print("DEBUG::data_train::") 7: print(data_train)
- Display sentiments and their frequencies in the dataset, to ensure it is roughly balanced between classes
1: unique_elements, counts_elements = np.unique(header, return_counts=True) 2: print("Sentiments and their frequencies:") 3: print(unique_elements) 4: print(counts_elements)
- Featurize and Create Labels
1: MixedBagOfReviews = assemble_bag(data_train) 2: # this is the list of words in our bag-of-words model 3: predictors = [column for column in MixedBagOfReviews.columns] 4: 5: # expand default pandas display options to make emails more clearly visible when printed 6: pd.set_option('display.max_colwidth', 300) 7: 8: MixedBagOfReviews # you could do print(MixedBagOfReviews), but Jupyter displays this nicer for pandas DataFrames
split into independent 70% training and 30% testing sets
1: # split into independent 70% training and 30% testing sets 2: data = MixedBagOfReviews.values 3: 4: idx = int(0.7*data.shape[0]) 5: 6: # 70% of data for training 7: train_x = data[:idx,:] 8: train_y = header[:idx] 9: # remaining 30% for testing 10: test_x = data[idx:,:] 11: test_y = header[idx:] 12: 13: print("train_x/train_y list details, to make sure it is of the right form:") 14: print(len(train_x)) 15: print(train_x) 16: print(train_y[:5]) 17: print(len(train_y))
5. 中文
5.1. Jeiba
6. 自然語言處理學習路線
若要讓電腦理解人類的語言,以中文來說,分成兩步驟:第一步是斷詞、理解詞;第二步則是分析句子,包含語法及語義的自動解析。自然語言處理透過這兩個步驟,將複雜的語言轉化為電腦容易處理、計算的形式。早期是人工訂定規則,現在則是讓機器自己學習5。
早期的方式是基於一套詞彙資料庫,用程式語言寫好人工訂定的規則,讓電腦依指令做出反應。但這種人工方式不可能包含所有語言的歧異性,例如,當同樣的詞在不同上下文產生不同意思,就會和原本的人工規則相互牴觸。1980 年代末期,自然語言處理引進機器學習 (Machine Learning) 的演算法,不再用程式語言命令電腦所有規則,而是建立演算法模型,讓電腦學會從訓練的資料中,尋找資料所含的特定模式和趨勢5。
要掌握自然語言處理,學習順序大至如下
- 熟悉基本知識、基本操作
- 如文本操作、正則、掌握一些基本文本處理框架英文有NLTK、spaCy,中文有中研院CKIP Transformers、CKIP Tagger、Jeiba
- 知道什麼是語言模型、利用語言模型來完成一些項目
- 文本表示:將文本中的字符串轉化爲計算機當中的向量
- 文本分類:分類模型傳統的一個解決方法就是標帶標註的語料,再特徵提取,然後訓分類器進行分類。這個分類器就會用比如說邏輯迴歸、貝葉斯、支持向量機、決策樹等等。
- 主題模型:使用無監督學習的方式對文本中的隱含語義進行聚類的統計模型
- seq2seq模型:通過深度神經網絡將一個序列作爲映射爲另外一個輸出的序列。
- 文本生成:GAN文本生成,也叫機器人寫作。
7. 如何表示自然語言與字詞(數學化)
語言由文字構成,利用「字詞」組合成各種意思。電腦透過三種手段來理解「字詞」:
- 詞庫
- 計數
- 推論(word2vec)
7.1. 詞庫
表達詞意的方式之一是利用辭典,例如,以辭典查「車」的字詞會有對應的解釋。
另一種方式是透過詞庫(thesaurus)型的辭典,將同義詞分在同一群中,如:
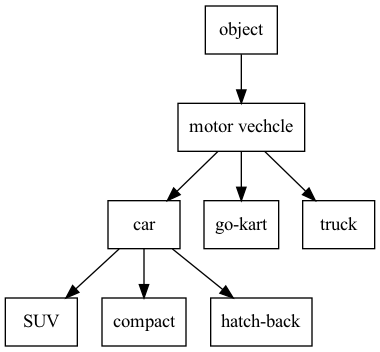
透過這種方式定義字詞間的關係。
7.2. 計數
語料庫(corpus):以研究自然語言處理或應用程式為目的所大量收集的文本資料。
7.3. Python事前準備
1: text = 'You say goodbye and I say hello.' 2: text = text.replace('.', ' .') 3: words = text.split(' ') 4: print(words) 5: word_to_id = {} 6: id_to_word = {} 7: 8: for word in words: 9: if word not in word_to_id: 10: new_id = len(word_to_id) 11: word_to_id[word] = new_id 12: id_to_word[new_id] = word 13: print(word_to_id) 14: print(id_to_word) 15: 16: corpus = [word_to_id[w] for w in words] 17: print(corpus) #文字句字轉數字表示
['You', 'say', 'goodbye', 'and', 'I', 'say', 'hello', '.']
{'You': 0, 'say': 1, 'goodbye': 2, 'and': 3, 'I': 4, 'hello': 5, '.': 6}
{0: 'You', 1: 'say', 2: 'goodbye', 3: 'and', 4: 'I', 5: 'hello', 6: '.'}
[0, 1, 2, 3, 4, 1, 5, 6]
corpus, word_to_id, id_to_word的產生可以寫成function
1: def preprocess(text): 2: text = text.lower() 3: text = text.replace('.', ' .') 4: words = text.split(' ') 5: 6: word_to_id = {} 7: id_to_word = {} 8: for word in words: 9: if word not in word_to_id: 10: new_id = len(word_to_id) 11: word_to_id[word] = new_id 12: id_to_word[new_id] = word 13: 14: corpus = np.array([word_to_id[w] for w in words]) 15: 16: return corpus, word_to_id, id_to_word
>>>
7.4. 字詞的分散式表示
- RGB的向量表示可以設定各種顏色,可以從(R,G,B)=(201, 23, 30)大略猜出這是紅色系的顏色。
- 字詞的分散式表示就是希望能以向量來表達詞意
- 分布假說(distributional hypothesis)
即,詞意是由周圍(前後)的字詞形成的。至於「周圍」的大小取決於window size,當window size=1,則取該字的前後一字詞為其上下文。
- 共生矩陣
計算一個字周圍的字詞
1: from nlputil import preprocess, create_co_matrix, ppmi 2: 3: text = 'You say goodbye and I say hello.' 4: corpus, word_to_id, id_to_word = preprocess(text) 5: vocab_size = len(id_to_word) 6: C = create_co_matrix(corpus, vocab_size, window_size=1) 7: print(text) 8: print(corpus) 9: print(C)
You say goodbye and I say hello. [0 1 2 3 4 1 5 6] [[0 1 0 0 0 0 0] [1 0 1 0 1 1 0] [0 1 0 1 0 0 0] [0 0 1 0 1 0 0] [0 1 0 1 0 0 0] [0 1 0 0 0 0 1] [0 0 0 0 0 1 0]]
其意思為
you say goodbye and I hello . you 0 1 0 0 0 0 0 say 1 0 1 0 1 1 0 goodbye 0 1 0 1 0 0 0 and 0 0 1 0 1 0 0 I 0 1 0 1 0 0 0 hello 0 1 0 0 0 0 1 . 0 0 0 0 0 1 0 如此解決了以向量表示字詞的目標。
7.5. 計算向量間的相似度
\[similarity(x,y)=\frac{x\cdot{y}}{\lvert\lvert{x}\rvert\rvert\lvert\lvert{y}\rvert\rvert}=\frac{x_1y_1+\cdots+x_ny_n}{\sqrt{x_1^2+\cdots+x_n^2}\sqrt{y_1^2+\cdots+y_n^2}}\]
即,將向量正規化後取得內積,實作(假設x,y為numpy陣列):
1: import numpy as np 2: def cos_similarity(x, y, eps=1e-8): 3: '''計算餘弦相似度 4: :param x: 向量 5: :param y: 向量 6: :param eps: 防止”除以0”的小數值 7: :return: 8: ''' 9: nx = x / (np.sqrt(np.sum(x ** 2)) + eps) 10: ny = y / (np.sqrt(np.sum(y ** 2)) + eps) 11: return np.dot(nx, ny)
上述程式在遇到零向量(向量元素皆為0)時會出現「除以0」的狀況,故加入一個epsilon解決問題。
這樣就能計算字詞間的相似度,例如在句子“You say goodbye and I say hello.”中,You和I的相似度為:
1: from nlputil import preprocess, create_co_matrix, ppmi, cos_similarity 2: 3: text = 'You say goodbye and I say hello.' 4: corpus, word_to_id, id_to_word = preprocess(text) 5: vocab_size = len(id_to_word) 6: C = create_co_matrix(corpus, vocab_size, window_size=1) 7: 8: c0 = C[word_to_id['you']] 9: c1 = C[word_to_id['i']] 10: print(cos_similarity(c0, c1))
0.7071067691154799
7.6. 相似詞排名
所有和 you 的字詞相似度排名
1: def most_similar(query, word_to_id, id_to_word, word_matrix, top=5): 2: '''相似詞搜尋 3: 4: :param query: 查詢(文本) 5: :param word_to_id: 將字詞轉換成字詞ID的字典 6: :param id_to_word: 將字詞ID轉換成字詞的字典 7: :param word_matrix: 整合詞向量的矩陣。用來儲存對應各列的詞向量 :param top: 要顯示到第幾名為止 8: ''' 9: if query not in word_to_id: 10: print('%s is not found' % query) 11: return 12: 13: print('\n[query] ' + query) 14: query_id = word_to_id[query] 15: query_vec = word_matrix[query_id] 16: 17: vocab_size = len(id_to_word) 18: 19: similarity = np.zeros(vocab_size) 20: for i in range(vocab_size): 21: similarity[i] = cos_similarity(word_matrix[i], query_vec) 22: 23: count = 0 24: for i in (-1 * similarity).argsort(): 25: if id_to_word[i] == query: 26: continue 27: print(' %s: %s' % (id_to_word[i], similarity[i])) 28: 29: count += 1 30: if count >= top: 31: return
結果
1: from nlputil import preprocess, create_co_matrix, ppmi, most_similar 2: 3: text = 'You say goodbye and I say hello.' 4: corpus, word_to_id, id_to_word = preprocess(text) 5: vocab_size = len(id_to_word) 6: C = create_co_matrix(corpus, vocab_size, window_size=1) 7: 8: most_similar('you', word_to_id, id_to_word, C, top=5)
[query] you goodbye: 0.7071067691154799 i: 0.7071067691154799 hello: 0.7071067691154799 say: 0.0 and: 0.0
7.7. Pointwise Mutual Information (PMI)
從共生矩陣中看不出“…the car…”這種常見用法中the和car的強烈關聯性。
\[PMI(x,y)=\log_2{\frac{P(x,y)}{P(x)P(y)}}=\log_2{\frac{\frac{C(x,y)}{N}}{\frac{C(x)}{N}\frac{C(y)}{N}}=\log_2{\frac{C(x,y)\cdot{N}}{C(x)C(y)}\]
P(X)為字詞x在語料庫出現的機率、P(y)為字詞y在語料庫出現的機率、P(X,y)為字詞x與y同時在語料庫出現的機率。PMI越高、x,y關聯性越強。
1: def ppmi(C, verbose=False, eps = 1e-8): 2: '''建立PPMI(下一個正向點間互資訊) 3: 4: :param C: 共生矩陣 5: :param verbose: 是否輸出執行狀況 6: :return: 7: ''' 8: M = np.zeros_like(C, dtype=np.float32) 9: N = np.sum(C) 10: S = np.sum(C, axis=0) 11: total = C.shape[0] * C.shape[1] 12: cnt = 0 13: 14: for i in range(C.shape[0]): 15: for j in range(C.shape[1]): 16: pmi = np.log2(C[i, j] * N / (S[j]*S[i]) + eps) 17: M[i, j] = max(0, pmi) 18: 19: if verbose: 20: cnt += 1 21: if cnt % (total//100) == 0: 22: print('%.1f%% done' % (100*cnt/total)) 23: return M
結果
1: from nlputil import preprocess, create_co_matrix, ppmi, most_similar 2: 3: text = 'You say goodbye and I say hello.' 4: corpus, word_to_id, id_to_word = preprocess(text) 5: vocab_size = len(id_to_word) 6: C = create_co_matrix(corpus, vocab_size, window_size=1) 7: W = ppmi(C) 8: print(C) 9: print(W)
[[0 1 0 0 0 0 0] [1 0 1 0 1 1 0] [0 1 0 1 0 0 0] [0 0 1 0 1 0 0] [0 1 0 1 0 0 0] [0 1 0 0 0 0 1] [0 0 0 0 0 1 0]] [[0. 1.8073549 0. 0. 0. 0. 0. ] [1.8073549 0. 0.8073549 0. 0.8073549 0.8073549 0. ] [0. 0.8073549 0. 1.8073549 0. 0. 0. ] [0. 0. 1.8073549 0. 1.8073549 0. 0. ] [0. 0.8073549 0. 1.8073549 0. 0. 0. ] [0. 0.8073549 0. 0. 0. 0. 2.807355 ] [0. 0. 0. 0. 0. 2.807355 0. ]]
7.8. 降維
dimensionality reduction: 刪減向量的維度並 儘量保留 「重要資訊」。
如下圖:
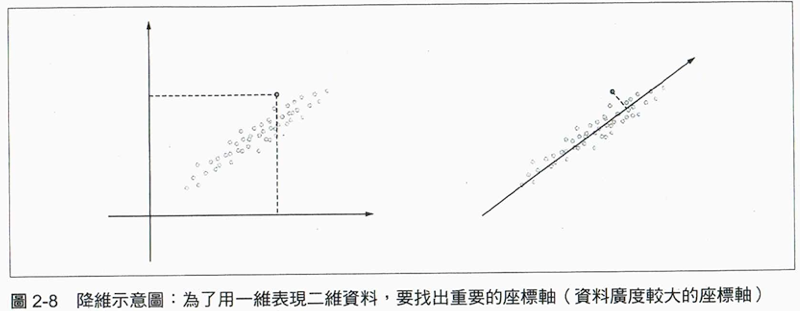
Figure 3: Caption
- 奇異值分解(Singular Value Decomposition, SVD)
把任意矩陣分解成三個矩陣乘積:\(A=U\Sigma V^T\) ,U與V為正交矩陣(orthogonal matrix),其行矩陣彼此正交,S為對角矩陣(對角線以外全部為0)
<#+CAPTION: Caption
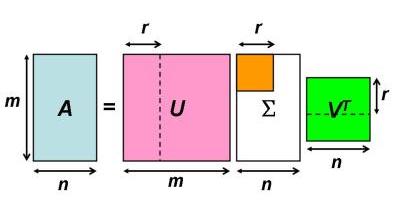
我們可以將SVD視為變換矩陣A的三個分解步驟:
- 旋轉\(V^T\)
- 伸縮\(\Sigma\)
- 再旋轉\(U\)
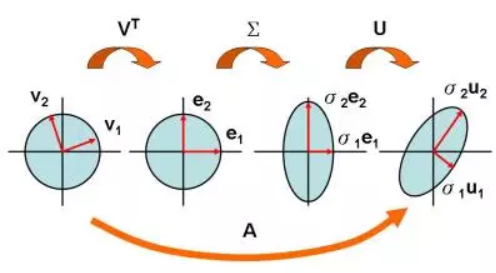
Figure 4: Caption
1: # coding: utf-8 2: from nlputil import preprocess, create_co_matrix, ppmi 3: import matplotlib.pyplot as plt 4: import numpy as np 5: text = 'You say goodbye and I say hello.' 6: corpus, word_to_id, id_to_word = preprocess(text) 7: vocab_size = len(id_to_word) 8: C = create_co_matrix(corpus, vocab_size, window_size=1) 9: W = ppmi(C) 10: 11: # SVD 12: U, S, V = np.linalg.svd(W) 13: 14: np.set_printoptions(precision=3) # 顯示3位有效數字 15: print(C[0]) 16: print(W[0]) 17: print(U[0]) 18: # plot 19: for word, word_id in word_to_id.items(): 20: plt.annotate(word, (U[word_id, 0], U[word_id, 1])) 21: plt.scatter(U[:,0], U[:,1], alpha=0.5) 22: 23: plt.savefig('images/SVD-1.png', dpi=300)
[0 1 0 0 0 0 0] [0. 1.807 0. 0. 0. 0. 0. ] [ 3.409e-01 -1.110e-16 -1.205e-01 -4.163e-16 -9.323e-01 -1.110e-16 -2.426e-17] [ 0. -0.598 0. 0.18 0. -0.781 0. ] [ 4.363e-01 -5.551e-17 -5.088e-01 -2.220e-16 2.253e-01 -1.388e-17 -7.071e-01] [ 1.665e-16 -4.978e-01 2.776e-17 6.804e-01 -1.110e-16 5.378e-01 7.467e-17]
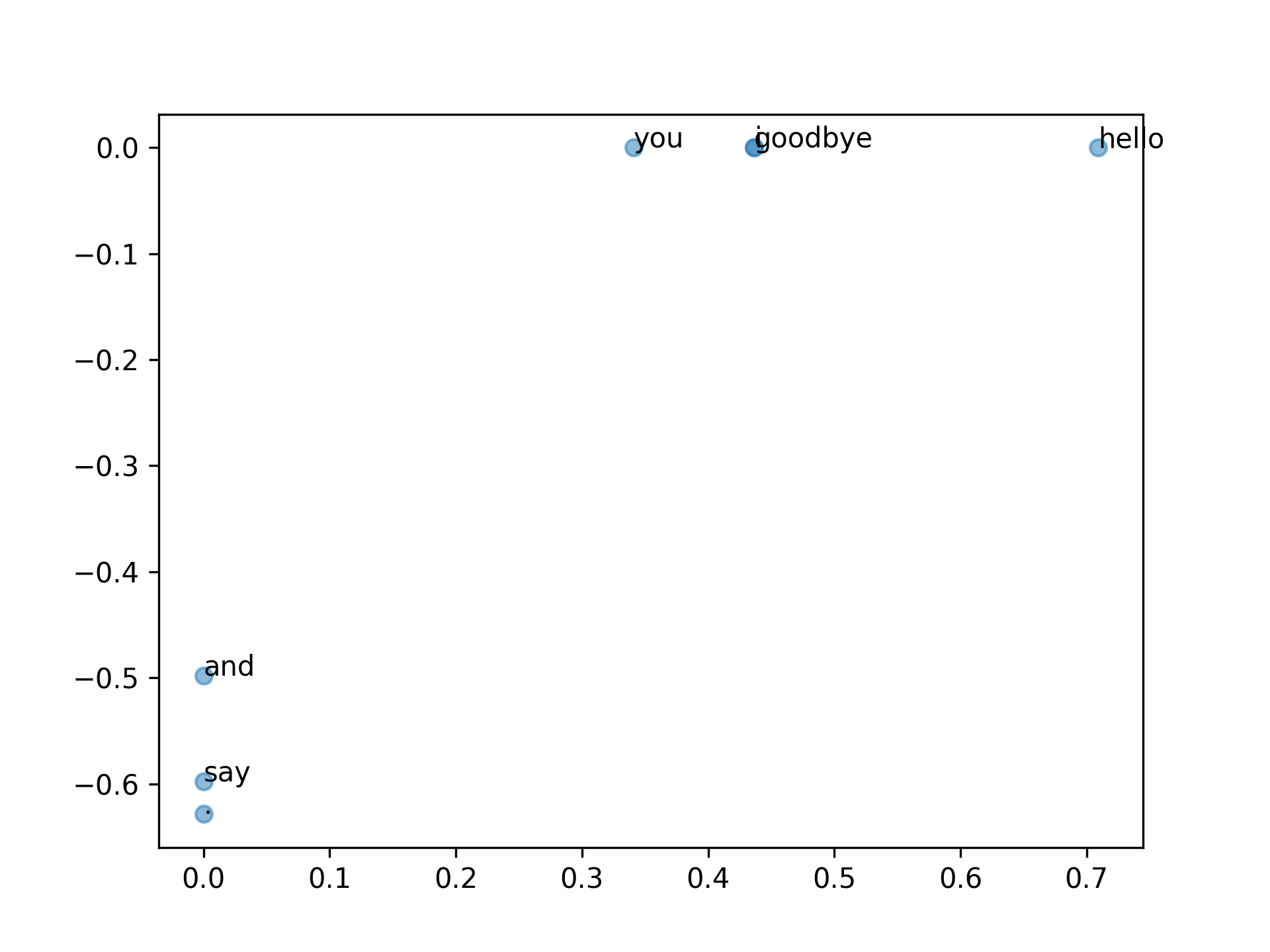
利用SVD,可以把sparse vector W[0]轉變成dense vector U[0],若要對U降維,則只要取U的前幾個元素,下圖為降成二維的結果。
若降維成三維,結果如下
1: # coding: utf-8 2: from nlputil import preprocess, create_co_matrix, ppmi 3: import matplotlib.pyplot as plt 4: import numpy as np 5: text = 'You say goodbye and I say hello.' 6: corpus, word_to_id, id_to_word = preprocess(text) 7: vocab_size = len(id_to_word) 8: C = create_co_matrix(corpus, vocab_size, window_size=1) 9: W = ppmi(C) 10: 11: # SVD 12: U, S, V = np.linalg.svd(W) 13: # 3D 14: fig = plt.figure() 15: ax = fig.gca(projection='3d') 16: UX = list(word_to_id.keys()) 17: print(UX) 18: #ax.scatter(U[:,0],U[:,1],U[:,2], alpha=0.5) 19: for row, word in zip(U, UX): 20: x = row[0] 21: y = row[1] 22: z = row[2] 23: ax.scatter(x, y, z, alpha=0.5) 24: #print(x, y, z) 25: ax.text(x, y, z, '%s' % (word), size=10, zorder=1, color='k') 26: 27: #plt.show() 28: plt.savefig('images/SVD-3D.png', dpi=300)
['you', 'say', 'goodbye', 'and', 'i', 'hello', '.']
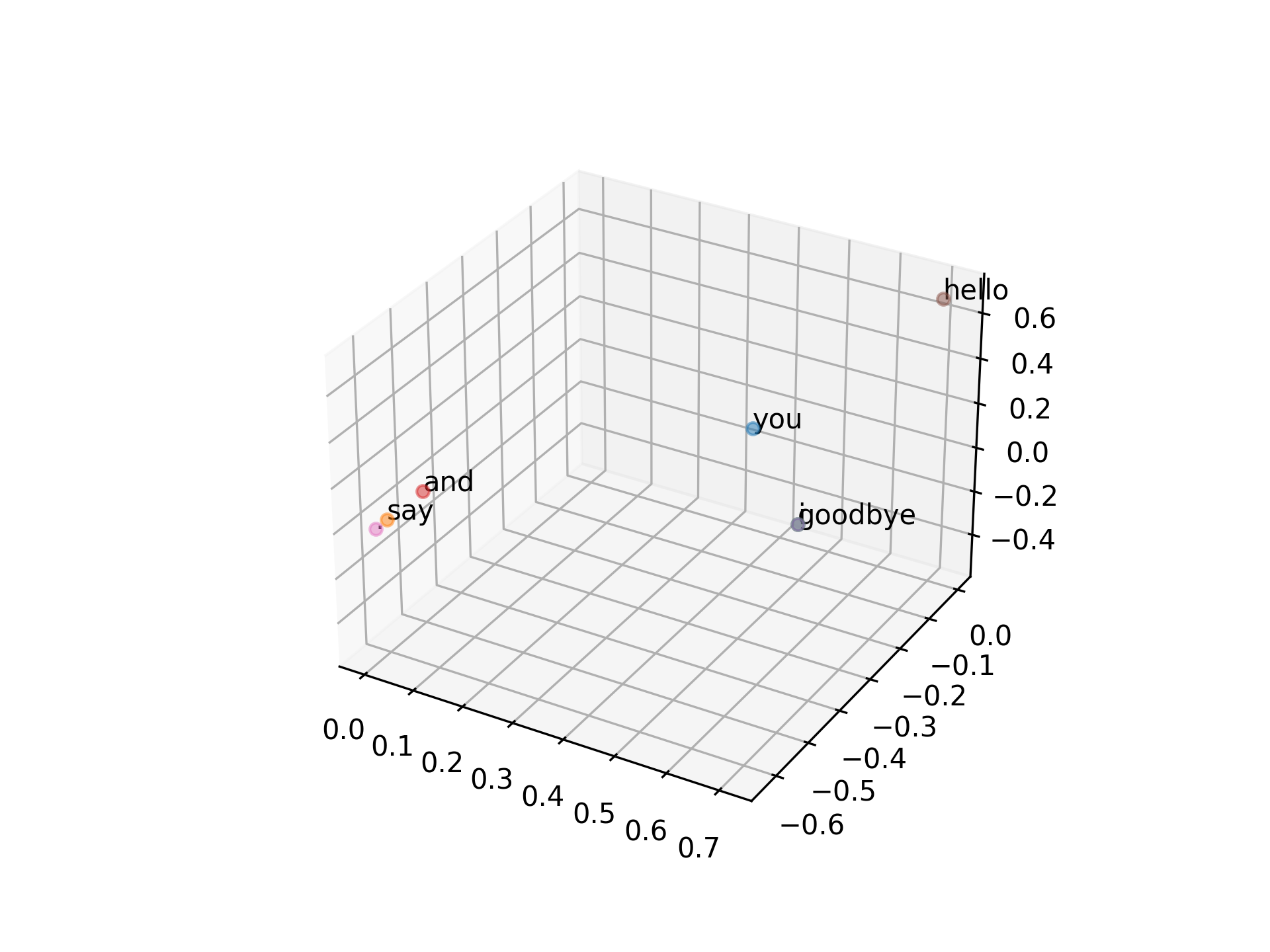
Figure 5: Caption
- 旋轉\(V^T\)
7.9. 使用正式的語料庫試試: PTB
- NLP中常用的語料庫(Penn Treebank),目的是對語料進行標註(詞性及句法分析),語料來源為1989年的華爾街日報,共1M words、2499篇文章。
- 下載PTB
1: # coding: utf-8 2: import sys 3: sys.path.append('..') 4: from dataset import ptb 5: 6: corpus, word_to_id, id_to_word = ptb.load_data('train') 7: 8: print('corpus size:', len(corpus)) 9: print('corpus[:30]:', corpus[:30]) 10: print() 11: print('id_to_word[0]:', id_to_word[0]) 12: print('id_to_word[1]:', id_to_word[1]) 13: print('id_to_word[2]:', id_to_word[2]) 14: print() 15: print("word_to_id['car']:", word_to_id['car']) 16: print("word_to_id['happy']:", word_to_id['happy']) 17: print("word_to_id['lexus']:", word_to_id['lexus']) 18:
corpus size: 929589 corpus[:30]: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29] id_to_word[0]: aer id_to_word[1]: banknote id_to_word[2]: berlitz word_to_id['car']: 3856 word_to_id['happy']: 4428 word_to_id['lexus']: 7426
計算相似度
1: # coding: utf-8 2: import numpy as np 3: from nlputil import preprocess, create_co_matrix, ppmi, most_similar 4: from dataset import ptb 5: 6: window_size = 2 7: wordvec_size = 100 8: 9: corpus, word_to_id, id_to_word = ptb.load_data('train') 10: vocab_size = len(word_to_id) 11: print('counting co-occurrence ...') 12: C = create_co_matrix(corpus, vocab_size, window_size) 13: print('calculating PPMI ...') 14: W = ppmi(C, verbose=True) 15: 16: print('calculating SVD ...') 17: try: 18: # truncated SVD (fast!) 19: from sklearn.utils.extmath import randomized_svd 20: U, S, V = randomized_svd(W, n_components=wordvec_size, n_iter=5, 21: random_state=None) 22: except ImportError: 23: # SVD (slow) 24: U, S, V = np.linalg.svd(W) 25: 26: word_vecs = U[:, :wordvec_size] 27: 28: querys = ['you', 'year', 'car', 'toyota'] 29: for query in querys: 30: most_similar(query, word_to_id, id_to_word, word_vecs, top=5)
計算結果(要跑很久…)
[query] you
i: 0.7198655605316162
we: 0.6279044151306152
do: 0.5669074654579163
’ll: 0.5507640242576599
anybody: 0.5294491648674011
[query] year
month: 0.722590446472168
earlier: 0.6536098122596741
quarter: 0.6418145895004272
last: 0.6153697371482849
fiscal: 0.581279993057251
[query] car
auto: 0.5696402192115784
truck: 0.5232617259025574
luxury: 0.508746862411499
vehicle: 0.49371591210365295
domestic: 0.47702285647392273
[query] toyota
motor: 0.7109977006912231
nissan: 0.661170482635498
motors: 0.6224923729896545
lexus: 0.6070802211761475
mazda: 0.6053721308708191
7.10. 詞袋模型(Bag-of-words model)
詞袋模型(英語:Bag-of-words model)是個在自然語言處理和信息檢索(IR)下被簡化的表達模型。在此模型下,一段文本(比如一個句子或是一個文檔)可以用一個裝著這些詞的袋子來表示,這種表示方式不考慮文法以及詞的順序。
詞袋模型被廣泛應用在文件分類,詞出現的頻率可以用來當作訓練分類器的特徵
1: BoW1 = {"John":1,"likes":2,"to":1,"watch":1,"movies":2,"Mary":1,"too":1}; 2: BoW2 = {"Mary":1,"also":1,"likes":1,"to":1,"watch":1,"football":1,"games":1}; 3: BoW3 = {"John":1,"likes":3,"to":2,"watch":2,"movies":2,"Mary":2,"too":1,"also":1,"football":1,"games":1};
- 只有上述單字,且以 BoW3 的順序為基準
1: (1) BoW1 = [1, 2, 1, 1, 2, 1, 1, 0, 0, 0] 2: (2) BoW2 = [0, 1, 1, 1, 0, 1, 0, 1, 1, 1]
- Bag-of-words model
To interpret the text by making a numerical representation of it.
One way to do this is by using something called a “bag-of-words” model.
This model simply counts the frequency of word tokens for each email and thereby represents it as a vector of these counts.
- Assemble matrices function**
The assemble_bag() function assembles a new dataframe containing all the unique words found in the text documents.
It counts the word frequency and then returns the new dataframe.
1: def assemble_bag(data): 2: used_tokens = [] 3: all_tokens = [] 4: 5: for item in data: 6: for token in item: 7: if token in all_tokens: 8: if token not in used_tokens: 9: used_tokens.append(token) 10: else: 11: all_tokens.append(token) 12: 13: df = pd.DataFrame(0, index = np.arange(len(data)), columns = used_tokens) 14: 15: for i, item in enumerate(data): 16: for token in item: 17: if token in used_tokens: 18: df.iloc[i][token] += 1 19: return df
- Putting It All Together To Assemble Dataset
1: import os 2: import numpy as np 3: 4: # shuffle raw data first 5: def unison_shuffle_data(data, header): 6: p = np.random.permutation(len(header)) 7: data = data[p] 8: header = np.asarray(header)[p] 9: return data, header
1: # load data in appropriate form 2: def load_data(path): 3: data, sentiments = [], [] 4: for folder, sentiment in (('neg', 0), ('pos', 1)): 5: folder = os.path.join(path, folder) 6: for name in os.listdir(folder): 7: with open(os.path.join(folder, name), 'r') as reader: 8: text = reader.read() 9: text = tokenize(text) 10: text = stop_word_removal(text) 11: text = reg_expressions(text) 12: data.append(text) 13: sentiments.append(sentiment) 14: data_np = np.array(data) 15: data, sentiments = unison_shuffle_data(data_np, sentiments) 16: 17: return data, sentiments 18:
1: train_path = os.path.join('aclImdb', 'train') 2: test_path = os.path.join('aclImdb', 'test') 3: 4: raw_data, raw_header = load_data(train_path) 5: 6: print(raw_data.shape) 7: print(len(raw_header))
1: # Subsample required number of samples 2: random_indices = np.random.choice(range(len(raw_header)),size=(Nsamp*2,),replace=False) 3: 4: data_train = raw_data[random_indices] 5: header = raw_header[random_indices] 6: 7: print("DEBUG::data_train::") 8: print(data_train)
- Display sentiments and their frequencies in the dataset, to ensure it is roughly balanced between classes
1: unique_elements, counts_elements = np.unique(header, return_counts=True) 2: 3: print("Sentiments and their frequencies:") 4: print(unique_elements) 5: print(counts_elements)
- Display sentiments and their frequencies in the dataset, to ensure it is roughly balanced between classes
- Featurize and Create Labels
1: MixedBagOfReviews = assemble_bag(data_train) 2: 3: # this is the list of words in our bag-of-words model 4: predictors = [column for column in MixedBagOfReviews.columns] 5: 6: # expand default pandas display options to 7: # make emails more clearly visible when printed 8: pd.set_option('display.max_colwidth', 300) 9: 10: MixedBagOfReviews 11: # you could do print(MixedBagOfReviews), 12: # but Jupyter displays this nicer for pandas DataFrames
1: # split into independent 70% training and 30% testing sets 2: data = MixedBagOfReviews.values 3: 4: idx = int(0.7*data.shape[0]) 5: 6: # 70% of data for training 7: train_x = data[:idx,:] 8: train_y = header[:idx] 9: 10: # remaining 30% for testing 11: test_x = data[idx:,:] 12: test_y = header[idx:] 13: 14: 15: 16: print("train_x/train_y list details, to make sure it is of the right form:") 17: print(len(train_x)) 18: print(train_x) 19: print(train_y[:5]) 20: print(len(train_y))
- fastText embedding vectors
- TL for NLP: section3.1_Movies_Word_Embeddin
The following functions are used to extract fastText embedding vectors for each review
1: import time 2: from gensim.models import FastText, KeyedVectors 3: 4: !ls 5: 6: start=time.time() 7: FastText_embedding = KeyedVectors.load_word2vec_format("../input/jigsaw/wiki.en.vec") 8: end = time.time() 9: print("Loading the embedding took %d seconds"%(end-start))
1: def handle_out_of_vocab(embedding,in_txt): 2: out = None 3: for word in in_txt: 4: try: 5: tmp = embedding[word] 6: tmp = tmp.reshape(1,len(tmp)) 7: 8: if out is None: 9: out = tmp 10: else: 11: out = np.concatenate((out,tmp),axis=0) 12: except: 13: pass 14: 15: return out
1: def assemble_embedding_vectors(data): 2: out = None 3: for item in data: 4: tmp = handle_out_of_vocab(FastText_embedding,item) 5: if tmp is not None: 6: dim = tmp.shape[1] 7: if out is not None: 8: vec = np.mean(tmp,axis=0) 9: vec = vec.reshape((1,dim)) 10: out = np.concatenate((out,vec),axis=0) 11: else: 12: out = np.mean(tmp,axis=0).reshape((1,dim)) 13: else: 14: pass 15: 16: return out 17:
1: 2: import numpy as np 3: 4: # shuffle raw data first 5: def unison_shuffle_data(data, header): 6: p = np.random.permutation(len(header)) 7: data = data[p] 8: header = np.asarray(header)[p] 9: return data, header 10:
1: # load data in appropriate form 2: def load_data(path): 3: data, sentiments = [], [] 4: for folder, sentiment in (('neg', 0), ('pos', 1)): 5: folder = os.path.join(path, folder) 6: for name in os.listdir(folder): 7: with open(os.path.join(folder, name), 'r') as reader: 8: text = reader.read() 9: text = tokenize(text) 10: text = stop_word_removal(text) 11: text = reg_expressions(text) 12: data.append(text) 13: sentiments.append(sentiment) 14: data_np = np.array(data) 15: data, sentiments = unison_shuffle_data(data_np, sentiments) 16: 17: return data, sentiments 18: 19: train_path = os.path.join('aclImdb', 'train') 20: test_path = os.path.join('aclImdb', 'test') 21: raw_data, raw_header = load_data(train_path) 22: 23: print(raw_data.shape) 24: print(len(raw_header))
1: # Subsample required number of samples 2: random_indices = np.random.choice(range(len(raw_header)),size=(Nsamp*2,),replace=False) 3: data_train = raw_data[random_indices] 4: header = raw_header[random_indices] 5: 6: print("DEBUG::data_train::") 7: print(data_train)
- Display sentiments and their frequencies in the dataset, to ensure it is roughly balanced between classes
1: unique_elements, counts_elements = np.unique(header, return_counts=True) 2: 3: print("Sentiments and their frequencies:") 4: print(unique_elements) 5: print(counts_elements)
- Display sentiments and their frequencies in the dataset, to ensure it is roughly balanced between classes
- TL for NLP: section3.1_Movies_Word_Embeddin
8. Representing text as numbers
Machine learning models take vectors (arrays of numbers) as input.
When working with text, the first thing we must do come up with a strategy to convert strings to numbers (or to “vectorize” the text) before feeding it to the model.
8.1. example
Consider the sentence
The cat sat on the mat
The vocabulary (or unique words) in this sentence is (cat, mat, on, sat, the).
To represent each word, we will create a zero vector with length equal to the vocabulary, then place a one in the index that corresponds to the word.
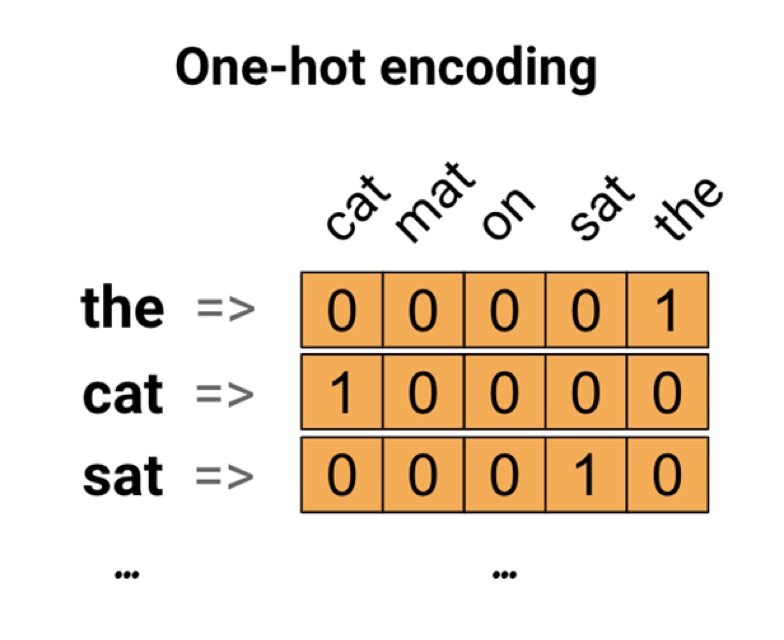
To create a vector that contains the encoding of the sentence, we could then concatenate the one-hot vectors for each word.
This approach is inefficient. A one-hot encoded vector is sparse (meaning, most indices are zero). Imagine we have 10,000 words in the vocabulary. To one-hot encode each word, we would create a vector where 99.99% of the elements are zero.
Continuing the example above, we could assign 1 to “cat”, 2 to “mat”, and so on.
We could then encode the sentence “The cat sat on the mat” as a dense vector like [5, 1, 4, 3, 5, 2].
This appoach is efficient. Instead of a sparse vector, we now have a dense one (where all elements are full).
缺點有二:
- The integer-encoding is arbitrary (it does not capture any relationship between words).
- An integer-encoding can be challenging for a model to interpret. A linear classifier, for example, learns a single weight for each feature. Because there is no relationship between the similarity of any two words and the similarity of their encodings, this feature-weight combination is not meaningful.
8.2. Word embedding
Word embeddings give us a way to use an efficient, dense representation in which similar words have a similar encoding.
Importantly, we do not have to specify this encoding by hand.
An embedding is a dense vector of floating point values (the length of the vector is a parameter you specify). Instead of specifying the values for the embedding manually, they are trainable parameters (weights learned by the model during training, in the same way a model learns weights for a dense layer). It is common to see word embeddings that are 8-dimensional (for small datasets), up to 1024-dimensions when working with large datasets.
A higher dimensional embedding can capture fine-grained relationships between words, but takes more data to learn.
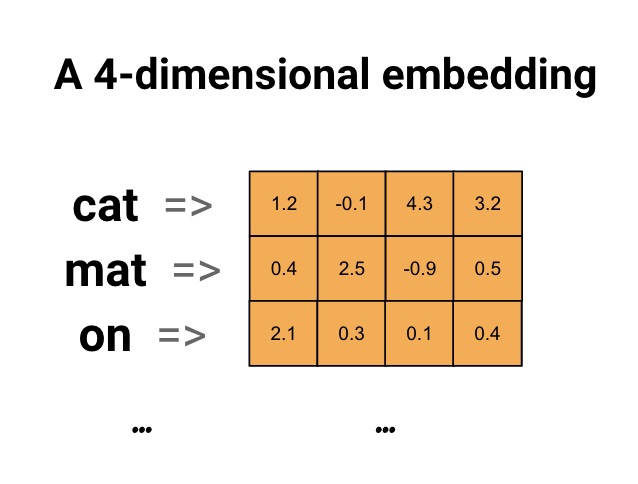
Figure 6: Word Embedding
Each word is represented as a 4-dimensional vector of floating point values.
Another way to think of an embedding is as “lookup table”.
After these weights have been learned, we can encode each word by looking up the dense vector it corresponds to in the table
9. 推論: word2vec
前章以「計數手法」取得字詞的分散式表示,本章要以「推論」取代「計數」,在推論中可以使用類神經網路,即word2vec。
9.1. 計數 v.s. 推論
- 計數要建立共生矩陣,再套用到SVD獲得dense matrix,處理資料量為 \(n\times n\) 的矩陣,花費 \(O(n^2)\) 的時間成本。
- 推論(以類神經網路為例)一般使用小批次進行學習。

Figure 7: Caption
9.2. 推論
以下圖為例,推論的工作是由you與goodbye推論出?會出現哪個字詞。

在推論中,將上下文輸入某一模型,然後輸出各字詞可能出現的機率
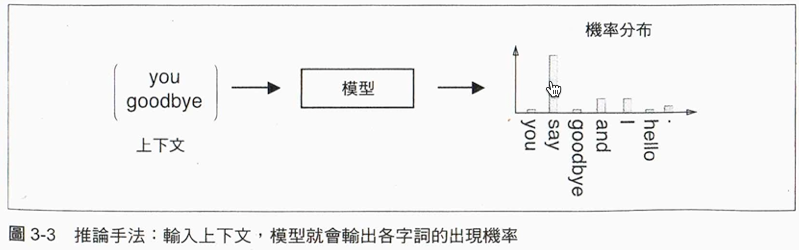
Figure 8: Caption
9.3. 在類神經網網路中表達字詞
類神經網路無法直接處理you、say等字詞,而是將這些字詞 轉換 為「固定長度的向量」,方法之一是使用one-hot-encoding。
如:
| 字詞 | 字詞ID | one-hot encoding |
|---|---|---|
| you | 0 | (1,0,0,0,0,0,0) |
| goodbye | 2 | (0,0,1,0,0,0,0) |
- 輸入層
字詞以one-hot encoding表示後,輸入層就如下圖所示,每個字詞為一個神經元

每個神經元(字詞)以 全連接(full-connected) 方式連至中間層,每個箭頭都有權重(參數),將權重與輸入層的神經元加權求平均就得到中間層。此處的權重為一矩陣,此處略過bias的概念。
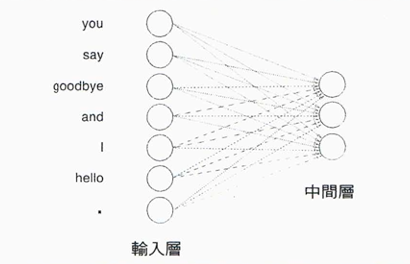
Figure 9: Caption
- 輸入層至中間層的計算
1: import numpy as np 2: from nlplayers import MatMul 3: 4: c = np.array([[1, 0, 0, 0, 0, 0, 0]]) 5: W = np.random.randn(7, 3) 6: layer = MatMul(W) 7: h = layer.forward(c) 8: print(h)
[[ 1.75309728 0.45025495 -1.25773857]]
下圖為上述程式以字詞 you 和weight矩陣運算後得到的vector。這裡使用MatMul層,以forword()進行正向傳播,MatMul的內容大致如下:
1: class MatMul: 2: def __init__(self, W): 3: self.params = [W] 4: self.grads = [np.zeros_like(W)] 5: self.x = None 6: 7: def forward(self, x): 8: W, = self.params 9: out = np.dot(x, W) 10: self.x = x 11: return out 12: 13: def backward(self, dout): 14: W, = self.params 15: dx = np.dot(dout, W.T) 16: dW = np.dot(self.x.T, dout) 17: self.grads[0][...] = dW 18: return dx
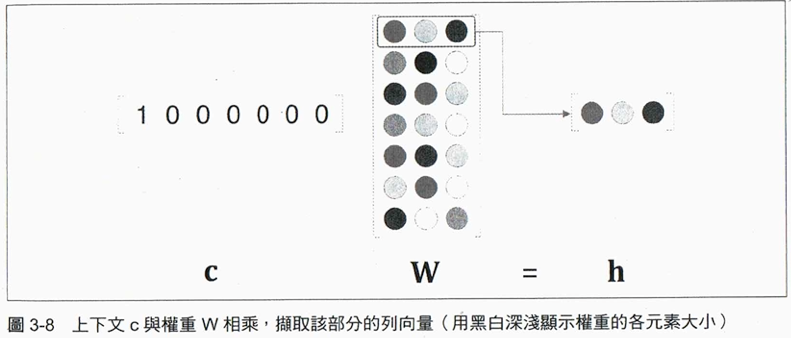
Figure 10: Caption
9.4. CBOW模型
CBOW有兩個輸入層(即前後字詞、各自有其weight matrix),中間層的神經元由兩個輸入層的全連接轉換後求其平均,即第一個輸入層變成 \(h_1\) 、第二個輸入層轉為 \(h_2\) 、中間層為 \(\frac{1}{2}(h_1+h_2)\) 。
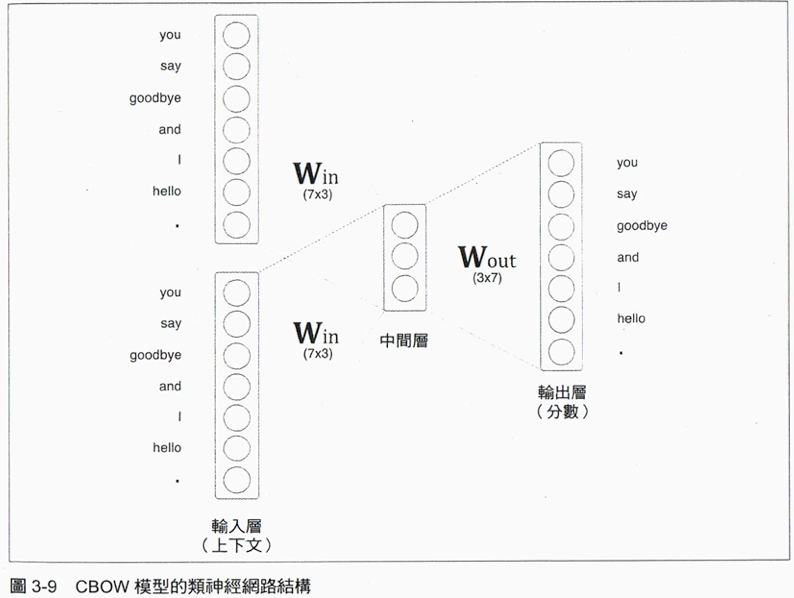
Figure 11: Caption
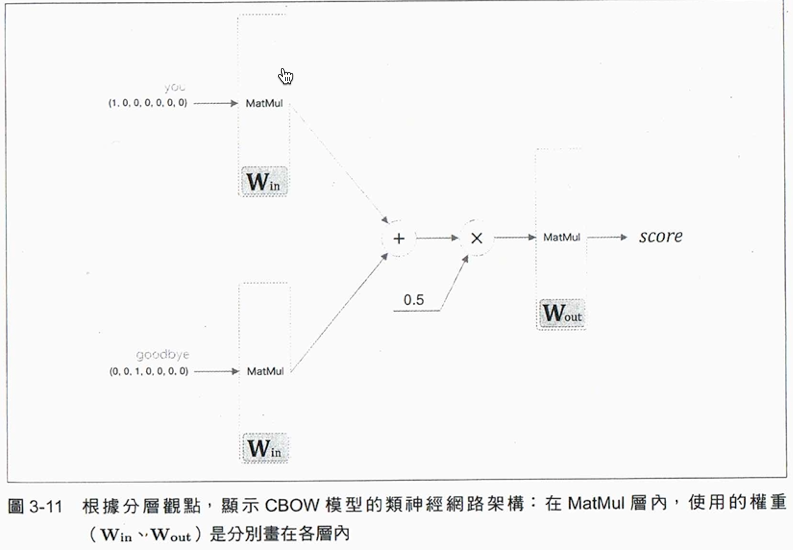
Figure 12: Caption
以輸入you、goodbye兩個字詞為輸入層來看,其計算方式如下:
1: # coding: utf-8 2: import numpy as np 3: from common.layers import MatMul 4: 5: 6: # 樣本的上下文資料 7: c0 = np.array([[1, 0, 0, 0, 0, 0, 0]]) 8: c1 = np.array([[0, 0, 1, 0, 0, 0, 0]]) 9: 10: # 初始化權重W_in = np.random.randn(7, 3) 11: W_in = np.random.randn(7, 3) 12: W_out = np.random.randn(3, 7) 13: # 產生各層 14: in_layer0 = MatMul(W_in) 15: in_layer1 = MatMul(W_in) 16: out_layer = MatMul(W_out) 17: 18: # 正向傳播 19: h0 = in_layer0.forward(c0) 20: h1 = in_layer1.forward(c1) 21: h = 0.5 * (h0 + h1) 22: s = out_layer.forward(h) 23: print(s) 24:
[[-0.72028045 -0.02070112 0.71300738 0.57026871 -0.4409504 -3.70044407 -0.27397258]]
9.5. CBOW模型的學習
求出中間層的各神經元內容值後,再透過另一個輸出weight matrix加權計算即可得輸出層,最後經由Softmax函數將每一字詞的機率轉換為正解label,其流程如下所示:
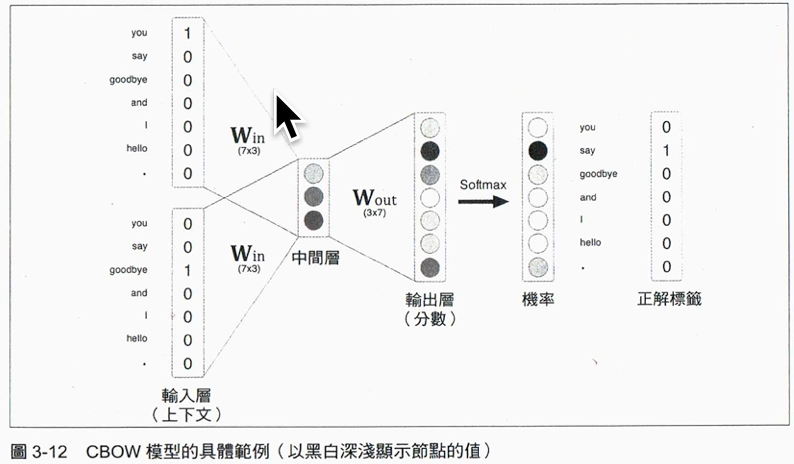
如上例,若前後文為you、goodbye,則其label應為say;在一個擁有優質weight matrix的類神經網路中,我們可以期待對應到正解的神經元「機率」變高。
這件事可以透過數學手段來解決:利用Softmax把分數轉成機率,從機率與label求出交叉熵誤差,把它當成損失函數(loss function),學習目標就是找出能將中oss function值最小化的那組weight matrix。
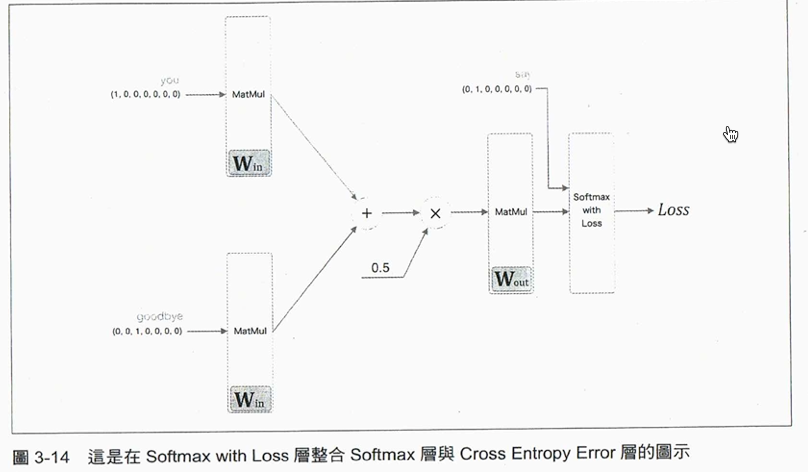
Figure 13: Caption
10. word2vec的學習
10.1. 先找出上下文與目標對象

Figure 14: Caption
10.2. 將上下文與目標以one-hot encoding編碼
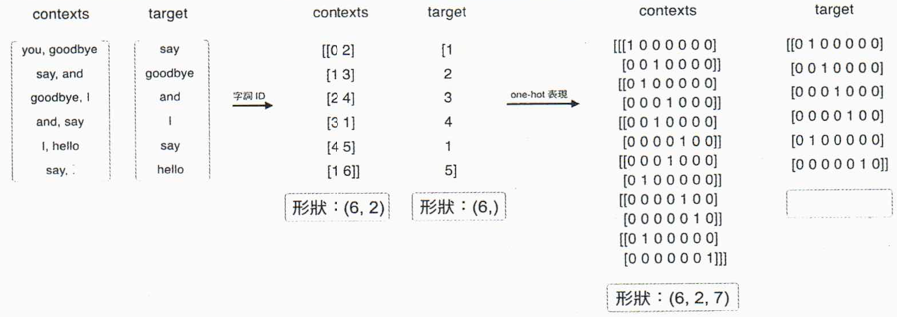
Figure 15: Caption
10.3. 執行CBOW模型
1: # coding: utf-8 2: import sys 3: sys.path.append('..') 4: import numpy as np 5: from common.layers import MatMul, SoftmaxWithLoss 6: 7: 8: class SimpleCBOW: 9: def __init__(self, vocab_size, hidden_size): 10: V, H = vocab_size, hidden_size 11: 12: # 初始化權重 13: W_in = 0.01 * np.random.randn(V, H).astype('f') 14: W_out = 0.01 * np.random.randn(H, V).astype('f') 15: 16: # 產生各層 17: self.in_layer0 = MatMul(W_in) 18: self.in_layer1 = MatMul(W_in) 19: self.out_layer = MatMul(W_out) 20: self.loss_layer = SoftmaxWithLoss() 21: 22: # 把全部的權重與梯度整合成清單 23: layers = [self.in_layer0, self.in_layer1, self.out_layer] 24: self.params, self.grads = [], [] 25: for layer in layers: 26: self.params += layer.params 27: self.grads += layer.grads 28: 29: # 在成員變數中,設定字詞的分散式表示 self.word_vecs = W_in 30: 31: def forward(self, contexts, target): 32: h0 = self.in_layer0.forward(contexts[:, 0]) 33: h1 = self.in_layer1.forward(contexts[:, 1]) 34: h = (h0 + h1) * 0.5 35: score = self.out_layer.forward(h) 36: loss = self.loss_layer.forward(score, target) 37: return loss 38: 39: def backward(self, dout=1): 40: ds = self.loss_layer.backward(dout) 41: da = self.out_layer.backward(ds) 42: da *= 0.5 43: self.in_layer1.backward(da) 44: self.in_layer0.backward(da) 45: return None 46:
- forward()取得contexts與target兩個引數,回傳loss
- contexts為三維NumPy陣列,形狀為圖15中的(6, 2, 7),表示有6個batch、上下文參考window size為2、人ne-hot encoding向量長度為7。
- target為二維,假設形狀為(6, 7)
- contexts為三維NumPy陣列,形狀為圖15中的(6, 2, 7),表示有6個batch、上下文參考window size為2、人ne-hot encoding向量長度為7。
- backward()執行反向傳播
反向傳播由圖16中的最右「1」開始,將之輸入Softmax with Loss層、再把Softmax with Loss層的反向輸出當作ds、將ds做為MatMul層的輸入。
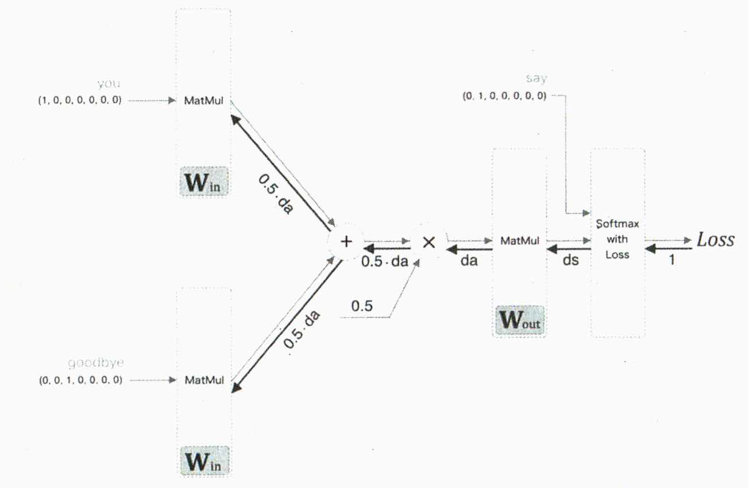
Figure 16: Caption
- 學習
這段找別的書來看,這本書用太多自己寫的code,麻煩,意義不太大
11. NLP實作: Fake News Classification
- 本段所有內容來自進入 NLP 世界的最佳橋樑:寫給所有人的自然語言處理與深度學習入門指南
- WSDM - Fake News Classification
此競賽的目的在於想辦法自動找出假新聞以節省人工檢查的成本。資料集則是由中國的手機新聞應用:今日頭條的母公司字節跳動所提出的。(知名的抖音也是由該公司的產品)6
11.1. 資料集
訓練資料集(Training Set)約有 32 萬筆數據、測試資料集(Test Set)則約為 8 萬筆。
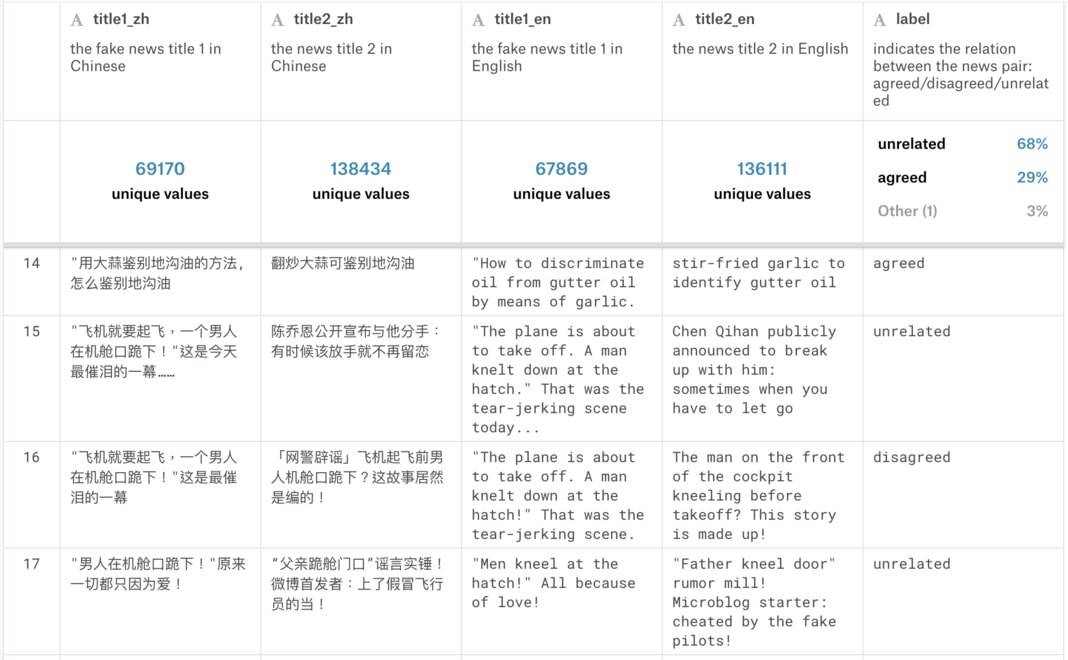
要了解此資料集,讓我們先專注在第一列(Row),大蒜與地溝油新聞的每一個欄位。
- 第一欄位 title1_zh 代表的是「已知假新聞」 A 的中文標題:用大蒜鉴别地沟油的方法,怎么鉴别地沟油
- 而第二欄位 title2_zh 則是一筆新的新聞 B 的中文標題,我們還不知道它的真偽:翻炒大蒜可鉴别地沟油
要判斷第二欄中的新聞標題是否為真,我們可以把它跟已知的第一篇假新聞做比較,分為 3 個類別:
- unrelated:B 跟 A 沒有關係
- agreed:B 同意 A 的敘述
- disagreed:B 不同意 A 的敘述
如果新聞 B 同意假新聞 A 的敘述的話,我們可以將 B 也視為一個假新聞;而如果 B 不同意假新聞 A 的敘述的話,我們可以放心地將 B 新聞釋出給一般大眾查看;如果 B 與 A 無關的話,可以考慮再進一步處理 B。
第 3、 4 欄位則為新聞標題的英文翻譯。而因為該翻譯為 機器翻譯 , 不一定能 100% 正確反映本來中文新聞想表達的意思 ,因此接下來的文章會忽視這兩個欄位,只使用簡體中文的新聞標題來訓練 NLP 模型。
11.2. 思路
現在任務目標: 要將有 32 萬筆數據的訓練資料集(Training Set)交給我們的 NLP 模型,讓它「閱讀」每一列裡頭的假新聞 A 與新聞 B 的標題並瞭解它們之間的關係(不相關、B 同意 A、B 不同意 A)。這是一個非常典型的機器學習(Machine Learning, ML)問題。我們當然希望不管使用什麼樣的模型,該模型都能夠幫我們減少人工檢查的成本,並同時最大化分類的準確度。
- 觀察資料集
訓練集中的三個類別比例如下:
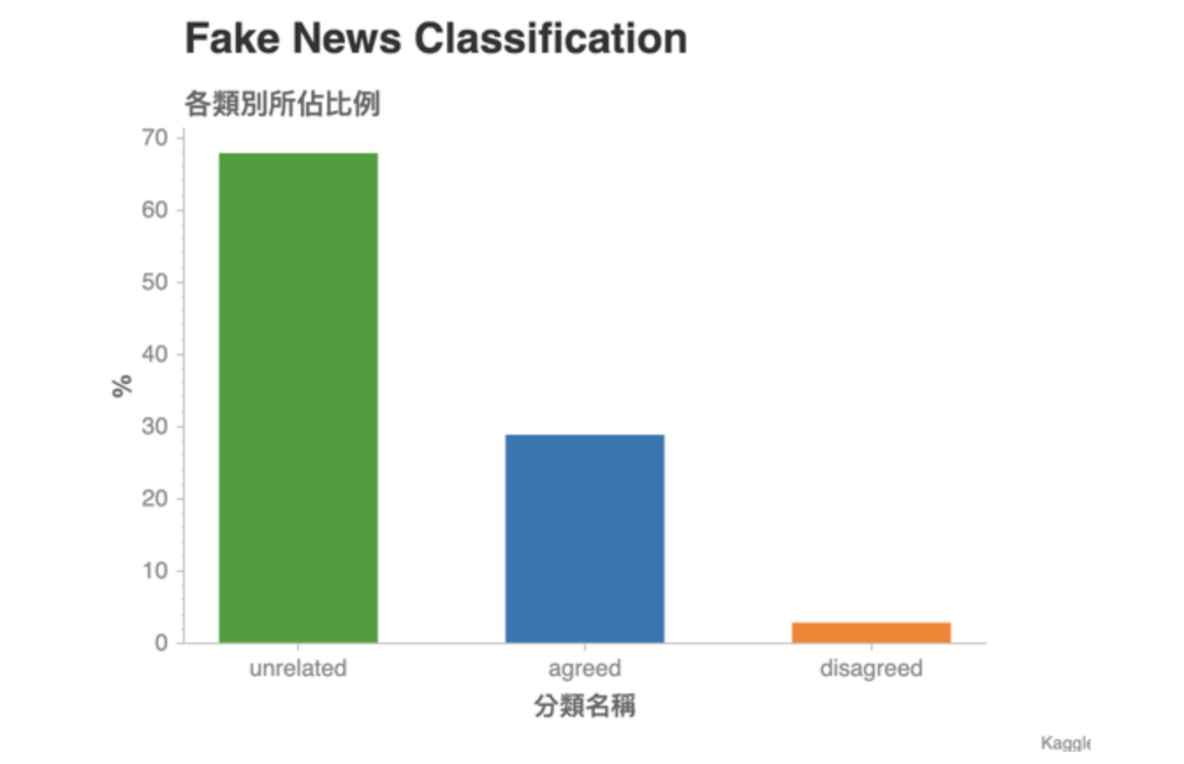
Figure 17: Caption
- 這張圖顯示了訓練資料集(Training Set)裏頭各個分類所佔的比例。是一個常見的 Unbalanced Dataset:特定的分類佔了數據的大半比例。
- 現在假設測試資料集(Test Set)的數據分佈跟訓練資料集相差不遠,且衡量一個分類模型的指標是準確度(Accuracy):100 組成對新聞中,模型猜對幾組。
- 這時候如果要你用一個簡單法則來分類所有成對新聞,並同時最大化準確度,你會怎麼做?
- 對沒錯,就是全部猜 unrelated 就對了!
此競賽採用Weighted Categorization Accuracy做為效能評估依據:
\[ WeightedAccuracy(y, \hat{y}, \omega) = \frac{1}{n} \displaystyle{\sum_{i=1}^{n}} \frac{{\omega}_i(y_i=\hat{y}_i)}{\sum {\omega}_i} \]
where
- \(y\) are ground truths
- \(\hat y\) are the predicted results
- \(\omega_i\) 為資料庫中第 \(i\) 個項目的權重
- 這張圖顯示了訓練資料集(Training Set)裏頭各個分類所佔的比例。是一個常見的 Unbalanced Dataset:特定的分類佔了數據的大半比例。
11.3. 資料前處理:讓機器能夠處理文字
即,如何將
用大蒜鉴别地沟油的方法,怎么鉴别地沟油
轉換成人腦不易理解,但很「機器友善」的數字序列(Sequence of Numbers):
[217, 1268, 32, 1178, 25, 489, 116]
資料型態轉換流程:
- 讀入資料
先讓我們用 Pandas 將訓練資料集讀取進來
1: import pandas as pd 2: train = pd.read_csv("./dataset/fakeNews.train.csv", index_col=0, encoding='utf-8', dtype=str) 3: #train = pd.read_csv(TRAIN_CSV_PATH, index_col=0) 4: print(train.head(3))
tid1 tid2 ... title2_en label id ... 0 0 1 ... Police disprove "bird's nest congress each per... unrelated 3 2 3 ... Shenzhen's GDP outstrips Hong Kong? Shenzhen S... unrelated 1 2 4 ... The GDP overtopped Hong Kong? Shenzhen clarifi... unrelated [3 rows x 7 columns]
為了畫面簡潔,讓我們只選取 2 個中文新聞標題以及分類結果(Label)的欄位:
1: cols = ['title1_zh', 2: 'title2_zh', 3: 'label'] 4: train = train.loc[:, cols] 5: print(train.columns) 6: print(train.head(3))
Index(['title1_zh', 'title2_zh', 'label'], dtype='object') title1_zh title2_zh label id 0 2017养老保险又新增两项,农村老人人人可申领,你领到了吗 警方辟谣“鸟巢大会每人领5万” 仍有老人坚持进京 unrelated 3 "你不来深圳,早晚你儿子也要来",不出10年深圳人均GDP将超香港 深圳GDP首超香港?深圳统计局辟谣:只是差距在缩小 unrelated 1 "你不来深圳,早晚你儿子也要来",不出10年深圳人均GDP将超香港 GDP首超香港?深圳澄清:还差一点点…… unrelated有了必要的欄位以後,我們可以開始進行數據的前處理了。
- 文本分詞(Text Segmentation)
文本分詞(Text Segmentation)是一個將一連串文字切割成多個有意義的單位的步驟。這單位可以是
- 一個中文漢字 / 英文字母(Character)
- 一個中文詞彙 / 英文單字(Word)
- 一個中文句子 / 英文句子(Sentence)
以英文來說,Word Segmentation 十分容易。通常只要依照空白分割,就能得到一個有意義的詞彙列表了(在這邊讓我們先無視標點符號):
1: text = 'I am Meng Lee, a data scientist based in Tokyo.' 2: words = text.split(' ') 3: print(words)
['I', 'am', 'Meng', 'Lee,', 'a', 'data', 'scientist', 'based', 'in', 'Tokyo.']
但很明顯地,中文無法這樣做。這時候我們將藉助 Jieba 這個中文斷詞工具,來為一連串的文字做有意義的切割:
1: import jieba.posseg as pseg 2: 3: text = '我是李孟,在東京工作的數據科學家' 4: words = pseg.cut(text) 5: print([word for word in words])
[pair('我', 'r'), pair('是', 'v'), pair('李孟', 'nr'), pair(',', 'x'), pair('在', 'p'), pair('東京', 'ns'), pair('工作', 'vn'), pair('的', 'uj'), pair('數據', 'n'), pair('科學家', 'n')]如上所示,Jieba 將我們的中文文本切成有意義的詞彙列表,並為每個詞彙附上對應的詞性(Flag)。
假設我們不需要標點符號,則只要將 flag == x 的詞彙去除即可。
1: import jieba.posseg as pseg 2: 3: text = '我是李孟,在東京工作的數據科學家' 4: words = pseg.cut(text) 5: print([(x.word, x.flag) for x in words])
[('我', 'r'), ('是', 'v'), ('李孟', 'nr'), (',', 'x'), ('在', 'p'), ('東京', 'ns'), ('工作', 'vn'), ('的', 'uj'), ('數據', 'n'), ('科學家', 'n')]我們可以寫一個很簡單的 Jieba 斷詞函式,此函式能將輸入的文本 text 斷詞,並回傳除了標點符號以外的詞彙列表:
1: import jieba.posseg as pseg 2: 3: def jieba_tokenizer(text): 4: words = pseg.cut(text) 5: return ' '.join([word for word, flag in words if flag != 'x']) 6: 7: text = '我是李孟,在東京工作的數據科學家' 8: print(jieba_tokenizer(text))
Building prefix dict from the default dictionary ... Dumping model to file cache /var/folders/cb/t4v0kdcj6fj20jdzljy7y9240000gn/T/jieba.cache Loading model cost 0.706 seconds. Prefix dict has been built successfully. 我 是 李孟 在 東京 工作 的 數據 科學家
我們可以利用 Pandas 的 apply 函式,將 jieba_tokenizer 套用到所有新聞標題 A 以及 B 之上,做文本分詞:
1: import pandas as pd 2: import jieba.posseg as pseg 3: 4: train = pd.read_csv("./dataset/fakeNews.train.csv", index_col=0, encoding='utf-8', dtype=str) 5: 6: cols = ['title1_zh', 7: 'title2_zh', 8: 'label'] 9: train = train.loc[:, cols] 10: 11: def jieba_tokenizer(text): 12: words = pseg.cut(text) 13: return ' '.join([word for word, flag in words if flag != 'x']) 14: 15: print(train.columns) 16: train['title1_tokenized'] = train.loc[:, 'title1_zh'].astype(str).apply(jieba_tokenizer) 17: train['title2_tokenized'] = train.loc[:, 'title2_zh'].astype(str).apply(jieba_tokenizer) 18: print(train.columns)
Index(['title1_zh', 'title2_zh', 'label'], dtype='object') Index(['title1_zh', 'title2_zh', 'label', 'title1_tokenized', 'title2_tokenized'], dtype='object')新聞標題 A 的斷詞結果如下:
1: print(train.iloc[:, [0, 3]].head())
title1_zh title1_tokenized id 0 2017养老保险又新增两项,农村老人人人可申领,你领到了吗 2017 养老保险 又 新增 两项 农村 老人 人人 可 申领 你 领到 了 吗 3 "你不来深圳,早晚你儿子也要来",不出10年深圳人均GDP将超香港 你 不 来 深圳 早晚 你 儿子 也 要 来 不出 10 年 深圳 人均 GDP 将 超 香港 1 "你不来深圳,早晚你儿子也要来",不出10年深圳人均GDP将超香港 你 不 来 深圳 早晚 你 儿子 也 要 来 不出 10 年 深圳 人均 GDP 将 超 香港 2 "你不来深圳,早晚你儿子也要来",不出10年深圳人均GDP将超香港 你 不 来 深圳 早晚 你 儿子 也 要 来 不出 10 年 深圳 人均 GDP 将 超 香港 9 "用大蒜鉴别地沟油的方法,怎么鉴别地沟油 用 大蒜 鉴别 地沟油 的 方法 怎么 鉴别 地沟油新聞標題 B 的結果則為:
1: print(train.iloc[:, [1, 4]].head())
title2_zh title2_tokenized id 0 警方辟谣“鸟巢大会每人领5万” 仍有老人坚持进京 警方 辟谣 鸟巢 大会 每人 领 5 万 仍 有 老人 坚持 进京 3 深圳GDP首超香港?深圳统计局辟谣:只是差距在缩小 深圳 GDP 首 超 香港 深圳 统计局 辟谣 只是 差距 在 缩小 1 GDP首超香港?深圳澄清:还差一点点…… GDP 首 超 香港 深圳 澄清 还 差 一点点 2 去年深圳GDP首超香港?深圳统计局辟谣:还差611亿 去年 深圳 GDP 首 超 香港 深圳 统计局 辟谣 还 差 611 亿 9 吃了30年食用油才知道,一片大蒜轻松鉴别地沟油 吃 了 30 年 食用油 才 知道 一片 大蒜 轻松 鉴别 地沟油 - 一個中文漢字 / 英文字母(Character)
- 建立字典並將文本轉成數字序列
當我們將完整的新聞標題切成一個個有意義的詞彙(Token)以後,下一步就是將這些詞彙轉換成一個數字序列,方便電腦處理。
這些數字是所謂的索引(Index),分別對應到特定的詞彙。
假設我們現在就只有一個新聞標題:
狐狸被陌生人拍照
我們首先會對此標題做斷詞,將句子分成多個有意義的詞彙:
1: import jieba.posseg as pseg 2: text = '狐狸被陌生人拍照' 3: words = pseg.cut(text) 4: words = [w for w, f in words] 5: print(words)
['狐狸', '被', '陌生人', '拍照']
有了詞彙的列表以後,我們可以建立一個字典 word_index。
該 dict 裏頭將上面的 4 個詞彙當作鍵值(Key),每個鍵值對應的值(Value)則為不重複的數字:
1: word_index = { 2: word: idx 3: for idx, word in enumerate(words) 4: } 5: print(word_index)
{'狐狸': 0, '被': 1, '陌生人': 2, '拍照': 3}有了這個字典以後,我們就能把該句子轉成一個數字序列:
1: print(words) 2: print([word_index[w] for w in words])
['狐狸', '被', '陌生人', '拍照'] [0, 1, 2, 3]
如果來了一個新的句子:
陌生人被狐狸拍照
我們也能利用手上已有的字典 word_index 如法炮製:
1: text = '陌生人被狐狸拍照' 2: words = pseg.cut(text) 3: words = [w for w, f in words] 4: print(words) 5: print([word_index[w] for w in words])
['陌生人', '被', '狐狸', '拍照'] [2, 1, 0, 3]
在這個簡單的狐狸例子裡頭,word_index 就是我們的字典;我們利用該字典,將 1 句話轉成包含多個數字的序列,而每個數字實際上代表著一個 Token。
- 如何將新聞標題轉為數字序列
- 將已被斷詞的新聞標題 A 以及新聞標題 B 全部倒在一起
- 建立一個空字典
- 查看所有新聞標題,裏頭每出現一個字典裡頭沒有的詞彙,就為該詞彙指定一個字典裡頭還沒出現的索引數字,並將該詞彙放入字典
- 利用建好的字典,將每個新聞標題裡頭包含的詞彙轉換成數字
- 步驟1: 將已被斷詞的新聞標題 A 以及新聞標題 B 全部倒在一起
上述步驟幾乎是NLP的必要動作,許多套件都提供了相應的function,如Keras
1: import keras 2: MAX_NUM_WORDS = 10000 3: tokenizer = keras.preprocessing.text.Tokenizer(num_words=MAX_NUM_WORDS)
Tokenizer 顧名思義,即是將一段文字轉換成一系列的詞彙(Tokens),並為其建立字典。這邊的 num_words=10000 代表我們限制字典只能包含 10,000 個詞彙,一旦字典達到這個大小以後,剩餘的新詞彙都會被視為 Unknown,以避免字典過於龐大。
如同上述的步驟 1,我們得將新聞 A 及新聞 B 的標題全部聚集起來,為它們建立字典:
1: corpus_x1 = train.title1_tokenized 2: corpus_x2 = train.title2_tokenized 3: corpus = pd.concat([ 4: corpus_x1, corpus_x2]) 5: print(corpus.shape)
(641104,)
因為訓練集有大約 32 萬列(Row)的成對新聞(每一列包含 2 筆新聞:A & B),因此將所有新聞放在一起的話,就有 2 倍的大小。而這些文本的集合在習慣上被稱作語料庫(Text Corpus),代表著我們有的所有文本數據。以下是我們語料庫的一小部分:
1: print(pd.DataFrame(corpus.iloc[14:19], columns=['title']))
title id 15 飞机 就要 起飞 一个 男人 在 机舱 口 跪下 这 是 今天 最 催泪 的 一幕 17 飞机 就要 起飞 一个 男人 在 机舱 口 跪下 这 是 最 催泪 的 一幕 14 男人 在 机舱 口 跪下 原来 一切 都 只 因为 爱 16 飞机 就要 起飞 一个 男人 在 机舱 口 跪下 这 是 今天 最 催泪 的 一幕 18 飞机 就要 起飞 一个 男人 在 机舱 口 跪下 这 是 见 过 最 催泪 的 一幕 - 步驟2,3: 呼叫 tokenizer 為我們查看所有文本,並建立一個字典
1: tokenizer.fit_on_texts(corpus)以我們的語料庫大小來說,這大約需時 10 秒鐘。而等到 tokenizer 建好字典以後,我們可以進行上述第 4 個步驟,請 tokenizer 利用內部生成的字典分別將我們的新聞標題 A 與 新聞 B 轉換成數字序列:
1: x1_train = tokenizer.texts_to_sequences(corpus_x1) 2: x2_train = tokenizer.texts_to_sequences(corpus_x2) 3: print(len(x1_train)) 4: print(x1_train[:1]) 5: print(pd.DataFrame(corpus.iloc[:1], columns=['title']))
320552 [[217, 1268, 32, 1178, 5967, 25, 489, 2877, 116, 5559, 4, 1850, 2, 13]] title id 0 2017 养老保险 又 新增 两项 农村 老人 人人 可 申领 你 领到 了 吗x1_train 為一個 Python list,裡頭包含了每一筆假新聞標題 A 對應的數字序列。
讓我們利用 tokenizer.index_word 來將索引數字對應回本來的詞彙:
1: for seq in x1_train[:1]: 2: print([tokenizer.index_word[idx] for idx in seq])
['2017', '养老保险', '又', '新增', '两项', '农村', '老人', '人人', '可', '申领', '你', '领到', '了', '吗']
- 將已被斷詞的新聞標題 A 以及新聞標題 B 全部倒在一起
- 序列的 Zero Padding
雖然我們已經將每個新聞標題的文本轉為一行行的數字序列,你會發現每篇標題的序列長度並不相同:
1: for seq in x1_train[:10]: 2: print(len(seq), seq[:5], ' ...')
14 [217, 1268, 32, 1178, 5967] ... 19 [4, 10, 47, 678, 2558] ... 19 [4, 10, 47, 678, 2558] ... 19 [4, 10, 47, 678, 2558] ... 9 [31, 320, 3372, 3062, 1] ... 19 [4, 10, 47, 678, 2558] ... 6 [7, 2221, 1, 2072, 7] ... 19 [4, 10, 47, 678, 2558] ... 14 [1281, 1211, 427, 3, 3245] ... 9 [31, 320, 3372, 3062, 1] ...
而為了方便之後的 NLP 模型處理(見循環神經網路一章),一般會設定一個 MAX_SEQUENCE_LENGTH 來讓所有序列的長度一致。長度超過此數字的序列尾巴會被刪掉;而針對原來長度不足的序列,我們則會在詞彙前面補零。Keras 一樣有個方便函式 pad_sequences 來幫助我們完成這件工作:
1: MAX_SEQUENCE_LENGTH = 20 2: x1_train = keras.preprocessing.sequence.pad_sequences(x1_train, 3: maxlen=MAX_SEQUENCE_LENGTH) 4: 5: x2_train = keras.preprocessing.sequence.pad_sequences(x2_train, 6: maxlen=MAX_SEQUENCE_LENGTH) 7: for seq in x1_train[:3]: 8: print(len(seq), seq[:5], ' ...') 9: for seq in x2_train[:3]: 10: print(len(seq), seq[:5], ' ...') 11: print(f'Zero Padding後x1_train[0]的內容:{x1_train[0]}')
20 [0 0 0 0 0] ... 20 [ 0 4 10 47 678] ... 20 [ 0 4 10 47 678] ... 20 [0 0 0 0 0] ... 20 [0 0 0 0 0] ... 20 [0 0 0 0 0] ... Zero Padding後x1_train[0]的內容:[ 0 0 0 0 0 0 217 1268 32 1178 5967 25 489 2877 116 5559 4 1850 2 13]
其中,x1_train[0]因為長度不足20(只有14),故前6項被補0,所有的新聞標題也是:
1: for seq in x1_train + x2_train: 2: assert len(seq) == 20 3: 4: print("所有新聞標題的序列長度皆為 20 !")
所有新聞標題的序列長度皆為 20 !
1: print(x1_train[:3])
[[ 0 0 0 0 0 0 217 1268 32 1178 5967 25 489 2877 116 5559 4 1850 2 13] [ 0 4 10 47 678 2558 4 166 34 17 47 5150 63 15 678 4502 3211 23 284 1181] [ 0 4 10 47 678 2558 4 166 34 17 47 5150 63 15 678 4502 3211 23 284 1181]]
接下來要處理label
- 將正解做 One-hot Encoding
1: print(train.label[:5])
id 0 unrelated 3 unrelated 1 unrelated 2 unrelated 9 agreed Name: label, dtype: object
label 的處理相對簡單。跟新聞標題相同,我們一樣需要一個字典將分類的文字轉換成索引:
1: import numpy as np 2: 3: # 定義每一個分類對應到的索引數字 4: label_to_index = { 5: 'unrelated': 0, 6: 'agreed': 1, 7: 'disagreed': 2 8: } 9: 10: # 將分類標籤對應到剛定義的數字 11: y_train = train.label.apply( 12: lambda x: label_to_index[x]) 13: 14: y_train = np.asarray(y_train).astype('float32') 15: print(y_train[:20])
[0. 0. 0. 0. 1. 0. 0. 0. 0. 1. 1. 1. 1. 1. 0. 2. 0. 0. 0. 0.]
現在每個分類的文字標籤都已經被轉成對應的數字,接著讓我們利用 Keras 做 One Hot Encoding:
1: #from tensorflow.keras.utils import to_categorical 2: from keras.utils import np_utils 3: y_train = np_utils.to_categorical(y_train) 4: print(y_train[:5])
[[1. 0. 0.] [1. 0. 0.] [1. 0. 0.] [1. 0. 0.] [0. 1. 0.]]
上述矩陣的每一列即為 1 個 label,而你可以看到現在每個 label 都從 1 個數字變成一個 3 維的向量(Vector)。每 1 維度則對應到 1 個分類:
- [1, 0, 0] 代表 label 為 unrelated
- [0, 1, 0] 代表 label 為 agreed
- [0, 0, 1] 代表 label 為 disagreed
用這樣的方式表達 label 的好處是我們可以把分類結果想成機率分佈。[1, 0, 0] 就代表一組新聞標題 A、B 為 unrelated 的機率等於 100 %;假設預測的結果為[0.7, 0.2, 0.1],則代表模型認為這 2 個新聞標題的關係有 70 % 的機率為 unrelated、20 % 的機率是 agreed 而 10 % 為 disagreed。
- [1, 0, 0] 代表 label 為 unrelated
- 切割訓練資料集 & 驗證資料集
- 驗證集: 我們會反覆在 Train / Valid Set 上訓練並測試模型,最後用 Test Set 一決生死,至於驗證集的必要,簡而言之,當你多次利用驗證資料集的預測結果以修正模型,並讓它在該資料集表現更好時,過適(Overfitting)的風險就已經產生了。
- 測試集: 儘管你沒有直接讓模型看到驗證資料集(Validation Set)內的任何數據,你還是間接地洩漏了該資料集的重要資訊:你讓模型知道怎樣的參數設定會讓它在該資料集表現比較好,亦或表現較差。因此有一個完全跟模型訓練過程獨立的測試資料集(Test Set)就顯得重要許多了。
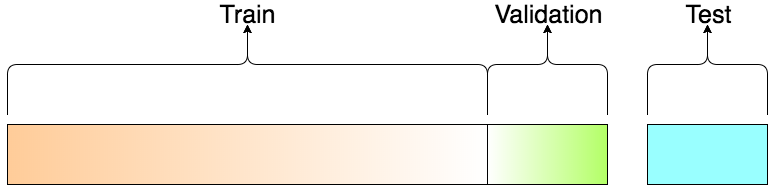
要切訓練資料集 / 驗證資料集,scikit-learn 中的 train_test_split 函式是一個不錯的選擇:
1: from sklearn.model_selection import train_test_split 2: 3: VALIDATION_RATIO = 0.1 4: # 小彩蛋 5: RANDOM_STATE = 9527 6: 7: x1_train, x1_val, x2_train, x2_val, y_train, y_val = train_test_split( 8: x1_train, x2_train, y_train, 9: test_size=VALIDATION_RATIO, 10: random_state=RANDOM_STATE 11: )
在這邊,我們分別將新聞標題 A x1_train、新聞標題 B x2_train 以及分類標籤 y_train 都分成兩個部分:訓練部分 & 驗證部分。
以假新聞 A 的標題 x1_train 為例,本來完整 32 萬筆的 x1_train 會被分為包含 90 % 數據的訓練資料集 x1_train 以及 10 % 的驗證資料集 x1_val。
1: print("Training Set") 2: print("-" * 10) 3: print(f"x1_train: {x1_train.shape}") 4: print(f"x2_train: {x2_train.shape}") 5: print(f"y_train : {y_train.shape}") 6: 7: print("-" * 10) 8: print(f"x1_val: {x1_val.shape}") 9: print(f"x2_val: {x2_val.shape}") 10: print(f"y_val : {y_val.shape}") 11: print("-" * 10) 12: print("Test Set")
Training Set ---------- x1_train: (288496, 20) x2_train: (288496, 20) y_train : (288496, 3) ---------- x1_val: (32056, 20) x2_val: (32056, 20) y_val : (32056, 3) ---------- Test Set
我們可以看到,切割後的訓練資料集有 288,488 筆資料。每一筆資料裡頭,成對新聞標題 A & B 的長度皆為 20 個 Tokens,分類結果則有 3 個;驗證資料集的內容一模一樣,僅差在資料筆數較少(32,055 筆)。
到此為此,資料前處理大功告成!
- 驗證集: 我們會反覆在 Train / Valid Set 上訓練並測試模型,最後用 Test Set 一決生死,至於驗證集的必要,簡而言之,當你多次利用驗證資料集的預測結果以修正模型,並讓它在該資料集表現更好時,過適(Overfitting)的風險就已經產生了。
11.4. RNN
RNN 是一種有「記憶力」的神經網路,其最為人所知的形式如下:
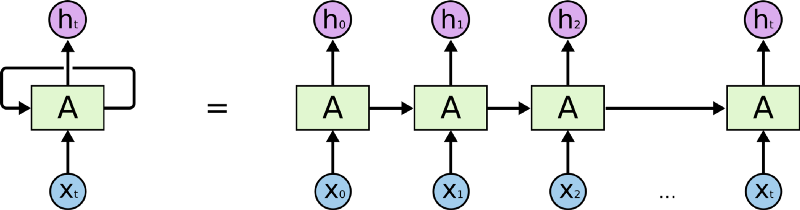
如同上圖等號左側所示,RNN 跟一般深度學習中常見的前饋神經網路(Feedforward Neural Network, 後簡稱 FFNN)最不一樣的地方在於它有一個迴圈(Loop)。
要了解這個迴圈在 RNN 裏頭怎麼運作,現在讓我們想像有一個輸入序列 X(Input Sequence)其長相如下:
\[ X = [ x_0, x_1, x_2, \dots x_t ]\]
- 不同於 FFNN,RNN 在第一個時間點 \(t_0\) 並不會直接把整個序列 \(X\) 讀入。反之,在第一個時間點 \(t_0\),它只將該序列中的第一個元素 \(x_0\) 讀入中間的細胞 A。細胞 A 則會針對 \(x_0\) 做些處理以後,更新自己的「狀態」並輸出第一個結果 \(h_0\) 。
- 在下個時間點 \(t_1\),RNN 如法炮製,讀入序列 \(X\) 中的下一個元素 \(x_1\),並利用剛剛處理完 \(x_0\) 得到的細胞狀態,處理 \(x_1\) 並更新自己的狀態(也被稱為記憶),接著輸出另個結果 \(h_1\)。
- 剩下的 \(x_t\) 都會被以同樣的方式處理。但不管輸入的序列 \(X\) 有多長,RNN 的本體從頭到尾都是等號左邊的樣子:迴圈代表細胞 A 利用「上」一個時間點(比方說 \(t_1\))儲存的狀態,來處理當下的輸入(比方說 \(x_2\) )。
但如果你將不同時間點(\(t_0\)、\(t_1\) …)的 RNN 以及它的輸入一起截圖,並把所有截圖從左到右一字排開的話,就會長得像等號右邊的形式。將 RNN 以右邊的形式表示的話,你可以很清楚地了解,當輸入序列越長,向右展開的 RNN 也就越長。(模型也就需要訓練更久時間,這也是為何我們在資料前處理時設定了序列的最長長度)
為了確保你 100 % 理解 RNN,讓我們假設剛剛的序列 X 實際上是一個內容如下的英文問句:
1: X = [ What, time, is, it, ? ]
而且 RNN 已經處理完前兩個元素 What 和 time 了。
則接下來 RNN 會這樣處理剩下的句子:
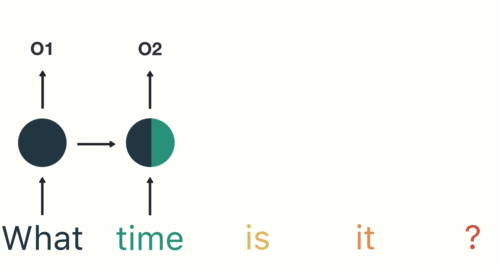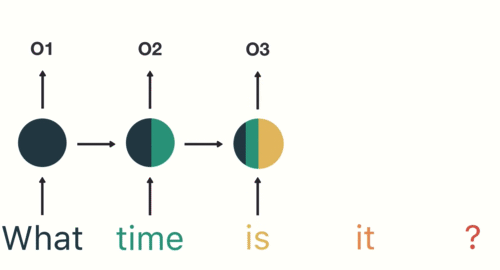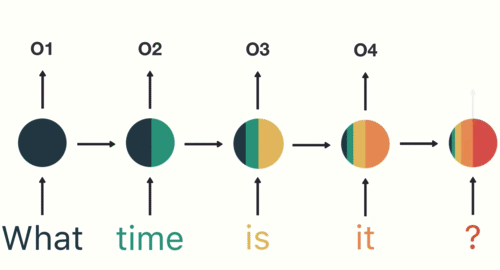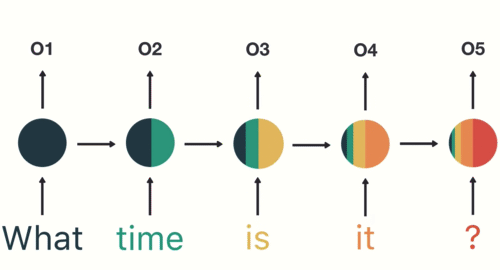
就像你現在閱讀這段話一樣,你是由左到右逐字在大腦裡處理我現在寫的文字,同時不斷地更新你腦中的記憶狀態。
每當下個詞彙映入眼中,你腦中的處理都會跟以下兩者相關:
- 前面所有已讀的詞彙
- 目前腦中的記憶狀態
當然,實際人腦的閱讀機制更為複雜,但 RNN抓到這個處理精髓,利用內在迴圈以及細胞內的「記憶狀態」來處理序列資料。
- RNN實作
1: state_t = 0 2: for input_t in input_sequence: 3: output_t = f(input_t, state_t) 4: state_t = output_t
在 RNN 每次讀入任何新的序列數據前,細胞 A 中的記憶狀態 state_t 都會被初始化為 0。
接著在每個時間點 t,RNN 會重複以下步驟:
- 讀入 input_sequence 序列中的一個新元素 input_t
- 利用 f 函式將當前細胞的狀態 state_t 以及輸入 input_t 做些處理產生 output_t
- 輸出 output_t 並同時更新自己的狀態 state_t
在 Keras 裏頭只要 2 行就可以建立一個 RNN layer:
1: from keras import layers 2: rnn = layers.SimpleRNN()
Figure 18: RNN示例
- 讀入 input_sequence 序列中的一個新元素 input_t
- LSTM
如下的簡易RNN
1: state_t = 0 2: # 細胞 A 會重複執行以下處理 3: for input_t in input_sequence: 4: output_t = f(input_t, state_t) 5: state_t = output_t
要如何將細胞 A 當下的記憶 state_t 與輸入 input_t 結合,才能產生最有意義的輸出 output_t 呢?
在 SimpleRNN 的細胞 A 裡頭,這個 f 的實作很簡單。而這導致其記憶狀態 state_t 沒辦法很好地「記住」前面處理過的序列元素,造成 RNN 在處理後來的元素時,就已經把前面重要的資訊給忘記了。(只有短期記憶,沒有長期記憶)
長短期記憶(Long Short-Term Memory, 後簡稱 LSTM)就是被設計來解決 RNN 的這個問題。如下圖所示,你可以把 LSTM 想成是 RNN 中用來實現細胞 A 內部處理邏輯的一個特定方法:
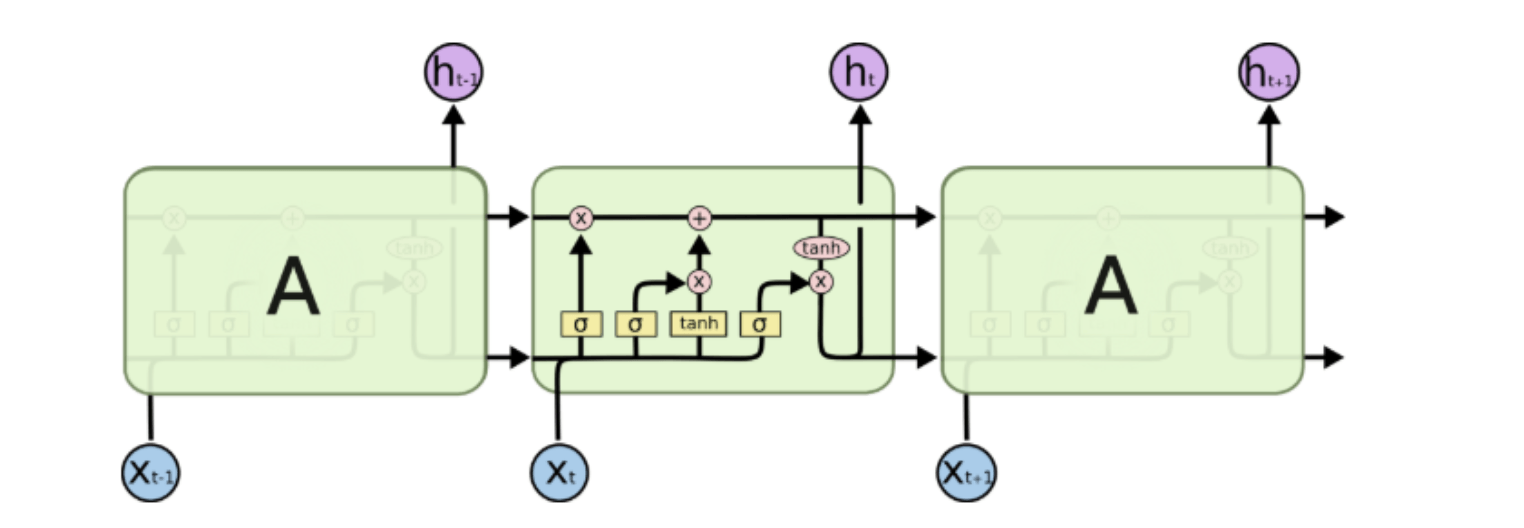
基本上一個 LSTM 細胞裡頭會有 3 個閘門(Gates)來控制細胞在不同時間點的記憶狀態:
- Forget Gate:決定細胞是否要遺忘目前的記憶狀態
- Input Gate:決定目前輸入有沒有重要到值得處理
- Output Gate:決定更新後的記憶狀態有多少要輸出
透過這些閘門控管機制,LSTM 可以將很久以前的記憶狀態儲存下來,在需要的時候再次拿出來使用。值得一提的是,這些閘門的參數也都是神經網路自己訓練出來的。
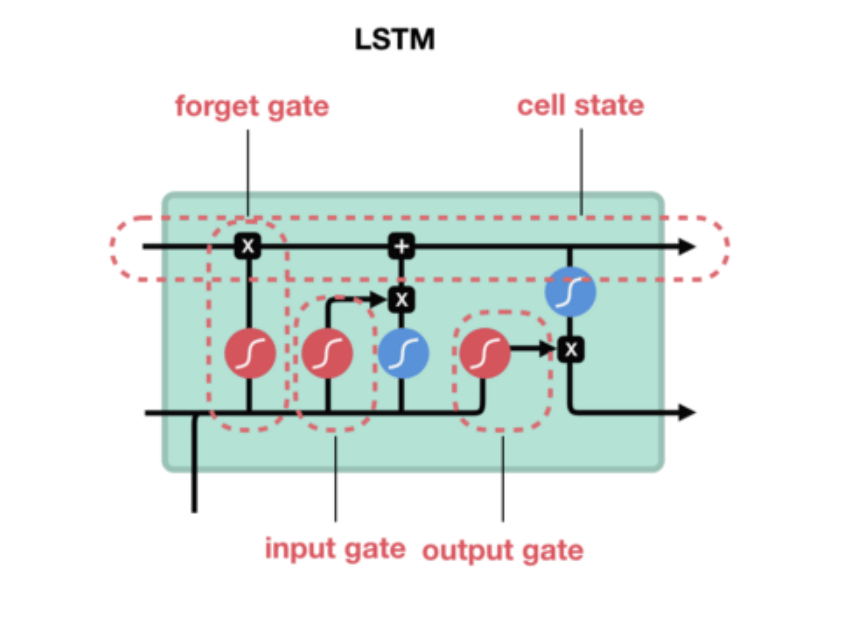
Figure 19: LSTM 細胞頂端那條 cell state 正代表著細胞記憶的轉換過程
想像 LSTM 細胞裡頭的記憶狀態是一個包裹,上面那條直線就代表著一個輸送帶。
LSTM 可以把任意時間點的記憶狀態(包裹)放上該輸送帶,然後在未來的某個時間點將其原封不動地取下來使用。

Figure 20: Caption
因為這樣的機制,讓 LSTM 即使面對很長的序列數據也能有效處理,不遺忘以前的記憶。
因為效果卓越,LSTM 非常廣泛地被使用。事實上,當有人跟你說他用 RNN 做了什麼 NLP 專案時,有 9 成機率他是使用 LSTM 或是 GRU(LSTM 的改良版,只使用 2 個閘門) 來實作,而不是使用最簡單的 SimpleRNN。
- Forget Gate:決定細胞是否要遺忘目前的記憶狀態
11.5. 詞向量:將詞彙表達成有意義的向量¶
訓練資料集裡頭前 5 筆的假新聞標題 A:
1: for i, seq in enumerate(x1_train[:5]): 2: print(f"新聞標題 {i + 1}: ") 3: print(seq) 4: print() 5: print(x1_train.shape)
新聞標題 1:
[ 0 0 0 0 0 4178 2972 9 80 87 717 18 474 4
968 4 823 14 1436 721]
新聞標題 2:
[ 0 0 0 0 0 0 0 0 0 411 308 809 3142 17
90 434 191 3713 1 2]
新聞標題 3:
[ 0 0 0 0 0 0 0 0 0 0 0 5212 5 8867
793 1063 3626 642 337 1172]
新聞標題 4:
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 2832 244 493 393]
新聞標題 5:
[ 0 0 0 0 0 0 0 0 290 143 2523 2380 46 3120
70 243 178 2238 3945 1082]
(288496, 20)
而我們在訓練資料集則總共有 288,488 筆新聞標題,每筆標題如同剛剛所說的,是一個包含 20 個數字的序列。我們可以用 tokenizer 裡頭的字典 index_word 還原文本看看:
1: for i, seq in enumerate(x1_train[:5]): 2: print(f"新聞標題 {i + 1}: ") 3: print([tokenizer.index_word.get(idx, '') for idx in seq]) 4: print()
新聞標題 1: ['', '', '', '', '', '营养师', '补充', '这', '4', '种', '营养', '能', '帮', '你', '降血压', '你', '一样', '都', '不吃', '么'] 新聞標題 2: ['', '', '', '', '', '', '', '', '', '刘涛', '现场', '痛哭', '发飙', '要', '离婚', '直接', '把', '旁边', '的', '了'] 新聞標題 3: ['', '', '', '', '', '', '', '', '', '', '', 'nba', '被', '球星', '诞生', '火箭', '骑士', '同', '抢', '交易'] 新聞標題 4: ['', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '海口', '飞机', '撒药治', '白蛾'] 新聞標題 5: ['', '', '', '', '', '', '', '', '网', '曝', '杜', '海涛', '与', '沈梦辰', '已', '分手', '疑似', '女方', '劈', '腿']
但事實上要讓神經網路能夠處理標題序列內的詞彙,我們要將它們表示成向量(更精準地說,是張量:Tensor),而不是一個單純數字。如果我們能做到這件事情,則 RNN 就能用以下的方式讀入我們的資料:
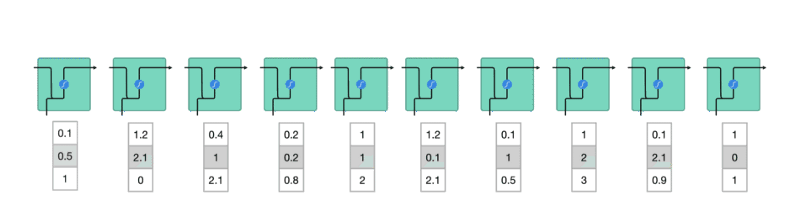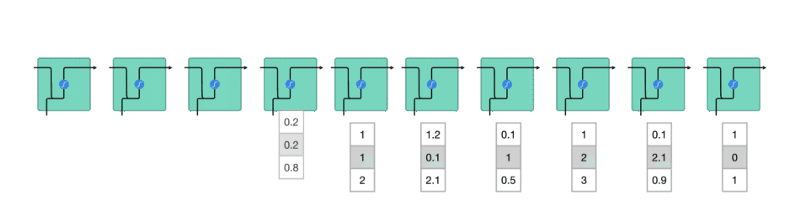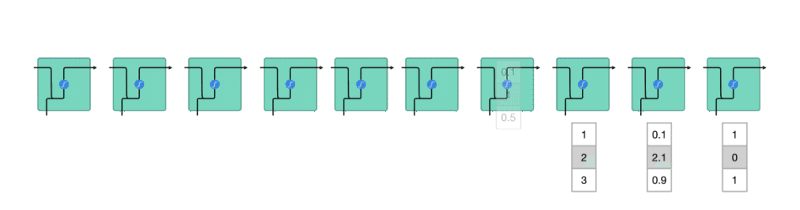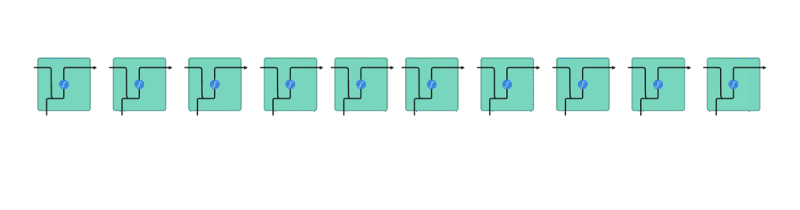
Figure 21: Caption
上圖中,在每個時間點被塞入 RNN 的「詞彙」不再是 1 個數字,而是一個 N 維向量(圖中 N 為 3),所以現在的問題變成:
「要怎麼將一個詞彙表示成一個 N 維向量 ?」
其中一個方法是我們隨便決定一個 N,然後為語料庫裡頭的每一個詞彙都指派一個隨機生成的 N 維向量。假設我們現在有 5 個詞彙:
- 野狼
- 老虎
- 狗
- 貓
- 喵咪
依照剛剛說的方法,我們可以設定 N = 2,並為每個詞彙隨機分配一個 2 維向量後將它們畫在一個平面空間裡頭:
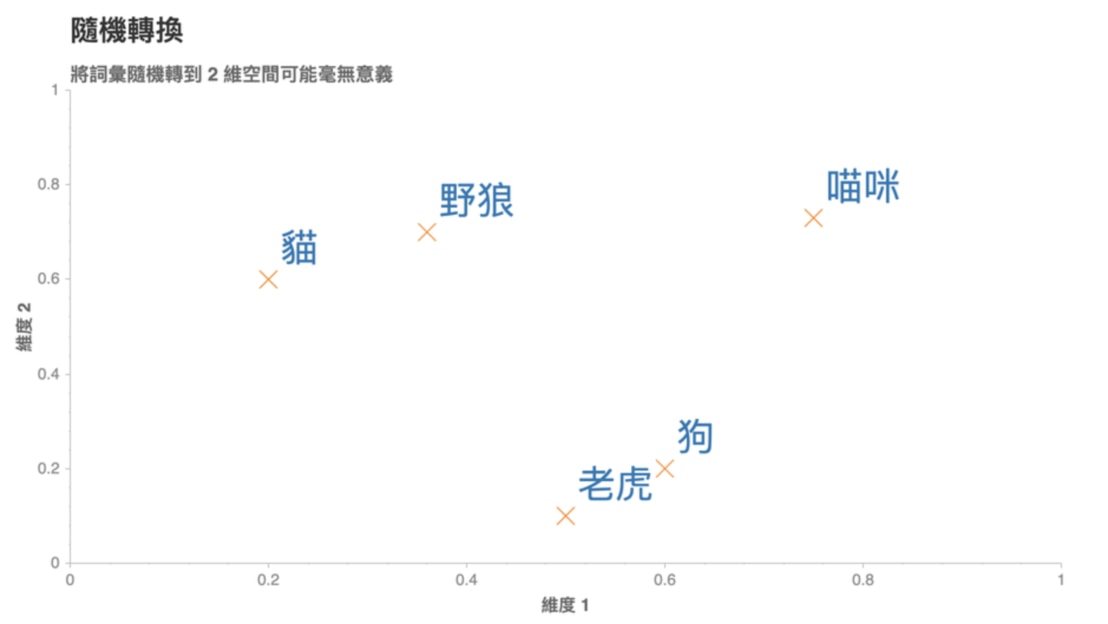
Figure 22: Caption
這些代表詞彙的向量被稱之為詞向量,但是你可以想像這樣的隨機轉換很沒意義。如圖22我們就無法理解:
- 為何「狗」是跟「老虎」而不是跟同為犬科的「野狼」比較接近?
- 為何「貓」的維度 2 比「狗」高,但卻比「野狼」低?
- 維度 2 的值的大小到底代表什麼意義?
- 「喵咪」怎麼會在那裡?
這是因為我們只是將詞彙隨機地轉換到 2 維空間,並沒有讓這些轉換的結果(向量)反應出詞彙本身的語意(Semantic)。
一個理想的轉換應該是如圖23:
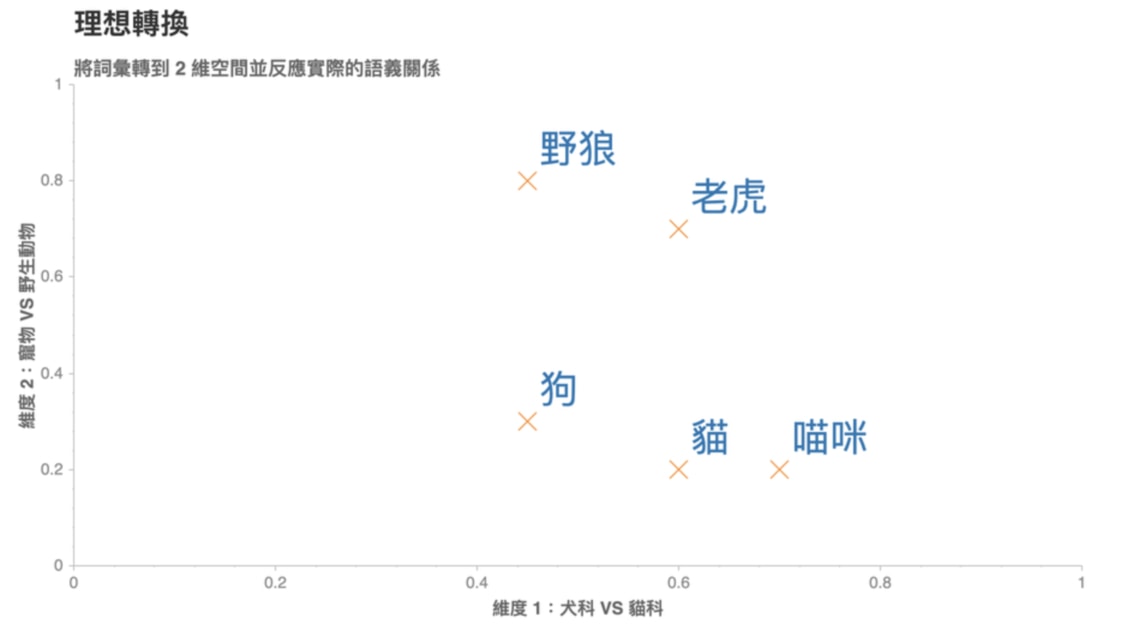
Figure 23: Caption
在這個 2 維空間裡頭,我們可以發現一個好的轉換有 2 個特性:
- 距離有意義:「喵咪」與意思相近的詞彙「貓」距離接近,而與較不相關的「狗」距離較遠
- 維度有意義:看看(狗, 貓)與(野狼, 老虎)這兩對組合,可以發現我們能將維度 1 解釋為貓科 VS 犬科;維度 2 解釋為寵物與野生動物
如果我們能把語料庫(Corpus)裏頭的每個詞彙都表示成一個像是這樣有意義的詞向量,神經網路就能幫我們找到潛藏在大量詞彙中的語義關係,並進一步改善 NLP 任務的精準度。
好消息是,大部分的情況我們並不需要自己手動設定每個詞彙的詞向量。我們可以隨機初始化所有詞向量(如前述的隨機轉換),並利用平常訓練神經網路的反向傳播算法(Backpropagation),讓神經網路自動學到一組適合當前 NLP 任務的詞向量(如上張圖的理想狀態)。
Figure 24: Caption
如圖24,反向傳播讓神經網路可以在訓練過程中修正參數,持續減少預測錯誤的可能性。
在 NLP 裏頭,這種將一個詞彙或句子轉換成一個實數詞向量(Vectors of real numbers)的技術被稱之為詞嵌入(Word Embedding)。
而在 Keras 裡頭,我們可以使用 Embedding 層來幫我們做到這件事情:
1: from keras import layers 2: embedding_layer = layers.Embedding( 3: MAX_NUM_WORDS, NUM_EMBEDDING_DIM)
- MAX_NUM_WORDS 是我們的字典大小(10,000 個詞彙)、NUM_EMBEDDING_DIM 則是詞向量的維度。常見的詞向量維度有 128、256 或甚至 1,024。
- Embedding 層一次接收 k 個長度任意的數字序列,並輸出 k 個長度相同的序列。輸出的序列中,每個元素不再是數字,而是一個 NUM_EMBEDDING_DIM 維的詞向量。
假如我們將第一筆(也就是 k = 1)假新聞標題 A 丟入 Embedding 層,並設定 NUM_EMBEDDING_DIM 為 3 的話,原來的標題 A:
新聞標題:
[
0,
0,
0,
185,
300,
72,
4029,
37,
1,
121,
250,
95,
30,
511,
92,
2358,
33,
2565,
19,
55,
]
就會被轉換成類似以下的形式:
新聞標題:
[
[0.212, 0.111, 0.666],
[0.212, 0.111, 0.666],
[0.212, 0.111, 0.666],
[0.528, 0.344, 0.452],
[0.163, 0.93, 0.58],
[0.527, 0.262, 0.246],
[0.077, 0.695, 0.776],
[0.624, 0.962, 0.96],
[0.456, 0.927, 0.404],
[0.353, 0.119, 0.108],
[0.805, 0.969, 0.725],
[0.379, 0.265, 0.473],
[0.436, 0.186, 0.738],
[0.923, 0.287, 0.967],
[0.477, 0.614, 0.838],
[0.089, 0.328, 0.993],
[0.887, 0.913, 0.885],
[0.604, 0.118, 0.646],
[0.907, 0.52, 0.437],
[0.443, 0.432, 0.498],
]
序列裡頭的每個數字(即詞彙)都被轉換成一個 3 維的詞向量,而相同數字則當然都會對應到同一個詞向量(如前 3 個 0 所對應到的詞向量)。
Figure 25: Caption
有了這樣的轉換,我們就能將轉換後的詞向量丟入 RNN / LSTM 裏頭,讓模型逐步修正隨機初始化的詞向量,使得詞向量裡頭的值越來越有意義。
有了兩個新聞標題的詞向量,接著讓我們瞧瞧能夠處理這些數據的神經網路架構吧!
11.6. 一個神經網路,兩個新聞標題
一般來說,多數你見過的神經網路只會接受一個資料來源:
- 輸入一張圖片,判斷是狗還是貓
- 輸入一個音訊,將其轉成文字
- 輸入一篇新聞,判斷是娛樂還是運動新聞
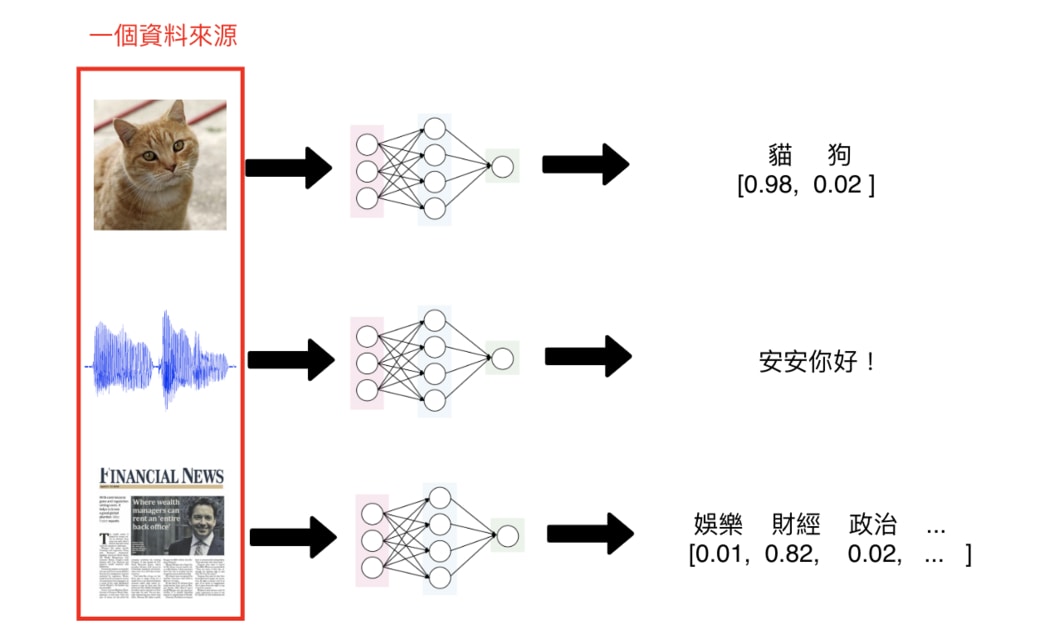
Figure 26: Caption
單一輸入的神經網路架構可以解決大部分的深度學習問題。但在這個 Kaggle 競賽裡頭,我們想要的是一個能夠讀入成對新聞標題,並判斷兩者之間關係的神經網路架構:
- 不相關(unrelated)
- 新聞 B 同意 A(agreed)
- 新聞 B 不同意 A(disagreed)
要怎麼做到這件事情呢?
我們可以使用孿生神經網路(Siamese Network)架構:
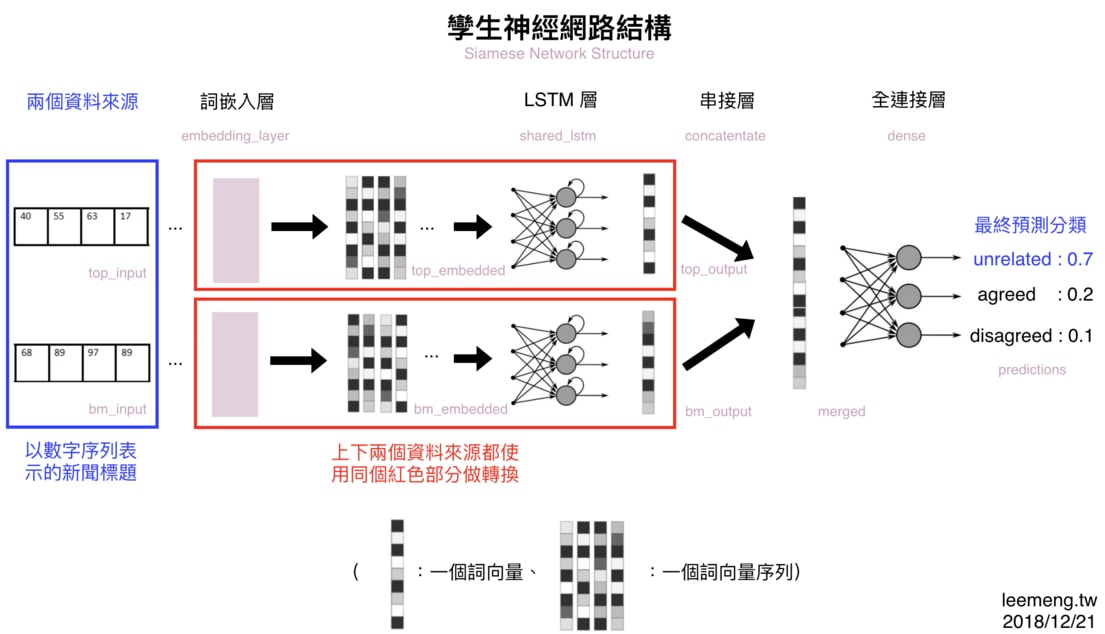
Figure 27: 使用孿生神經網路架構來處理同類型的 2 個新聞標題
所謂孿生神網網路指的是:一部份的神經網路(紅框部分)被重複用來處理多個不同的資料來源(在本篇中為 2 篇不同的新聞標題)。
而會想這樣做,是因為不管標題內容是新聞 A 還是新聞 B,其標題本身的語法 & 語義結構大同小異。
以這樣的觀點來看的話,我們並不需要兩個不同的 LSTM 來分別將新聞 A 以及新聞 B 的詞向量做有意義的轉換,而是只需要讓標題 A 與標題 B 共享一個 LSTM 即可。畢竟,標題 A 跟標題 B 的數據結構很像。
如果我們只寫一個 Python 函式就能處理 2 個相同格式的輸入的話,為何要寫 2 個函式呢?孿生神經網路也是相同的概念。
11.7. 建立模型
深度學習以及 NLP 領域的學問博大精深,但一般來說,當你想要實際動手寫出一個神經網路的時候,有 3 個基本步驟可以 follow:
- 定義神經網路的架構
- 決定如何衡量模型的表現
- 訓練模型並挑選最好的結果
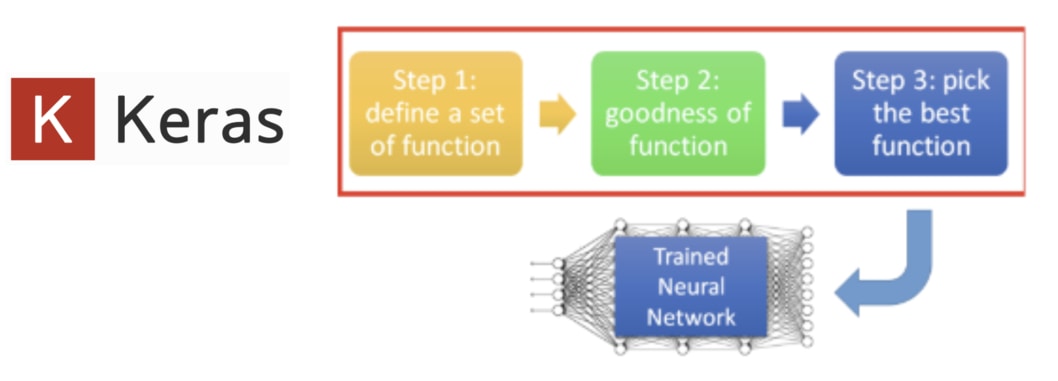
接下來你會看到,大約 80 % 的程式碼會花在實作第一個步驟。剩餘 2 個步驟在使用 Keras 的情況下非常容易就能實現;但後面我們也會談到,你將花 80 % 的時間在最後一個步驟上面。
首先,先讓我們進入第一步驟。
- 定義神經網路的架構
在實作之前,先讓我們回顧一下前面段落看到的模型架構:
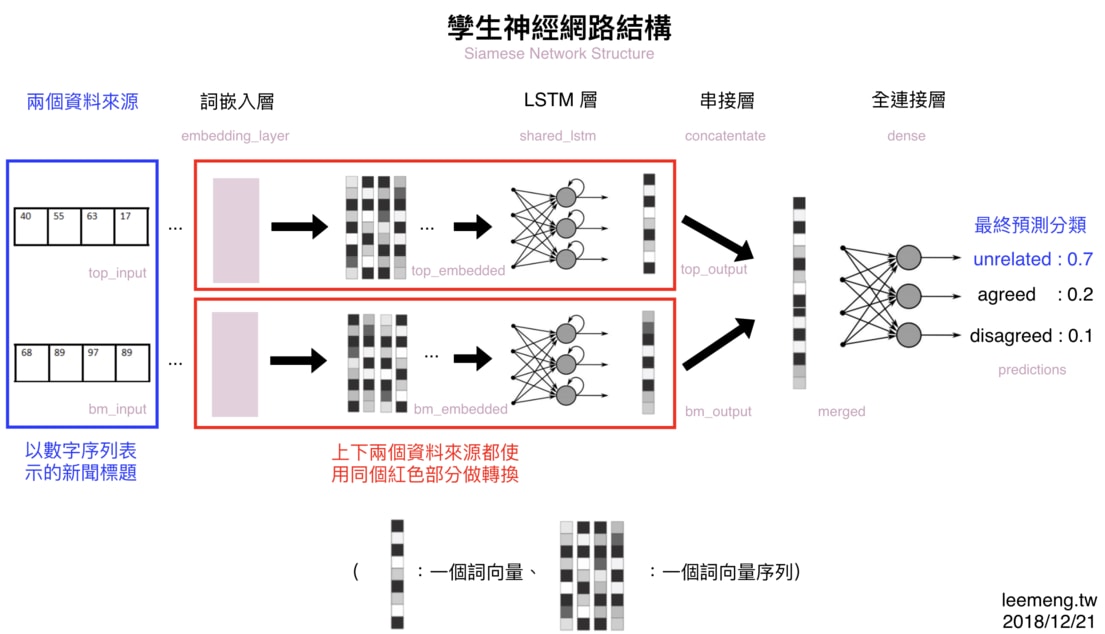
Figure 28: Caption
從左到右掃過一遍,你可以很清楚地發現我們需要以下 5 個元素來完成這個模型:
- 兩個新聞標題(兩個長度為 20 的數字序列)
- 一個詞嵌入層:將數字序列轉換為詞向量序列
- 一個 LSTM 層:讀入前層的詞向量並萃取標題語義
- 一個串接層:將兩個新聞標題的處理結果(也是向量)串接成一個向量
- 一個全連接層:將前層的向量轉換為 3 個分類的預測機率
有些層我們已經在前面章節看過 Keras 的實現,比方說詞嵌入層以及 LSTM 層。剩下的串接層以及全連結層在 Keras 也都有現成的模組可供使用。
另外值得一提的是,圖上的每個層(Layer)以及向量右下的灰字都對應了底下 Python 程式碼裡頭的變數名稱:
因此,如果等等你不了解底下某個特定的變數所代表的意義,可以回來利用這張架構圖來釐清概念。
以下就是此模型的 Keras 實作:
1: # 基本參數設置,有幾個分類 2: NUM_CLASSES = 3 3: 4: # 在語料庫裡有多少詞彙 5: MAX_NUM_WORDS = 10000 6: 7: # 一個標題最長有幾個詞彙 8: MAX_SEQUENCE_LENGTH = 20 9: 10: # 一個詞向量的維度 11: NUM_EMBEDDING_DIM = 256 12: 13: # LSTM 輸出的向量維度 14: NUM_LSTM_UNITS = 128 15: 16: # 建立孿生 LSTM 架構(Siamese LSTM) 17: from keras import Input 18: from keras.layers import Embedding, \ 19: LSTM, concatenate, Dense 20: from keras.models import Model 21: 22: # 分別定義 2 個新聞標題 A & B 為模型輸入 23: # 兩個標題都是一個長度為 20 的數字序列 24: top_input = Input( 25: shape=(MAX_SEQUENCE_LENGTH, ), 26: dtype='int32') 27: bm_input = Input( 28: shape=(MAX_SEQUENCE_LENGTH, ), 29: dtype='int32') 30: 31: # 詞嵌入層 32: # 經過詞嵌入層的轉換,兩個新聞標題都變成 33: # 一個詞向量的序列,而每個詞向量的維度 34: # 為 256 35: embedding_layer = Embedding( 36: MAX_NUM_WORDS, NUM_EMBEDDING_DIM) 37: top_embedded = embedding_layer( 38: top_input) 39: bm_embedded = embedding_layer( 40: bm_input) 41: 42: # LSTM 層 43: # 兩個新聞標題經過此層後 44: # 為一個 128 維度向量 45: shared_lstm = LSTM(NUM_LSTM_UNITS) 46: top_output = shared_lstm(top_embedded) 47: bm_output = shared_lstm(bm_embedded) 48: 49: # 串接層將兩個新聞標題的結果串接單一向量 50: # 方便跟全連結層相連 51: merged = concatenate( 52: [top_output, bm_output], 53: axis=-1) 54: 55: # 全連接層搭配 Softmax Activation 56: # 可以回傳 3 個成對標題 57: # 屬於各類別的可能機率 58: dense = Dense( 59: units=NUM_CLASSES, 60: activation='softmax') 61: predictions = dense(merged) 62: 63: # 我們的模型就是將數字序列的輸入,轉換 64: # 成 3 個分類的機率的所有步驟 / 層的總和 65: model = Model( 66: inputs=[top_input, bm_input], 67: outputs=predictions) 68:
2022-05-23 10:42:00.872716: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
也可以透過keras的function將模型的架構圖畫出來
1: #from keras.utils import plot_model 2: from keras.utils.vis_utils import plot_model 3: plot_model( 4: model, 5: to_file='siameseModel.png', 6: show_shapes=True, 7: show_layer_names=False, 8: rankdir='LR')

Figure 29: Caption
除了模型架構以外,我們還可以看到所有層的輸入 / 輸出張量(Tensor)的維度。在 Keras 裏頭,張量的第 1 個維度通常為樣本數(比方說 5 則新聞標題),而 None 則代表可以指定任意值。
最重要的是,這個用 Keras 定義出來的模型,跟我們之前想像中的孿生神經網路可以說是一模一樣:
- 兩個新聞標題(兩個長度為 20 的數字序列)
- 全連接層
全連接層顧名思義,代表該層的每個神經元(Neuron)都會跟前一層的所有神經元享有連結:
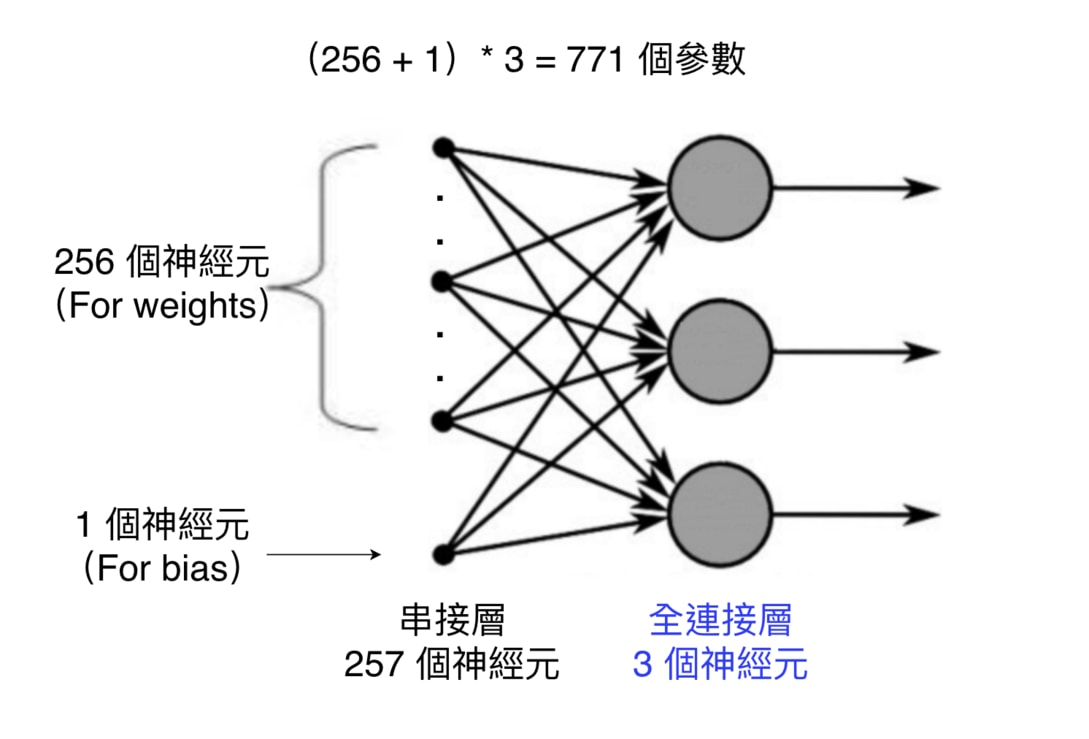
而為了確認我們計算的參數量無誤,還可以使用 model.summary() 來看每一層的參數量以及輸出的張量(Tensor)長相:
1: print(model.summary())
Model: "model" __________________________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ================================================================================================== input_1 (InputLayer) [(None, 20)] 0 [] input_2 (InputLayer) [(None, 20)] 0 [] embedding (Embedding) (None, 20, 256) 2560000 ['input_1[0][0]', 'input_2[0][0]'] lstm (LSTM) (None, 128) 197120 ['embedding[0][0]', 'embedding[1][0]'] concatenate (Concatenate) (None, 256) 0 ['lstm[0][0]', 'lstm[1][0]'] dense (Dense) (None, 3) 771 ['concatenate[0][0]'] ================================================================================================== Total params: 2,757,891 Trainable params: 2,757,891 Non-trainable params: 0 __________________________________________________________________________________________________ None全連接層在最下面。而因為其與前一層「緊密」連接的緣故,它在 Keras 裏頭被稱為 Dense 層。它也是最早出現、最簡單的神經網路層之一。
Param # 則紀錄了每一層所包含的模型參數(Parameters)。在機器學習的過程中,這些參數都會不斷地被調整,直到能讓模型能做出很好的預測。詞嵌入層有最多的參數,因為我們要為 字典裡頭的每個詞彙都建立一個 256 維度的詞向量,因此參數量為 10,000 * 256。
這張表另外一個值得注意的地方是所有層的 Output Shape 的第一個維度都是 None。而 None 代表著可以是任意的數字。
在 Keras 裡頭,第一個維度代表著樣本數(#Samples),比方說前 9,527 筆新聞標題 A 的數字序列的 shape 應該要是 (9527, 20):
而之所以每層的樣本數為 None 是因為 Keras 為了因應在不同場合會丟入不同數量的樣本需求。比方說,在訓練時你可能會一次丟 32 筆資料給模型訓練,但在預測的時候一次只丟 16 筆資料。
- Softmax 函式
Softmax 函式一般都會被用在整個神經網路的最後一層上面,比方說我們這次的全連接層。
Softmax 函式能將某層中的所有神經元裡頭的數字作正規化(Normalization):將它們全部壓縮到 0 到 1 之間的範圍,並讓它們的和等於 1。
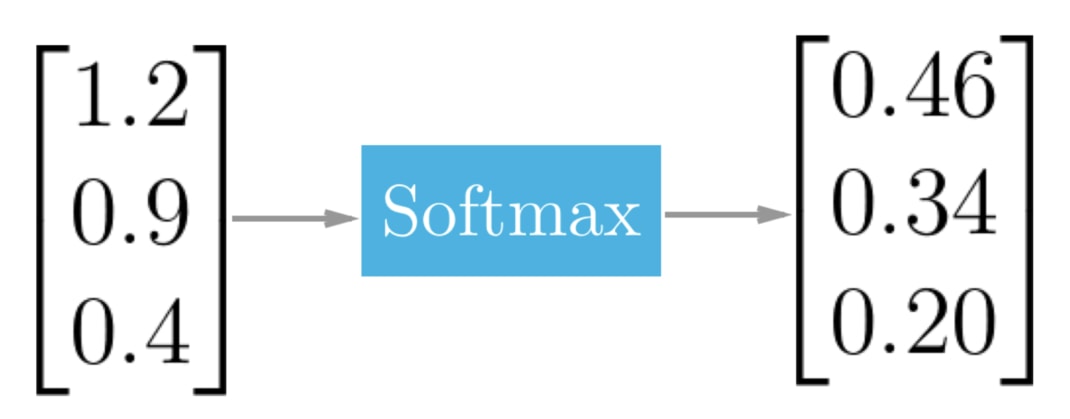
Figure 30: Softmax 能將多個數字作正規化,讓它們的和為 1
因為
- 所有數值都位於 0 到 1 之間
- 所有數值相加等於 1
這兩個條件恰好是機率(Probability)的定義,Softmax 函式的運算結果可以讓我們將每個神經元的值解釋為對應分類(Class)的發生機率。
以我們的假新聞分類任務來說的話,每個值就各代表以下分類的發生機率:
- 不相關: 0.46
- 新聞 B 同意新聞 A:0.34
- 新聞 B 不同意新聞 B:0.20
如果現在是在做預測且我們只能選出一個分類當作答案的話,我們可以說這次的分類結果最有可能是「不相關」這個類別,因為其發生機率最高。
在定義好模型以後,我們就可以進入下個步驟:定義衡量模型好壞的指標。
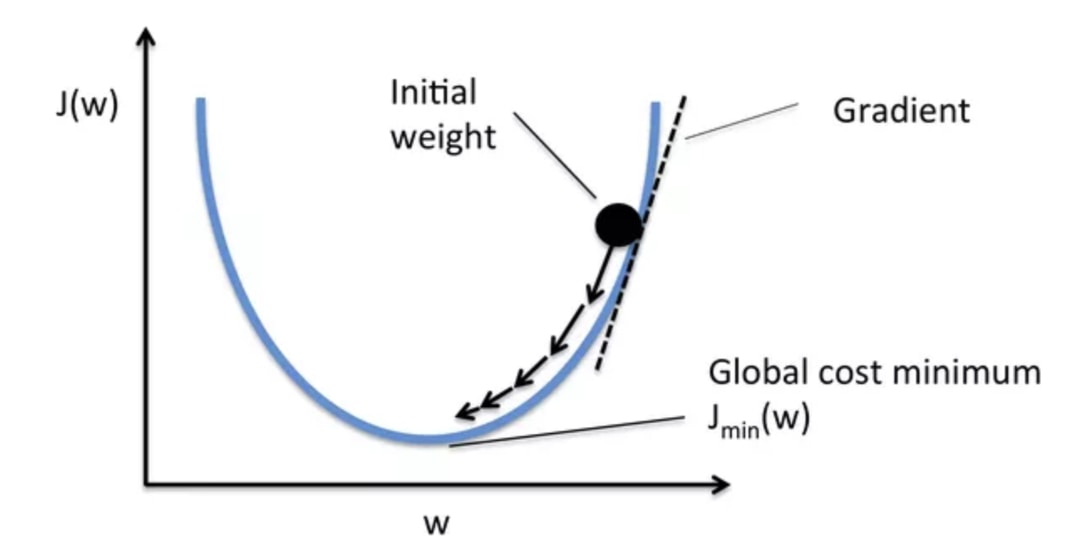
圖43的拋物線即為損失函數 J(w)。當參數 w 有不同值時,損失函數的值也有所不同。模型會持續修正參數 w 以期最小化損失函數 (圖片來源)
那你會問,在假新聞分類裡頭,我們應該使用什麼損失函數呢?
我們在將正解做 One-hot Encoding 一節有稍微提到,我們會希望
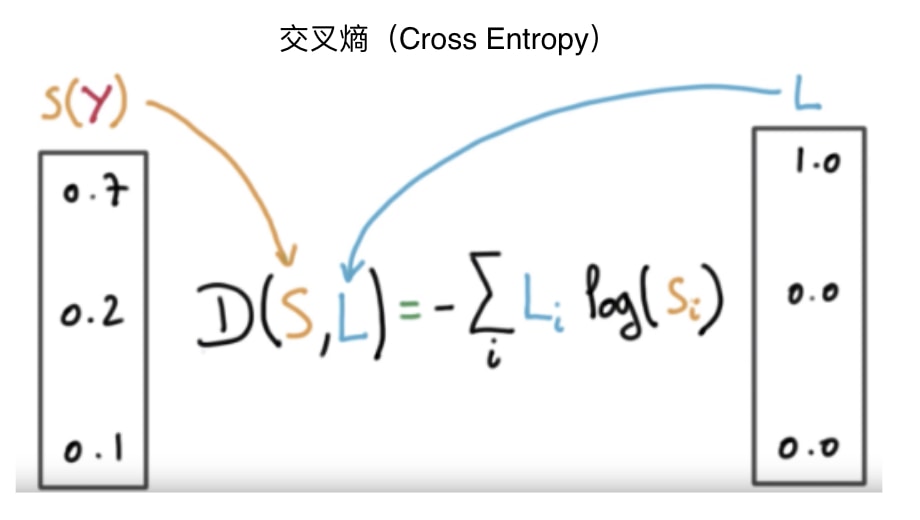
- 正確的分類的機率分佈 P1(例:[1, 0, 0])
- 模型預測出的機率分佈 P2(例:[0.7, 0.2, 0.1])
這 2 個機率分佈的「差距」越小越好。而能計算 2 個機率分佈之間的差距的交叉熵(Cross Entropy)就是這次的分類問題中最適合的損失函數。
- 所有數值都位於 0 到 1 之間
- 評估模型效能
為了讓機器自動「學習」,我們得給它一個損失函數(Loss Function)。
給定一個正確解答 y 以及模型預測的結果 y_head,我們的模型透過損失函數就能自動計算出現在的預測結果跟正解的差距為多少。
透過損失函數的回饋,模型會盡全力修正參數,以期將此損失函數的值下降到最低(也就是讓預測結果 y_head 跟正解 y 越來越接近)。
在 Keras 裏頭,我們可以這樣定義模型的損失函數:
1: model.compile( 2: optimizer='rmsprop', 3: loss='categorical_crossentropy', 4: metrics=['accuracy'])
categorical_crossentropy 即是我們剛剛所說的交叉熵,而 accuracy 則是準確度,會被我們用來在訓練過程中了解模型的表現情況。
精準度的定義為:
# 模型預測正確的樣本數
--------------–—
# 總樣本數
雖然有了交叉熵來當作我們模型的損失函數,但是實際上模型要如何更新裡頭的參數呢?我們需要一個優化器(Optimizer)來做到這件事情。
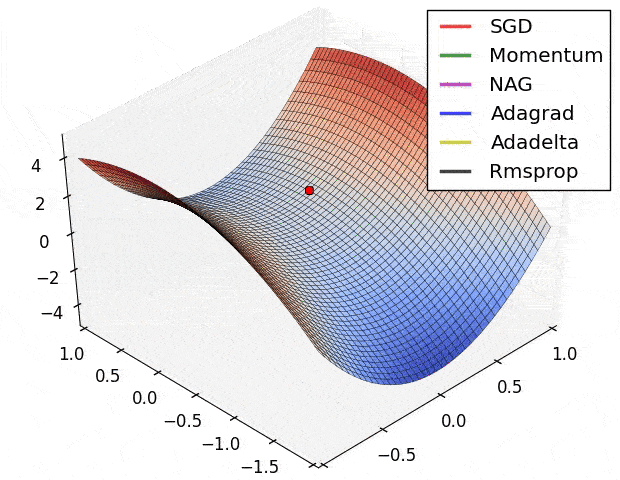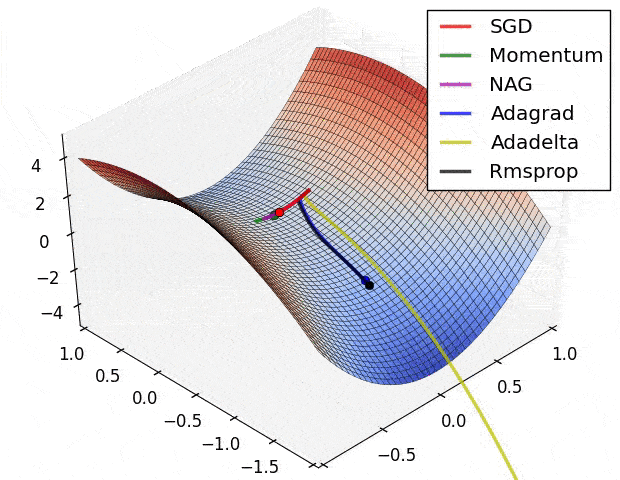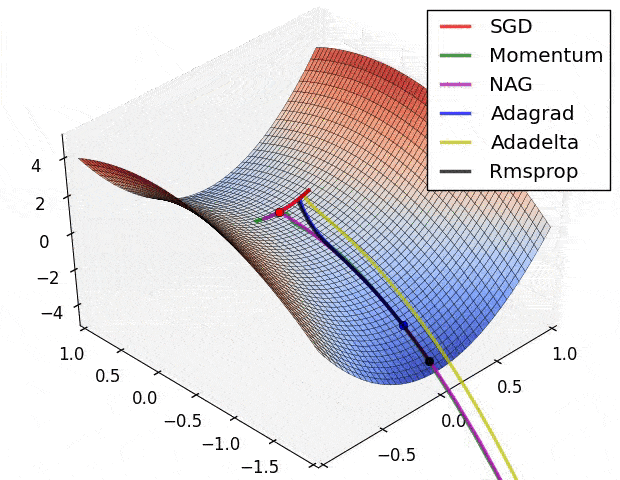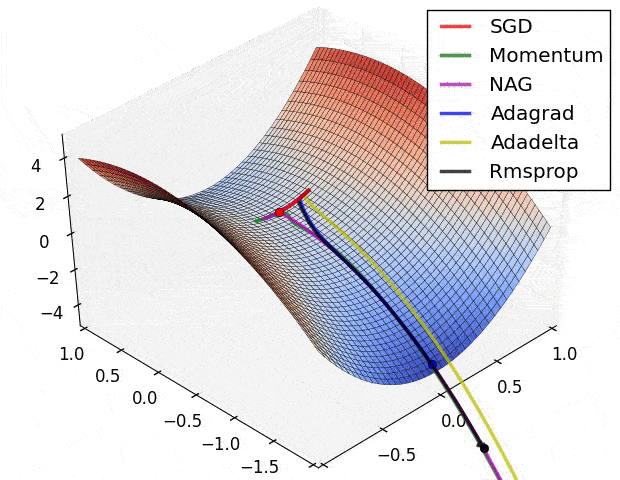
Figure 31: 不同優化器透過調整參數來降低損失函數的情形,就像是在想辦法往溜滑梯的低處滑一樣
雖然我們有很多種優化器,但它們基本上都是從梯度下降法(Gradient Descent)延伸而來。
在上圖的不同位置,梯度下降法會重新計算每個參數對損失函數的梯度(斜率)。接著梯度下降法會利用該梯度來修正參數,使得使用新參數算出來的損失函數的值能夠持續往下降。
不同優化器則有各自往下滑的秘方,比方說自動調整 Learning rate。
現在就先讓我們使用 RMSProp 優化器。而在有了損失函數以及優化器以後,我們就可以正式開始訓練模型了!
- 訓練模型並挑選最好的結果
這步驟很直觀,我們就是實際使用 model.fit 來訓練剛剛定義出來的孿生 LSTM 模型:
1: # 決定一次要放多少成對標題給模型訓練 2: BATCH_SIZE = 512 3: 4: # 決定模型要看整個訓練資料集幾遍 5: NUM_EPOCHS = 10 6: 7: # 實際訓練模型 8: history = model.fit( 9: # 輸入是兩個長度為 20 的數字序列 10: x=[x1_train, x2_train], 11: y=y_train, 12: batch_size=BATCH_SIZE, 13: epochs=NUM_EPOCHS, 14: # 每個 epoch 完後計算驗證資料集 15: # 上的 Loss 以及準確度 16: validation_data=( 17: [x1_val, x2_val], 18: y_val 19: ), 20: # 每個 epoch 隨機調整訓練資料集 21: # 裡頭的數據以讓訓練過程更穩定 22: shuffle=True 23: ) 24:
Epoch 1/10 1/564 [..............................] - ETA: 24:28 - loss: 1.0995 - accuracy: 0.2832 2/564 [..............................] - ETA: 1:55 - loss: 1.0636 - accuracy: 0.4668 loss: 0.2228 - accuracy: 0.9103 ... 564/564 [==============================] - 185s 329ms/step - loss: 0.2228 - accuracy: 0.9103 - val_loss: 0.3631 - val_accuracy: 0.8526
這邊特別值得拿出來提的是以下兩個參數:
- BATCH_SIZE
- NUM_EPOCHS
依照我們前面對損失函數(Loss Function)的說明,理論上模型是把訓練資料集裡頭的 32 萬筆資料全部看完一遍之後,再更新一次參數以降低損失函數。
但是這樣太曠日廢時,訓練可能要花很久才能完成。
- BATCH_SIZE
- BATCH
實務上都是每次只放入幾筆訓練數據,讓模型看完這些資料後就做一次參數的更新。而這個「幾筆」,就是 BATCH_SIZE。
依照 BATCH_SIZE 的大小,梯度下降(Gradient Descent, 後稱 GD)可以概括為 3 個類別:
- GD(BATCH_SIZE = 訓練資料集大小,且這時不稱為 batch)
- Mini-batch GD(BATCH_SIZE 通常為一個較小的 2 的倍數)
- SGD(BATCH_SIZE = 1)
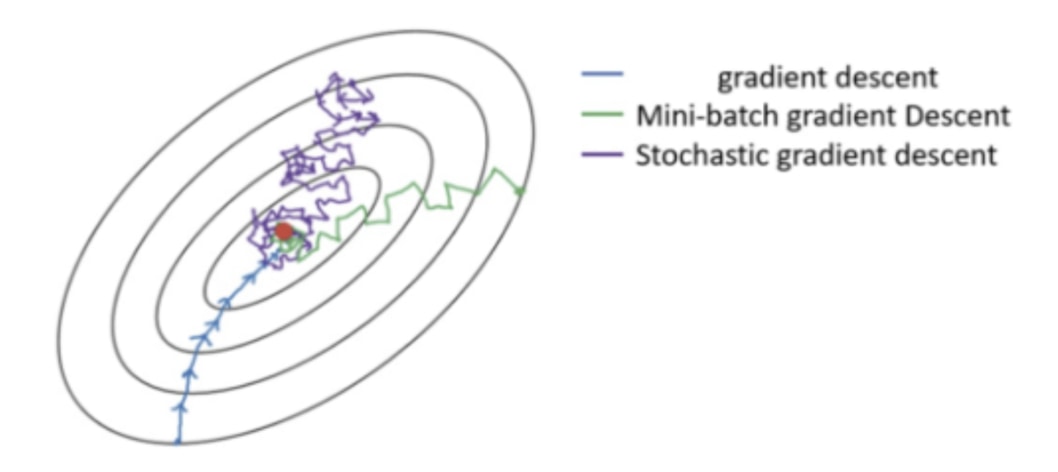
想像損失函數是個越往裡面值就越低的碗,梯度下降就是要想辦法到達中心點 (圖片來源)
如上圖所示,下方的 GD 因為在每次更新參數前都會看完訓練資料集裡頭所有的數據,因此它更新參數的方向是最可靠的。但要往前走一步就就得看完 32 萬筆數據,未免成本也太大。
另一個極端是上方的 SGD:模型每看完 1 個訓練數據就嘗試更新權重,而因為單一一筆訓練數據並不能很好地代表整個訓練資料集,前進的方向非常不穩定。
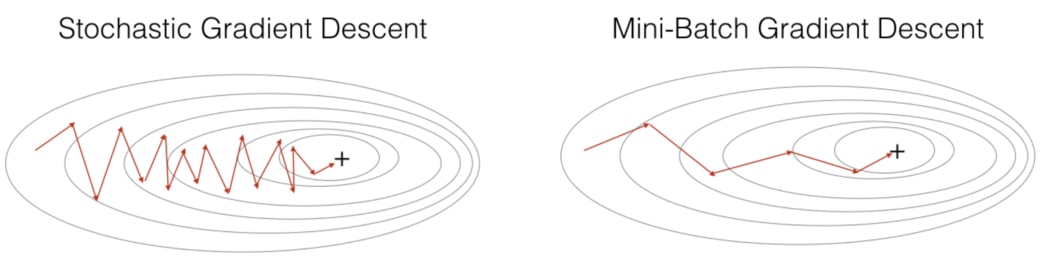
Figure 32: Caption
因此我們常常採用的是中庸之道: Mini-batch GD 的方式來訓練模型,而這靠的是指定 model.fit 函式裡頭的 batch_size。
NUM_EPOCHS 則很容易理解:你希望模型不只將 32 萬筆的訓練數據都看過一遍,而是每一筆資料還要多看過好幾次,以讓模型確確實實地從它們身上學到東西。NUM_EPOCHS = 10 的意思就代表模型會重複看整個訓練資料集 10 次。
接著讓我們看看 Keras 的訓練過程:
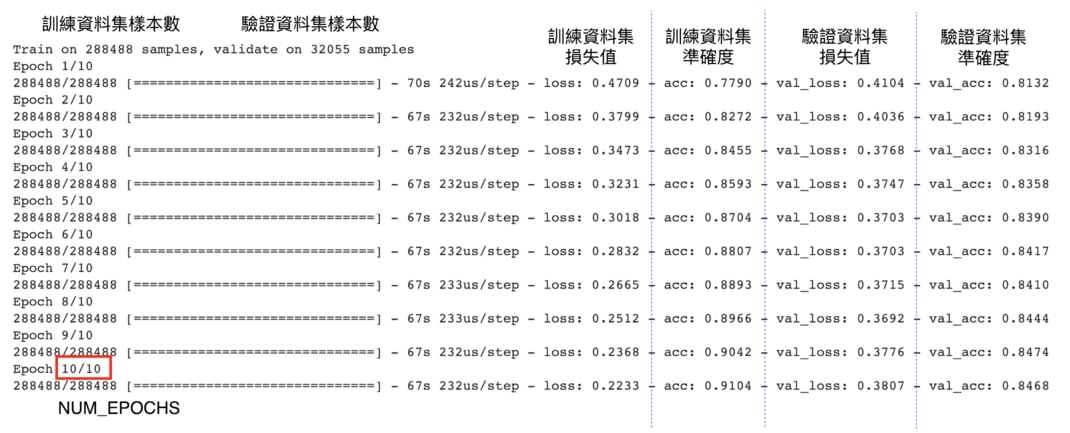
Figure 33: Caption
因為模型的目標就是要最小化損失函數(Loss Function),你可以觀察到當模型看過越多訓練資料集(Training Set)的數據以後,損失值(loss)就越低,分類的準確度(acc)則越高。
這代表我們的模型越來越熟悉訓練資料集裡頭的數據,因此在訓練資料集裡頭的表現越來越好。
如果依照準確度以及損失值分別畫圖的話則會長這樣:
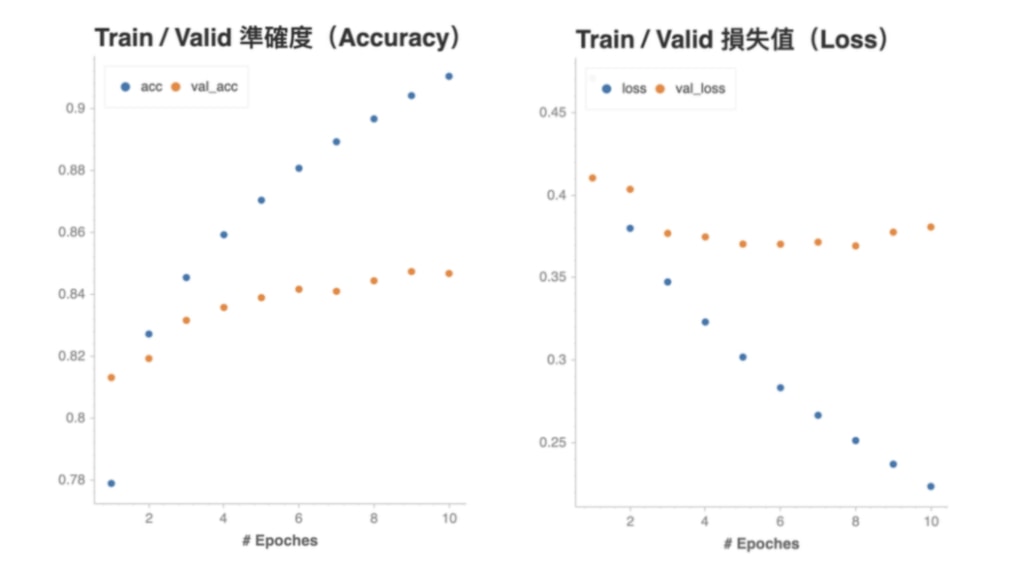
Figure 34: Caption
很明顯地,我們的神經網路有過適(Overfittng)的問題:儘管在訓練資料集表現得非常好(準確度超過 90 %、損失小於 0.2),在從沒看過的驗證資料集的表現就相對遜色不少。且在第 6 個 epoch 之後驗證資料集的準確度 val_acc 就沒什麼在上升,驗證集的損失 val_loss 則已經逐漸上升。
這代表模型利用從訓練資料集學到的模式(Pattern)還無法非常精準地預測沒見過的事物。
如同我們在這章節一開頭所說的,雖然第 3 步驟:「訓練模型並挑選最好的結果」的 Keras 實作非常簡單(基本上就是 model.fit( …)),但實際上在一個機器學習 / 深度學習專案裡頭,你將會花 80 % 的時間在這個步驟裡頭調整參數,想辦法找到一個最棒的模型。
儘管如此,我們現在最想知道的還是這個模型在真實世界(也就是測試資料集)到底能表現多好,因此先讓我們試著拿這個簡單模型來做預測吧!
- GD(BATCH_SIZE = 訓練資料集大小,且這時不稱為 batch)
11.8. 進行預測並提交結果
就跟我們對訓練 / 驗證資料集做的資料前處理一樣,要對測試資料集(Test Set)做預測,我們得先將裡頭的文本數據通通轉換成能夠丟進模型的數字序列資料。
- 首先,讓我們把測試資料集讀取進來:
1: import pandas as pd 2: test = pd.read_csv("./dataset/fakenews.train.csv", index_col=0, encoding='utf-8', dtype=str) 3: print(test.head(3))
tid1 tid2 ... title2_en label id ... 0 0 1 ... Police disprove "bird's nest congress each per... unrelated 3 2 3 ... Shenzhen's GDP outstrips Hong Kong? Shenzhen S... unrelated 1 2 4 ... The GDP overtopped Hong Kong? Shenzhen clarifi... unrelated [3 rows x 7 columns]
測試資料集跟訓練資料集的唯一差別只在沒有 label 欄位,因此我們只需要將當初在資料前處理章節使用的步驟原封不動地套用在測試資料集即可。
你可以趁機複習一下有哪些步驟:
1: # 以下步驟分別對新聞標題 A、B 進行文本斷詞 / Word Segmentation 2: # jieba在這裡會出問題,要加上astype(str) 3: test['title1_tokenized'] = test.loc[:, 'title1_zh'].astype(str).apply(jieba_tokenizer) 4: test['title2_tokenized'] = test.loc[:, 'title2_zh'].astype(str).apply(jieba_tokenizer) 5: 6: # 將詞彙序列轉為索引數字的序列 7: x1_test = tokenizer.texts_to_sequences(test.title1_tokenized) 8: x2_test = tokenizer.texts_to_sequences(test.title2_tokenized) 9: 10: # 為數字序列加入 zero padding 11: x1_test = keras.preprocessing.sequence.pad_sequences( 12: x1_test, maxlen=MAX_SEQUENCE_LENGTH) 13: x2_test = keras.preprocessing.sequence.pad_sequences( 14: x2_test, maxlen=MAX_SEQUENCE_LENGTH) 15: 16: # 利用已訓練的模型做預測 17: predictions = model.predict([x1_test, x2_test]) 18: 19: print(predictions[5])
[8.7921888e-01 8.2681845e-06 1.2077282e-01]
跟我們之前討論過的一樣,模型針對每一筆成對新聞標題的輸入,會回傳給我們 3 個分類的機率值。
現在,我們只要將機率值最大的類別當作答案,並將這個結果轉回對應的文本標籤即可上傳到 Kaggle:
1: index_to_label = {v: k for k, v in label_to_index.items()} 2: 3: test['Category'] = [index_to_label[idx] for idx in np.argmax(predictions, axis=1)] 4: 5: submission = test.loc[:, ['Category']].reset_index() 6: 7: submission.columns = ['Id', 'Category'] 8: print(submission.head())
Id Category 0 0 unrelated 1 3 unrelated 2 1 unrelated 3 2 unrelated 4 9 agreed
得到上面的 DataFrame 以後,我們可以將其儲存成 CSV 並上傳到 kaggle,而結果如下:

Figure 35: NLP 模型第一次的結果
如果你還記得我們在用直覺找出第一條底線的章節內容的話,就會知道這並不是應該多好的預測結果,但的確比多數票決好了一點點。
不過不需要操之過急,因為任何機器學習專案都是一個持續重複改善的迴圈。在第一次預測就做出完美結果的情況很少,重點是持續改善。
在第一次提交結果以後,我們還可以做非常多事情來嘗試改善模型效能:
- 改變字典詞彙量、序列長度
- 改變詞向量的維度
- 嘗試預先訓練的詞向量如 ELMo、GloVe
- 調整 LSTM 層的輸出維度
- 使用不同優化器、調整 Learning rate
- 改變神經網路架構如使用 GRU 層
- …
能改善準確度的方式不少,但因為牽涉範圍太廣,請容許我把它們留給你當做回家作業。
走到這裡代表你已經完整地經歷了一個 NLP 專案所需要的大部分步驟。在下一節.讓我們回顧一下在這趟旅程中你所學到的東西。
- 改變字典詞彙量、序列長度
12. 3 門推薦的線上課程
- 台大電機系李宏毅教授的深度學習課程: 奠定理論基礎
- Coursera 的 Deep Learning 專項課程: 理論 70 % + 實作 30 %
- [[https://www.oreilly.com/library/view/deep-learning-with/9781617294433VE/][Deep Learning with Python: 注重程式實作
13. 工具
13.1. 中研院CkipTagger中文處理工具
- 官網: https://ckip.iis.sinica.edu.tw/
- CKIP Transformers — 繁體中文的 transformers 模型(包含 ALBERT、BERT、GPT2)及自然語言處理工具。
- CKIP Tagger — 新的開源斷詞、詞性標注、實體辨識系統。
- CKIP Transformers — 繁體中文的 transformers 模型(包含 ALBERT、BERT、GPT2)及自然語言處理工具。
- 簡介
13.2. 結巴Jieba1
- 使用教學
- Jieba 原理介紹8
Jieba 斷詞主要是结合:
- 規則斷詞: 主要是透過詞典,在對句子進行斷詞的時候,將句子的每個字與詞典中的詞進行匹配,找到則斷詞,否則無法斷詞。
- 統計斷詞: 主要是看如果相連的字在不同的文本中出現的次數越多,就推斷這相連的字很可能就是一個詞。因此就可以利用字與字相鄰出现的頻率來做統計。當高於某一個臨界值時,便可認為此字組是一個詞語。
- 規則斷詞: 主要是透過詞典,在對句子進行斷詞的時候,將句子的每個字與詞典中的詞進行匹配,找到則斷詞,否則無法斷詞。
- Jieba 斷詞模式8
最著名的功能就是提供斷詞模式,主要分為
- 精確模式: 將句子最精確的切開,適合文本分析
- 全模式: 把句子中所有的可以成詞的詞語都斷出来,速度非常快。
- 搜索引擎模式: 在精確模式的基礎上,對長的詞語再次切分,提高召回率,適合用於搜索引擎分詞。
- 精確模式: 將句子最精確的切開,適合文本分析
13.3. NLTK
NLTK: NLP的處理工具
14. 語料集
自然語言中,雖然算法、模型很重要,但沒有資料驅動還是什麼都做不了,尤其是文字不像圖片一樣不分國界,每個地方用的語言不同,所需要的資料也就不同,英文因為是世界語言,加上論文的發表大部分以研究英文為主,所以資料當然是最多,不過幸運地,中文的語料也算蠻多的,這邊列出幾個好用的中文資料集或預訓練模型9
14.1. NLP-Chinese-Corpus
NLP_Chinese-Corpus 是在github上由brightmart開源的中文語料統整,裡面包含了一些維基百科、新聞、社區問答等語料,比較多是通用型的中文語料,可以當作詞向量訓練的材料,或者其它應用
14.2. PTT-Gossiping-Corpus
PTT-Gossiping-Corpus是由zake7749在github以及Kaggle上提供的繁體中文問答語料集,一個問句對應到一句鄉民回答,對於想實作中文Sequence2Sequence的朋友,會是蠻不錯的實驗語料
圖片截自zake7749/Gossiping-Chinese-Corpus 中的範例說明
14.3. Wiki-corpus
繁體中文的語料,通常就會想到PTT以及中文維基百科,而現在獲取中文維基百科的手段有很多種,維基百科本身也有提供API,大家可以視個人需求來拿到資料
14.4. Tencent AI LAB
騰訊AI實驗室非常佛心的釋出相當多有用的中文資料集,像是Dialogue Research中包含一些在聊天機器人領域上實用的中文語料,有興趣的朋友可以參考我這篇論文的介紹:Improving Open-Domain Dialogue Systems via Multi-Turn Incomplete Utterance Restoration此外,騰訊AI也有提供預訓練的中文詞向量模型,有興趣的朋友也能試試看
14.5. BERT
BERT就像詞向量模型一樣,需要大量的語料進行預訓練,好處是我們這種一般大眾可以直接使用一些科技巨擘所釋出的預訓練模型,像是Google, HuggingFace, 還有一些開源的github項目都有提供中文的BERT預訓練模型
15. NLP 應用
15.1. 領域
- 文字朗讀(Text to speech)/語音合成(Speech synthesis)
- 語音識別(Speech recognition)
- 中文自動分詞(Chinese word segmentation)
- 詞性標註(Part-of-speech tagging)
- 句法分析(Parsing)
- 自然語言生成(Natural language generation)
- 文字分類(Text categorization)
- 資訊檢索(Information retrieval)
- 資訊抽取(Information extraction)
- 文字校對(Text-proofing)
- 問答系統(Question answering)
- 機器翻譯(Machine translation)
- 自動摘要(Automatic summarization)
- 文字蘊涵(Textual entailment)
- 命名實體辨識(Named entity recognition)
15.2. 範例
- NLP 應用 1:TextClassification 文本分類
TextClassification 文本分類的意義
二元分類:分成好與惡
多元分類:分成不同類型的文章或喜好度
TextClassification 文本分類
IMDb-Movie-Review IMDb 網路電影影評資料集 Sentiment Analysis on IMDb
- Sentiment Analysis on IMDb: https://paperswithcode.com/sota/sentiment-analysis-on-imdb
- 情緒分析 sentiment analysis
Sentiment analysis (opinion mining or emotion AI)
https://en.wikipedia.org/wiki/Sentiment_analysis
很多線上社群網站會蒐集使用者的資料,並且分析使用者行為,
像是知名的 Facebook 在前幾年開始做「情緒分析(sentiment analysis)」,
情緒分析是以文字分析、自然語言處理 NLP 的方法,找出使用者的評價、情緒,進而預測出使用者行為來進行商業決策,
像這樣一連串利用情緒分析帶來的商業價值是相當可觀的。
- Sentiment Analysis on IMDb: https://paperswithcode.com/sota/sentiment-analysis-on-imdb
- NLP 應用 1:TextClassification 文本分類 技術主題
TF-IDF 與機器學習實現
https://blog.csdn.net/crazy_scott/article/details/80830399
使用 TensorFlow Estimators
https://ruder.io/text-classification-tensorflow-estimators/
使用 TF-IDF and ELMo
https://www.kaggle.com/saikumar587/imdb-text-classification-tf-idf-and-elmo
使用 BERT (2018)
Sentiment Analysis of IMDb Movie Reviews Using BERT
BERT Text Classification in 3 Lines of Code Using Keras
https://towardsdatascience.com/bert-text-classification-in-3-lines-of-code-using-keras-264db7e7a358
使用 XLNet(2019)
XLNet: Generalized Autoregressive Pretraining for Language Understanding
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le
(Submitted on 19 Jun 2019)
https://arxiv.org/abs/1906.08237
https://github.com/zihangdai/xlnet
範例程式
https://colab.research.google.com/github/zihangdai/xlnet/blob/master/notebooks/colab_imdb_gpu.ipynb
- NLP 應用 2:Text Generation 文本生成
TextGeneration 文本生成:作詞機器人
範例程式
參考資料
sudharsan13296/Hands-On-Deep-Learning-Algorithms-with-Python
https://github.com/sudharsan13296/Hands-On-Deep-Learning-Algorithms-with-Python
Hands-On-Deep-Learning-Algorithms-with-Python/
- Generating Song Lyrics Using RNN/4.06 Generating Song Lyrics Using RNN.ipynb
- Generating Song Lyrics Using RNN/4.06 Generating Song Lyrics Using RNN.ipynb
- NLP 應用 3: IMDB
- IMDB 正評負評
- 應用:PTT 裡的噓/推/→
- 中文斷詞
- 拿 google 的店家評論來判斷星級
- 應用:PTT 裡的噓/推/→
- 計算 Vector 的關聯性
- cos simility
- 但是 one-hot vector 間無法計算 cos simility,因為兩向量內積為 1,所以要用 word vector representation
- 在文字處理的狀況下,所謂兩個 vector 的相關指的是兩句話的相似性
- 用來自動生成考題(vocabulary testing)或生成答案,找人家 train 好的 word emgedding matrix 來做,生成 word vector
- 可以拿英文 train 好的 model 來做中文嗎?(transfer learning)
- cos simility
- Text Classification
tf.keras 技術者們必讀!深度學習攻略手冊 施威銘研究室 著 旗標科技 2020-02-13
1: import matplotlib.pyplot as plt 2: def plot(history_dict, keys, title=None, xyLabel=[], ylim=(), size=()): 3: lineType = ('-', '--', '.', ':') # 線條的樣式, 畫多條線時會依序採用 4: if len(ylim)==2: plt.ylim(*ylim) # 設定 y 軸最小值及最大值 5: if len(size)==2: plt.gcf().set_size_inches(*size) # size預設為 (6,4) 6: epochs = range(1, len(history_dict[keys[0]])+1) # 計算有幾週期的資料 7: for i in range(len(keys)): # 走訪每一個 key (例如 'loss' 或 'acc' 等) 8: plt.plot(epochs, history_dict[keys[i]], lineType[i]) # 畫出線條 9: if title: # 是否顯示標題欄 10: plt.title(title) 11: if len(xyLabel)==2: # 是否顯示 x, y 軸的說明文字 12: plt.xlabel(xyLabel[0]) 13: plt.ylabel(xyLabel[1]) 14: plt.legend(keys, loc='best') # 顯示圖例 (會以 key 為每條線的說明) 15: plt.show() # 顯示出畫好的圖 16: 17: 18: from tensorflow.keras.datasets import imdb #← 從 keras.datasets 套件中匯入 imdb 19: (a_train, b_train),(a_test, b_test)= imdb.load_data(num_words=10000) # 載入 IMDB 20: 21: from tensorflow.keras.preprocessing.text import Tokenizer 22: 23: tok = Tokenizer(num_words=10000) #←指定字典的總字數 24: x_train = tok.sequences_to_matrix(a_train) #←將訓練樣本做 k-hot 編碼 25: x_test = tok.sequences_to_matrix(a_test) #←將測試樣本做 k-hot 編碼 26: 27: y_train = b_train.astype('float32') #←將訓練標籤轉為浮點向量 28: y_test = b_test.astype('float32') #←將測試標籤轉為浮點向量 29: 30: from tensorflow.keras.models import Sequential 31: from tensorflow.keras.layers import Dense 32: 33: model = Sequential() #←建立模型物件 34: model.add(Dense(16, activation='relu', input_dim=10000)) #←輸入層 35: model.add(Dense(16, activation='relu')) #←隱藏層 36: model.add(Dense(1, activation='sigmoid')) #←輸出層 37: 38: # 中間用全連接層,其實也可以用CNN或RNN 39: model.compile(loss='binary_crossentropy', 40: optimizer='rmsprop', 41: metrics=['acc']) 42: 43: history = model.fit(x_train, y_train, 44: batch_size=512, #←每批次 512 筆樣本 45: epochs=10, #←共訓練 10 週期 46: verbose = 2, #←顯示精簡訊息 (無進度條) 47: validation_split=0.2) 48: #↑由訓練資料後面切出 20% 做為驗證用 49: 50: g1 = plot(history.history, 51: ('loss', 'val_loss'), #←歷史資料中的 key 52: 'Training & Validation Loss', #←線圖的標題 53: ('Epoch','Loss')) #←x,y 軸的名稱 54: plt.savefig() 55: plot(history.history, 56: ('acc', 'val_acc'), #←歷史資料中的 key 57: 'Training & Validation Acc', #←線圖的標題 58: ('Epoch','Acc')) #←x,y 軸的名稱
中間多塞幾層
1: import tensorflow as tf 2: import matplotlib.pyplot as plt 3: def plot(history_dict, keys, title=None, xyLabel=[], ylim=(), size=()): 4: lineType = ('-', '--', '.', ':') # 線條的樣式, 畫多條線時會依序採用 5: if len(ylim)==2: plt.ylim(*ylim) # 設定 y 軸最小值及最大值 6: if len(size)==2: plt.gcf().set_size_inches(*size) # size預設為 (6,4) 7: epochs = range(1, len(history_dict[keys[0]])+1) # 計算有幾週期的資料 8: for i in range(len(keys)): # 走訪每一個 key (例如 'loss' 或 'acc' 等) 9: plt.plot(epochs, history_dict[keys[i]], lineType[i]) # 畫出線條 10: if title: # 是否顯示標題欄 11: plt.title(title) 12: if len(xyLabel)==2: # 是否顯示 x, y 軸的說明文字 13: plt.xlabel(xyLabel[0]) 14: plt.ylabel(xyLabel[1]) 15: plt.legend(keys, loc='best') # 顯示圖例 (會以 key 為每條線的說明) 16: plt.show() # 顯示出畫好的圖 17: 18: 19: from tensorflow.keras.datasets import imdb #← 從 keras.datasets 套件中匯入 imdb 20: (a_train, b_train),(a_test, b_test)= imdb.load_data(num_words=10000) # 載入 IMDB 21: 22: from tensorflow.keras.preprocessing.text import Tokenizer 23: 24: tok = Tokenizer(num_words=10000) #←指定字典的總字數 25: x_train = tok.sequences_to_matrix(a_train) #←將訓練樣本做 k-hot 編碼 26: x_test = tok.sequences_to_matrix(a_test) #←將測試樣本做 k-hot 編碼 27: 28: y_train = b_train.astype('float32') #←將訓練標籤轉為浮點向量 29: y_test = b_test.astype('float32') #←將測試標籤轉為浮點向量 30: 31: from tensorflow.keras.models import Sequential 32: from tensorflow.keras.layers import Dense 33: from tensorflow.keras import layers 34: 35: model = Sequential() #←建立模型物件 36: model.add(Dense(16, activation='relu', input_dim=10000)) #←輸入層 37: model.add(Dense(16, activation='relu')) #←隱藏層 38: #加入第二層,該層的 output neurons 數目=64,啟動函式為預設 relu 39: #並對該層參數做 l1-regularization,其係數為 0.01 40: model.add(layers.Dense(64, kernel_regularizer=tf.keras.regularizers.l1(0.01))) 41: 42: #加入第三層,該層的 output neurons 數目=64,啟動函式為預設 relu 43: #並對該層參數做 l2-regularization,其係數為 0.01 44: model.add(layers.Dense(64, bias_regularizer=tf.keras.regularizers.l2(0.01))) 45: 46: #加入第四層,該層的 output neurons 數目=64,啟動函式為預設 relu 47: #該層參數初始化是用正交策略 48: model.add(layers.Dense(64, kernel_initializer='orthogonal')) 49: #加入第五層,該層的 output neurons 數目=64,啟動函式為預設 relu 50: #該層偏移初始化是用常數策略(皆設為2.0) 51: model.add(layers.Dense(64, bias_initializer=tf.keras.initializers.Constant(2.0))) 52: model.add(Dense(1, activation='sigmoid')) #←輸出層 53: 54: model.compile(loss='binary_crossentropy', 55: optimizer='rmsprop', 56: metrics=['acc']) 57: 58: history = model.fit(x_train, y_train, 59: batch_size=512, #←每批次 512 筆樣本 60: epochs=10, #←共訓練 10 週期 61: verbose = 2, #←顯示精簡訊息 (無進度條) 62: validation_split=0.2) 63: #↑由訓練資料後面切出 20% 做為驗證用 64: plt.clf() 65: plt.plot(history.history, 66: ('loss', 'val_loss'), #←歷史資料中的 key 67: 'Training & Validation Loss', #←線圖的標題 68: ('Epoch','Loss')) #←x,y 軸的名稱 69: 70: plt.savefig('images/plt2020-a.jpg', dpi=300) 71: plt.clf() 72: plt.plot(history.history, 73: ('acc', 'val_acc'), #←歷史資料中的 key 74: 'Training & Validation Acc', #←線圖的標題 75: ('Epoch','Acc')) #←x,y 軸的名稱 76: plt.savefig('images/plt2020-b.jpg', dpi=300) 77: 78: 79:
[[
 ]]
]]
[[ ]]
]]
- 多元分類:依據不同主題分類各種新聞
- 路透社新聞:共 47 類,答案部份用 one-hot
1: from tensorflow.keras.datasets import reuters # 匯入 reuters 資料集 2: 3: (a_train, b_train),(a_test, b_test) = reuters.load_data(num_words=10000) 4: 5: from tensorflow.keras.preprocessing.text import Tokenizer #←匯入 Tokenizer 類別 6: 7: tok = Tokenizer(num_words=10000) #←指定字典的總字數 8: x_train = tok.sequences_to_matrix(a_train) #←將訓練樣本做 multi-hot 編碼 9: x_test = tok.sequences_to_matrix(a_test) #←將測試樣本做 multi-hot 編碼 10: 11: from tensorflow.keras.utils import to_categorical 12: 13: y_train = to_categorical(b_train) #←將訓練標籤轉為 one-hot 編碼 14: y_test = to_categorical(b_test) #←將測試標籤轉為 one-hot 編碼 15: 16: from tensorflow.keras.models import Sequential 17: from tensorflow.keras.layers import Dense 18: 19: model = Sequential() 20: model.add(Dense(64, activation='relu', input_dim=10000)) 21: model.add(Dense(64, activation='relu')) 22: model.add(Dense(46, activation='softmax')) 23: 24: model.compile(loss='categorical_crossentropy', 25: optimizer='rmsprop', 26: metrics=['acc']) 27: 28: history = model.fit(x_train, y_train, 29: batch_size=512, 30: epochs=20, #← 訓練 20 個週期 31: verbose=2, #←顯示精簡訊息 (無進度條) 32: validation_split=0.2) #← 由訓練資料切出 20% 做驗證 33: 34: import util2 as u 35: u.plot(history.history, ('acc', 'val_acc'), #←繪製準確率的歷史線圖 36: 'Training & Validation Acc', ('Epoch','Acc')) 37: 38: loss, acc = model.evaluate(x_test, y_test, verbose=2) #←評估訓練成效 39: print('評估測試資料的準確率 =', acc) 40: 41: from tensorflow.keras.datasets import reuters # 匯入 reuters 資料集 42: 43: (a_train, b_train),(a_test, b_test) = reuters.load_data(num_words=10000) 44: 45: from tensorflow.keras.preprocessing.text import Tokenizer #←匯入 Tokenizer 類別 46: 47: tok = Tokenizer(num_words=10000) #←指定字典的總字數 48: x_train = tok.sequences_to_matrix(a_train) #←將訓練樣本做 multi-hot 編碼 49: x_test = tok.sequences_to_matrix(a_test) #←將測試樣本做 multi-hot 編碼 50: 51: from tensorflow.keras.utils import to_categorical 52: 53: y_train = to_categorical(b_train) #←將訓練標籤轉為 one-hot 編碼 54: y_test = to_categorical(b_test) #←將測試標籤轉為 one-hot 編碼 55: 56: from tensorflow.keras.models import Sequential 57: from tensorflow.keras.layers import Dense 58: 59: model = Sequential() 60: model.add(Dense(64, activation='relu', input_dim=10000)) 61: model.add(Dense(64, activation='relu')) 62: model.add(Dense(46, activation='softmax')) 63: 64: model.compile(loss='categorical_crossentropy', 65: optimizer='rmsprop', 66: metrics=['acc']) 67: 68: history = model.fit(x_train, y_train, 69: batch_size=512, # 每批次 512 筆樣本 70: epochs=10, # 只訓練 10 週期 71: verbose=0) # 不顯示訊息 72: 73: loss, acc = model.evaluate(x_test, y_test, verbose=2) #←評估訓練成效 74: print('評估測試資料的準確率 =', acc) 75: 76: from tensorflow.keras.datasets import reuters # 匯入 reuters 資料集 77: 78: (a_train, b_train),(a_test, b_test) = reuters.load_data(num_words=10000) 79: 80: from tensorflow.keras.preprocessing.text import Tokenizer #←匯入 Tokenizer 類別 81: 82: tok = Tokenizer(num_words=10000) #←指定字典的總字數 83: x_train = tok.sequences_to_matrix(a_train) #←將訓練樣本做 multi-hot 編碼 84: x_test = tok.sequences_to_matrix(a_test) #←將測試樣本做 multi-hot 編碼 85: 86: from tensorflow.keras.utils import to_categorical 87: 88: y_train = b_train #←直接使用載入的原始標籤 (已為 NumPy 向量) 89: y_test = b_test #←直接使用載入的原始標籤 (已為 NumPy 向量) 90: 91: from tensorflow.keras.models import Sequential 92: from tensorflow.keras.layers import Dense 93: 94: model = Sequential() 95: model.add(Dense(64, activation='relu', input_dim=10000)) 96: model.add(Dense(64, activation='relu')) 97: model.add(Dense(46, activation='softmax')) 98: 99: model.compile(loss='sparse_categorical_crossentropy', 100: optimizer='rmsprop', 101: metrics=['acc']) 102: 103: history = model.fit(x_train, y_train, 104: batch_size=512, # 每批次 512 筆樣本 105: epochs=10, # 只訓練 10 週期 106: verbose=0) # 不顯示訊息 107: 108: loss, acc = model.evaluate(x_test, y_test, verbose=2) #←評估訓練成效 109: print('評估測試資料的準確率 =', acc) 110: 111:
- 路透社新聞:共 47 類,答案部份用 one-hot
- IMDB 正評負評
16. 文本分類:IMDB 電影評論
https://www.tensorflow.org/tutorials/keras/text_classification
中文版
https://geektutu.com/post/tf2doc-ml-basic-text.html
https://blog.csdn.net/weixin_41753033/article/details/90815215
https://www.jishuwen.com/d/2O0H/zh-tw
資料集:網路電影資料庫(Internet Movie Database)
包含 50,000 條影評文本。
從該資料集切割出的 25,000 條評論用作訓練,
另外 25,000 條用作測試。
訓練集與測試集是*平衡的(balanced)*,意味著它們包含相等數量的積極和消極評論。
此範例評論文本
將影評分為*積極(positive)*或*消極(nagetive)*兩類。
這是一個二元(binary)分類問題,一種重要且應用廣泛的機器學習問題。
此範例使用 [tf.keras],它是一個 Tensorflow 中用於構建和訓練模型的高級 API。
1: import tensorflow as tf 2: from tensorflow import keras 3: 4: import numpy as np 5: print(tf.__version__) 6: 7: 8: imdb = keras.datasets.imdb 9: 10: (train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000) 11: 12: print("Training entries: {}, labels: {}".format(len(train_data), len(train_labels))) 13: 14: print(train_data[0]) 15: 16: len(train_data[0]), len(train_data[1]) 17: # 一個映射單詞到整數索引的詞典 18: word_index = imdb.get_word_index() 19: 20: # 保留第一個索引 21: word_index = {k:(v+3) for k,v in word_index.items()} 22: word_index["<PAD>"] = 0 23: word_index["<START>"] = 1 24: word_index["<UNK>"] = 2 # unknown 25: word_index["<UNUSED>"] = 3 26: 27: reverse_word_index = dict([(value, key) for (key, value) in word_index.items()]) 28: 29: def decode_review(text): 30: return ' '.join([reverse_word_index.get(i, '?') for i in text]) 31: 32: decode_review(train_data[0]) 33: 34: train_data = keras.preprocessing.sequence.pad_sequences(train_data, 35: value=word_index["<PAD>"], 36: padding='post', 37: maxlen=256) 38: 39: test_data = keras.preprocessing.sequence.pad_sequences(test_data, 40: value=word_index["<PAD>"], 41: padding='post', 42: maxlen=256) 43: 44: len(train_data[0]), len(train_data[1]) 45: 46: print(train_data[0]) 47: 48: # 構建模型 49: 50: vocab_size = 10000 51: 52: model = keras.Sequential() 53: model.add(keras.layers.Embedding(vocab_size, 16)) 54: model.add(keras.layers.GlobalAveragePooling1D()) 55: model.add(keras.layers.Dense(16, activation='relu')) 56: model.add(keras.layers.Dense(1, activation='sigmoid')) 57: 58: model.summary() 59: 60: # 配置模型 61: 62: model.compile(optimizer='adam', 63: loss='binary_crossentropy', 64: metrics=['accuracy']) 65: 66: # 建立驗證集 67: 68: x_val = train_data[:10000] 69: partial_x_train = train_data[10000:] 70: 71: y_val = train_labels[:10000] 72: partial_y_train = train_labels[10000:] 73: 74: # 訓練模型 75: 76: history = model.fit(partial_x_train, 77: partial_y_train, 78: epochs=40, 79: batch_size=512, 80: validation_data=(x_val, y_val), 81: verbose=1) 82: 83: # 建立 準確率(accuracy)和損失值(loss)隨時間變化的圖表 84: 85: history_dict = history.history 86: history_dict.keys() 87: 88: 89: import matplotlib.pyplot as plt 90: 91: acc = history_dict['accuracy'] 92: val_acc = history_dict['val_accuracy'] 93: loss = history_dict['loss'] 94: val_loss = history_dict['val_loss'] 95: 96: epochs = range(1, len(acc) + 1) 97: 98: plt.plot(epochs, loss, 'bo', label='Training loss') 99: plt.plot(epochs, val_loss, 'b', label='Validation loss') 100: plt.title('Training and validation loss') 101: plt.xlabel('Epochs') 102: plt.ylabel('Loss') 103: plt.legend() 104: 105: plt.show() 106: 107: plt.clf() # 清除數字 108: 109: plt.plot(epochs, acc, 'bo', label='Training acc') 110: plt.plot(epochs, val_acc, 'b', label='Validation acc') 111: plt.title('Training and validation accuracy') 112: plt.xlabel('Epochs') 113: plt.ylabel('Accuracy') 114: plt.legend() 115: 116: plt.show() 117:
17. 官方範例
17.1. 文本分類 Text classification::電影評論
https://www.tensorflow.org/tutorials/keras/text_classification
IMDB 資料集已經打包在 Tensorflow `tfds` 中。
該資料集已經經過預處理,
評論(單詞序列)已經被轉換為整數序列,其中每個整數表示字典中的特定單詞。
The IMDB movie reviews dataset comes packaged in `tfds`.
It has already been preprocessed so that the reviews (sequences of words) have been converted to sequences of integers,
where each integer represents a specific word in a dictionary.
The following code downloads the IMDB dataset to your machine (or uses a cached copy if you’ve already downloaded it):
To encode your own text see the [Loading text tutorial](../load_data/text.ipynb)
1: # -*- coding: utf-8 -*- 2: # 環境設定Setup 3: 4: 5: import tensorflow as tf 6: from tensorflow import keras 7: 8: import tensorflow_datasets as tfds 9: tfds.disable_progress_bar() 10: 11: import numpy as np 12: print(tf.__version__) 13: 14: # Download the IMDB dataset 下載 IMDB 資料集 15: (train_data, test_data), info = tfds.load( 16: # Use the version pre-encoded with an ~8k vocabulary. 17: 'imdb_reviews/subwords8k', 18: # Return the train/test datasets as a tuple. 19: split = (tfds.Split.TRAIN, tfds.Split.TEST), 20: # Return (example, label) pairs from the dataset (instead of a dictionary). 21: as_supervised=True, 22: # Also return the `info` structure. 23: with_info=True) 24: 25: # Try the encoder 26: 27: ### The dataset `info` includes the text encoder (a `tfds.features.text.SubwordTextEncoder`). 28: ### ### tfds.features.text.SubwordTextEncoder 29: ### https://www.tensorflow.org/datasets/api_docs/python/tfds/features/text/SubwordTextEncoder 30: 31: 32: encoder = info.features['text'].encoder 33: 34: print ('Vocabulary size: {}'.format(encoder.vocab_size)) 35: 36: """This text encoder will reversibly encode any string:""" 37: 38: sample_string = 'Hello TensorFlow.' 39: 40: encoded_string = encoder.encode(sample_string) 41: print ('Encoded string is {}'.format(encoded_string)) 42: 43: original_string = encoder.decode(encoded_string) 44: print ('The original string: "{}"'.format(original_string)) 45: 46: assert original_string == sample_string 47: 48: 49: ## The encoder encodes the string by breaking it into subwords or characters if the word is not in its dictionary. 50: ## So the more a string resembles the dataset, the shorter the encoded representation will be.""" 51: 52: for ts in encoded_string: 53: print ('{} ----> {}'.format(ts, encoder.decode([ts]))) 54: 55: # Explore the data 56: 57: ## The dataset comes preprocessed: each example is an array of integers representing the words of the movie review. 58: ## The text of reviews have been converted to integers, where each integer represents a specific word-piece in the dictionary. 59: ## Each label is an integer value of either 0 or 1, where 0 is a negative review, and 1 is a positive review. 60: 61: for train_example, train_label in train_data.take(1): 62: print('Encoded text:', train_example[:10].numpy()) 63: print('Label:', train_label.numpy()) 64: 65: ## The `info` structure contains the encoder/decoder. The encoder can be used to recover the original text:""" 66: 67: encoder.decode(train_example) 68: 69: # Data Pre-processing 70: ``` 71: ## Prepare the data for training 72: ## You will want to create batches of training data for your model. 73: ## The reviews are all different lengths, so use `padded_batch` to zero pad the sequences while batching: 74: 75: BUFFER_SIZE = 1000 76: 77: train_batches = ( 78: train_data 79: .shuffle(BUFFER_SIZE) 80: .padded_batch(32)) 81: 82: test_batches = ( 83: test_data 84: .padded_batch(32)) 85: 86: ## Each batch will have a shape of `(batch_size, sequence_length)` because the padding is dynamic each batch will have a different length:""" 87: 88: for example_batch, label_batch in train_batches.take(2): 89: print("Batch shape:", example_batch.shape) 90: print("label shape:", label_batch.shape) 91: 92: # 構建模型Build the model 93: 94: model = keras.Sequential([ 95: keras.layers.Embedding(encoder.vocab_size, 16), 96: keras.layers.GlobalAveragePooling1D(), 97: keras.layers.Dense(1)]) 98: 99: model.summary() 100: 101: # 配置模型 102: 103: model.compile(optimizer='adam', 104: loss=tf.losses.BinaryCrossentropy(from_logits=True), 105: metrics=['accuracy']) 106: 107: # 訓練模型Train the model 108: 109: history = model.fit(train_batches, 110: epochs=10, 111: validation_data=test_batches, 112: validation_steps=30) 113: 114: # 評估模型Evaluate the model 115: 116: loss, accuracy = model.evaluate(test_batches) 117: 118: print("Loss: ", loss) 119: print("Accuracy: ", accuracy) 120: 121: # 建立 準確率(accuracy)和損失值(loss)隨時間變化的圖表 122: 123: history_dict = history.history 124: history_dict.keys() 125: 126: import matplotlib.pyplot as plt 127: 128: acc = history_dict['accuracy'] 129: val_acc = history_dict['val_accuracy'] 130: loss = history_dict['loss'] 131: val_loss = history_dict['val_loss'] 132: 133: epochs = range(1, len(acc) + 1) 134: 135: # "bo" is for "blue dot" 136: plt.plot(epochs, loss, 'bo', label='Training loss') 137: # b is for "solid blue line" 138: plt.plot(epochs, val_loss, 'b', label='Validation loss') 139: plt.title('Training and validation loss') 140: plt.xlabel('Epochs') 141: plt.ylabel('Loss') 142: plt.legend() 143: 144: plt.show() 145: 146: plt.clf() # clear figure 147: 148: plt.plot(epochs, acc, 'bo', label='Training acc') 149: plt.plot(epochs, val_acc, 'b', label='Validation acc') 150: plt.title('Training and validation accuracy') 151: plt.xlabel('Epochs') 152: plt.ylabel('Accuracy') 153: plt.legend(loc='lower right') 154: 155: plt.show() 156: 157:
18. 練習
18.1. SPAM email detection 垃圾郵件偵測
- Linear & Tree-based models for Email Sentiment Classification
- https://www.kaggle.com/azunre/tl-for-nlp-section2-1-2-4-emails
18.2. fake News detection 假新聞偵測
- Using ELMo for “fake news” detection/classification
- https://www.kaggle.com/azunre/tl-for-nlp-sections4-2-4-4-fake-news-elmo
19. 教學資源
19.1. paper
- Deep Learning and NLP
Deep Learning for Source Code Modeling and Generation: Models, Applications and Challenges
Triet H. M. Le, Hao Chen, M. Ali Babar
https://arxiv.org/abs/2002.05442
Footnotes:
進入 NLP 世界的最佳橋樑:寫給所有人的自然語言處理與深度學習入門指南]]